CentOS7操作系统
文件目录类
Linux目录结构
linux的目录有且只有一个根目录 /
linux的各个目录存放的内容的规划好的, 不用乱放文件
linux是以文件的形式管理我们的设备, 因此linux系统, 一切皆为文件
linux的各个目录下存放什么内容, 大家必须有一个认识
学习后, 你的脑海里应该有一棵linux目录树
| 目录 | 功能 | 目录 | 功能 |
|---|---|---|---|
| / | 根目录系统的起点包含所有其他目录 | /opt | 可选的第三方软件 |
| /bin | 存放基本和系统级的可执行文件 | /proc | 虚拟文件系统提供系统信息 |
| /boot | 启动相关文件 | /root | root用户的主目录 |
| /dev | 设备文件 | /run | 运行时数据 |
| /etc | 系统配置文件 | /tmp | 临时文件 |
| /home | 用户的主目录 | /usr | 用户级应用程序和数据 |
| /lib | 共享库文件 | /var | 可变数据,如日志和缓存 |
| /mnt | 挂载点 |
/opt与/usr的区别
在 Linux 系统中,/opt 和 /usr 是两个重要的目录,但它们的作用和使用场景有显著的区别。以下是它们的详细对比:
1. /usr 目录
- 作用:
/usr(Unix System Resources)是 系统级软件资源 的标准存放目录,包含大多数用户应用程序和系统工具。- 由 系统包管理器(如
apt、yum、dnf)安装的软件通常会放在这里。 - 遵循 Filesystem Hierarchy Standard (FHS) 规范,结构严格,按文件类型分目录。
- 典型子目录:
/usr/bin:用户可执行文件(如ls、gcc)。/usr/lib:共享库文件(.so文件)。/usr/share:架构无关的共享数据(文档、图标、字体等)。/usr/include:头文件(用于开发)。/usr/local:用户手动编译安装的软件(与包管理器安装的软件隔离)。
- 特点:
- 系统级管理:由包管理器维护,更新或卸载软件时自动处理依赖。
- 标准化结构:文件按类型分散到不同子目录(如二进制文件、库文件分开存放)。
- 历史原因:早期 Unix 系统的核心目录,设计目标是共享、只读(可网络挂载)。
2. /opt 目录
- 作用:
/opt(Optional)用于安装 第三方独立软件包 或 非系统集成的应用程序。- 通常存放那些 不通过系统包管理器安装 的软件(如商业软件、自行编译的大型应用)。
- 每个软件在
/opt下有自己的独立子目录(如/opt/google/chrome)。
- 典型内容:
- 第三方软件(如 MATLAB、IntelliJ IDEA、Google Chrome)。
- 某些容器化工具(如早期 Docker 版本)或闭源软件。
- 特点:
- 独立存放:每个软件的所有文件(二进制、库、数据)集中在一个子目录中。
- 手动管理:安装和卸载通常需手动操作(如解压或运行安装脚本)。
- 避免污染系统路径:与系统软件隔离,减少依赖冲突风险。
3. 关键区别
| 对比项 | /usr |
/opt |
|---|---|---|
| 用途 | 系统级软件(包管理器安装) | 第三方独立软件(手动安装) |
| 结构 | 按文件类型分散到子目录 | 每个软件独占一个子目录 |
| 管理方式 | 包管理器自动管理 | 手动维护(需用户干预) |
| 遵循 FHS | 严格遵循 | 允许灵活结构 |
| 典型内容 | 系统工具、基础服务(如 gcc) |
商业软件、大型应用(如 IDEA) |
4. 使用场景建议
- **使用
/usr**:- 通过包管理器安装的软件(如
apt install nginx)。 - 需要系统级共享的库或工具(如开发工具链)。
- 通过包管理器安装的软件(如
- **使用
/opt**:- 手动安装的第三方软件(如下载
.tar.gz解压到/opt)。 - 希望独立管理、避免依赖冲突的软件(如多个版本共存)。
- 手动安装的第三方软件(如下载
5. 补充说明
/usr/local与/opt的区别:/usr/local用于 用户手动编译安装的软件,结构模仿/usr(如/usr/local/bin)。/opt更适用于 完全独立、自包含的软件包(所有文件集中在一个目录)。
- 环境变量:
- 安装在
/opt下的软件可能需要手动添加路径到PATH(如/opt/myapp/bin)。 /usr/bin默认在系统PATH中,无需额外配置。
- 安装在
总结
- 系统原生软件、包管理器安装的软件 →
/usr - 第三方独立软件、手动安装的大型应用 →
/opt
用什么权限安装软件
1. 安装到系统级目录(需 root 权限)
在 Linux 系统中,安装第三方软件时使用 root 用户还是普通用户取决于软件的安装位置、管理方式以及安全性需求。以下是详细分析和建议:
如果要将软件安装到系统级目录(如 /opt、/usr/local 或 /usr/bin),通常需要 root 权限,因为这些目录默认属于 root 用户,普通用户无权修改。
典型场景:
通过包管理器安装:例如
apt、yum、dnf等工具会修改系统目录,必须使用sudo。1
2sudo apt install nginx # Debian/Ubuntu
sudo dnf install docker # Fedora/CentOS**手动安装到
/opt或/usr/local**:1
2
3
4
5
6
7# 示例:将软件包解压到 /opt
sudo tar -xzf myapp.tar.gz -C /opt
# 示例:编译安装到 /usr/local
./configure --prefix=/usr/local
make
sudo make install
特点:
- 系统级共享:所有用户均可使用安装的软件。
- 依赖集中管理:库文件、配置文件等集中存放,便于系统维护。
- 风险提示:使用
root权限需谨慎,避免安装不可信来源的软件。
2. 安装到用户目录(无需 root 权限)
如果软件支持安装到用户主目录(如 ~/apps、~/.local 或 ~/bin),则可以使用普通用户权限,无需 sudo。
典型场景:
独立软件包:如 Python 的
pip install --user、Node.js 的npm install -g(配合用户目录)。1
2
3
4
5
6
7
8
9
10# 安装 Python 包到用户目录 ~/.local
pip install --user requests
# 安装 Node.js 全局工具到用户目录
```bash
npm install -g typescript --prefix ~/.npm-global
- **手动解压到主目录**:
# 将软件包解压到用户目录
tar -xzf myapp.tar.gz -C ~/apps
特点:
- 用户隔离:软件仅对当前用户可用,避免影响其他用户。
- 无需管理员权限:适合没有
sudo权限的场景(如共享服务器)。 - 灵活性高:可自由管理版本或卸载,不污染系统目录。
3. 选择 root 还是普通用户?
| 场景 | 推荐方式 | 示例 |
|---|---|---|
| 通过包管理器安装系统工具 | sudo + root 权限 |
sudo apt install vim |
手动安装到 /opt 或系统目录 |
sudo + root 权限 |
sudo ./install.sh |
| 开发工具链或全局服务(如 Docker) | sudo + root 权限 |
sudo snap install docker |
| 用户级应用(如 Python 包) | 普通用户权限 | pip install --user pandas |
| 测试或临时使用 | 普通用户权限(用户目录) | ./myapp --install-dir ~/apps |
4. 安全性建议
- 最小权限原则:尽量使用普通用户权限安装,仅在必要时使用
sudo。 - 验证软件来源:确保第三方软件来自可信渠道,避免提权操作引入恶意代码。
- 隔离环境:对开发或测试场景,优先使用容器(Docker)或虚拟环境(Python venv、Node.js nvm)。
5. 常见问题解决
权限被拒绝(Permission Denied)
- 问题:尝试安装到系统目录时提示权限不足。
- 解决:使用
sudo提升权限,或更换安装目录到用户主目录。
安装后命令未找到(Command Not Found)
问题:安装到用户目录的软件无法直接运行。
解决:将用户目录的
bin路径添加到PATH环境变量:1
2
3# 例如,将 ~/.local/bin 添加到 PATH
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
总结
- 需要系统级安装 → 使用
sudo或 root 用户(如/opt、/usr/local)。 - 仅限当前用户使用 → 普通用户权限安装到主目录。
- 优先选择安全的方式:避免滥用
root,尽量隔离用户级应用。
| 命令 | 说明 |
|---|---|
| shutdown –h now | 立该进行关机 |
| shutdown -h 1 | “hello, 1 分钟后会关机了” |
| shutdown –r now | 现在重新启动计算机 |
| halt f | 关机命令 |
| reboot | 现在重新启动计算机 |
| sync | 把内存的数据同步到磁盘. |
| init 0 | 立该进行关机 |
| init 6 | 现在重新启动计算机 |
| init 1 | 单用户模式。仅启动最基本的系统服务(无网络、无多用户登录),通常用于系统修复(如密码找回、文件系统检查等),无需输入密码即可登录 root 账户。 |
| init 2 | 多用户模式。启动多用户环境,但不加载网络文件系统(NFS)服务,部分发行版中可能与init 3功能接近(需结合具体系统配置)。 |
| init 3 | 完全多用户模式(文本界面)。启动完整的多用户环境,支持网络服务,但默认进入文本命令行界面(无图形桌面)。 |
| init 5 | 多用户模式(图形界面)。在init 3的基础上,额外启动图形桌面环境(如 GNOME、KDE 等),默认进入图形登录界面。 |
cd 切换到指定目录
1 | cd ~ 或者cd 回到自己的家目录 |
pwd 现在所在的目录位置
ls查看内容
1 | ls -a all,显示全部包括隐藏文件(隐藏文件以.开头) |
mkdir 创建目录
1 | mkdir a 创建一个目录 mkdir b c 同时创建多个目录 |
touch 创建空文件
1 | touch name.txt |
##rm 删除文件或目录
1 | 可以删除一个目录中的一个或多个文件或目录及其下属的所有文件及其子目录均删除掉; |
mv 移动文件和目录, 或者重命名
1 | mv a b |
cp 拷贝文件到指定目录
1 | cp -r 递归拷贝目录(复制包括所有子文件,必须使用) |
ln 软连接,类似win快捷方式
什么是软连接?
软连接是Linux系统上的另一个文件或目录。
这和 Windows 系统中的快捷方式有点类似,链接文件中记录的只是原始文件的路径,并不记录原始文件的内容。
例子
1 | cd /home/test |
什么是硬链接?
硬链接是原始文件的一个镜像副本。创建硬链接后,如果把原始文件删除,链接文件也不会受到影响,因为此时原始文件和链接文件互为镜像副本。
vim 编辑文件
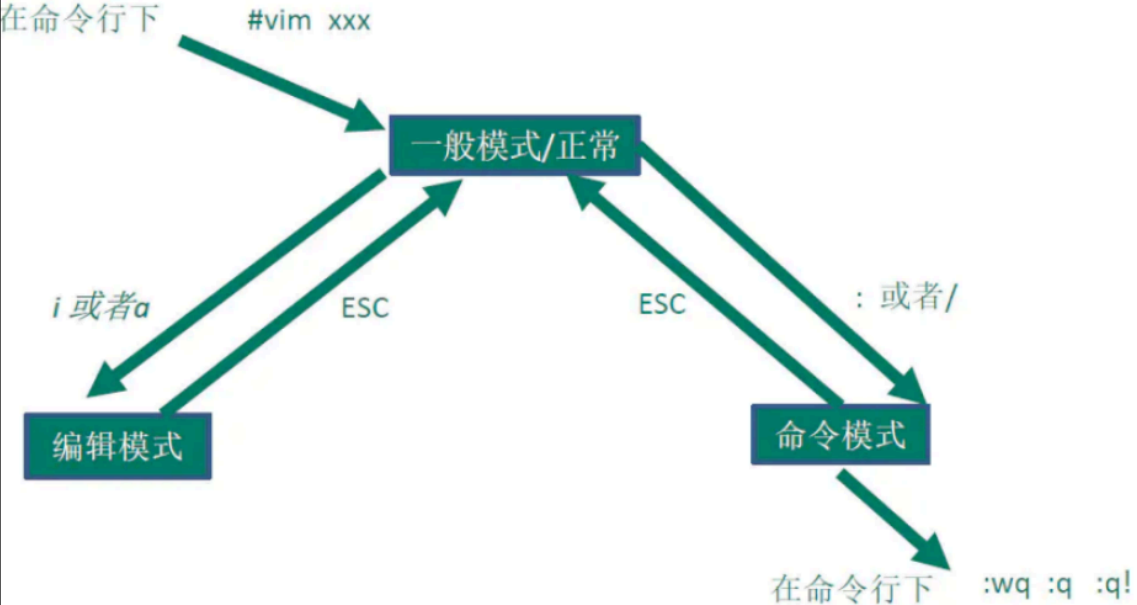
进入一般模式后,可在键盘输入,实现删除、复制、粘贴。
1 | dd 删除光标所在的行,且保存到剪贴板 |
命令行模式
1 | q 不保存退出 后面加!为强制退出 |
查找:
(以下直接输入/)
/hello 查找字符串,按n向下搜索,按N向上搜索
替换字符串
替换字符串命令的基本语法是 :[range]s/⽬标字符串/替换字符串/[option],其中range和option字段都可以缺省不填,间隔符除了/还可以是其他的。
range:表⽰搜索范围,默认表⽰当前⾏; 1,10表⽰从第1到第10⾏;
g 表示全局替换,有多少次替换多少次;无g 只替代每行第一个
s 表示替换
例子:
1 | :1,$s/nologin/88888/g |
搜索查看查找类
find 从指定目录查找文件
1 | -name <查询方式> 按照指定的文件名查找模式查找文件 |
-exec 只能搭配find使用
例子:
1 | find /root -name "*.pdf" |
head与tail查看行
1 | head -n 文件名 (不加默认开头十行) |
cat查看内容
1 | cat(英文全拼:concatenate)命令用于连接文件并打印到标准输出设备上。 |
more查看大内容
more 分屏查看文件(敲空格查看下一页)
grep过滤查找
1 | 以行为单位进行查找,显示结果为满足的行 |
history 查看已经执行过的历史命令
history
history 5 最近五个命令
wc统计文件
查看文件的字节数 wc -c t2.txt
查看文件的行数 wc -l t2.txt
du查看空间
du -h 人性化方式(带单位)
du -s 只统计每个参数所占用空间总的大小
du -sh /etc
管道符号 | 配合命令使用
管道符 | 表示将前一个命令的处理结果输出传递给后面的命令处理
1 | ls -l | grep -c "^d" |
> 和 >> 指令
> 输出重定向(覆盖写), >> 追加(追加写)
示例:
1 | cat a.txt b.txt >> ttt.txt |
输入重定向操作符”<”
在 Shell 编程中,< 符号是 输入重定向操作符,它的核心作用是将某个文件或数据流的内容作为命令的标准输入(stdin)。以下是详细解析:
一、基本作用
将文件内容作为命令的输入:
1 | command < filename |
示例:
1
2cat < file.txt # 将 file.txt 的内容传递给 cat 命令(效果等同于 cat file.txt)
wc -l < data.log # 统计 data.log 的行数
此时,< 会打开文件 filename,并将其内容重定向到 command 的标准输入中。
二、常见使用场景
1. 替代管道符的输入
当命令需要从文件而非键盘获取输入时:
1 | # 将文件内容传递给需要 stdin 的命令 |
2. Here Document(文档内输入)
使用 << 结合 < 定义多行输入块:
1 | command << EOF |
示例:
1
2
3
4cat << EOF
Hello
World
EOF输出:
1
2Hello
World
3. Here String(字符串输入)
使用 <<< 直接传递字符串:
1 | command <<< "string" |
示例:
1
tr 'a-z' 'A-Z' <<< "hello" # 输出 HELLO
三、与其他符号的区别
| 符号 | 作用 | 示例 |
|---|---|---|
< |
输入重定向(从文件读取) | sort < input.txt |
> |
输出重定向(覆盖写入文件) | ls > file_list.txt |
>> |
输出重定向(追加到文件) | echo "new" >> log.txt |
| ` | ` | 管道符(传递前一个命令的输出)cat file.txt grep "key" |
四、注意事项
文件必须存在:
1
command < non_existent_file # 报错:No such file or directory
与命令参数的优先级:
- 如果命令本身接受文件名参数(如
cat file.txt),直接传参比<更高效,因为<需要额外打开文件。
- 如果命令本身接受文件名参数(如
输入重定向和管道的区别:
1
2cat file.txt | command # 管道符传递的是 cat 的输出
command < file.txt # 直接传递文件内容到 command 的 stdin
五、总结
< 是 Shell 中 输入方向的重定向符号,用于将文件或数据流的内容传递给命令的标准输入。熟练掌握输入/输出重定向,是 Shell 脚本高效处理文件和数据流的核心技能!
压缩安装类
zip unzip 压缩解压
1 | \# 压缩文件和目录 |
常用选项
-r:递归压缩,即压缩目录
-d<目录> :指定解压后文件的存放目录
zip test.zip -r a/b 注:绝对路径压缩会带前面的路径文件夹
unzip linux.x64_11gR2_database_1of2.zip -d /opt/app/database/
压缩的时候用相对路径
解压的时候用绝对路径
tar 压缩解压
1 | -z 调用 gzip 程序进行压缩或解压 |
压缩:tar [选项] … 归档文件名(压缩包名字) 源文件或目录
解压:tar [选项] … 归档文件名 [-C 目标目录]
1 | tar -zcvf abc123.tar.gz abc.txt 123.txt 压缩成abc123.tar.gz的命令 |
Yum包管理
Yum是一个Shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载
RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包。
1 | 查询yum服务器是否有需要安装的软件 yum list | grep xxx |
用户权限类
基本介绍
登录时尽量少用root帐号登录,因为它是系统管理员,最大的权限,避免操作失误。可
以利用普通用户登录,登录后再用 su - 用户名 命令来切换
用户及用户组
1 | 类似于角色,系统可以对有共性的多个用户进行统一的管理。 |
用户和组的相关文件
/etc/passwd 文件
用户(user)的配置文件,记录用户的各种信息
每行的含义:用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell
/etc/group 文件
组(group)的配置文件,记录Linux包含的组的信息
每行含义:组名:口令:组标识号:组内用户列表
rwx权限详解
[ r ]代表可读(read): 可以读取
[ w ]代表可写(write): 可以修改
[ x ]代表可执行(execute):可以被执行
10个字符确定不同用户能对文件干什么
第一个字符代表文件类型:文件( - ),目录( d ),链接( l )
第一组 rwx : 文件拥有者的权限是读、写和执行
第二组 rw- : 与文件拥有者同一组的用户的权限是读、写但不能执行
第三组 r– : 不与文件拥有者同组的其他用户的权限是读不能写和执行
可用数字表示为: r=4,w=2,x=1
因此 rwx=4+2+1=7
chmod 修改权限
通过 chmod 指令,可修改文件或目录的权限
-R表示递归里面的所有文件及目录
**+、-、= 变更权限
1 | u:所有者 g:所有组 o:其他人 a:所有人(u、g、o的总和) |
例子:
1 | chmod u+x file 给file的属主增加执行权限 |
chown 修改文件所有者
1 | chown [-R] 所有者 文件或目录 |
/usr/local 小文件,小软件的安装
mysql 端口默认3306
oracle 端口默认1521
网络配置类
1 | clear 清屏 ifconfig 列出网卡信息 ping ip地址 看网络是不是连通 |
top命令
1. 进程列表区字段含义
默认显示的进程字段如下(可通过快捷键自定义显示内容):
| 字段 | 含义 |
|---|---|
PID |
进程 ID(唯一标识,用于杀死进程等操作) |
USER |
进程所属用户 |
PR |
进程优先级(数值越小,优先级越高) |
NI |
nice 值(优先级调整值,范围 -20~19,默认 0) |
VIRT |
进程使用的虚拟内存总量(包括未使用的 swap 空间) |
RES |
进程使用的物理内存(不包括 swap,单位 KiB) |
SHR |
进程共享的内存量(包括与其他进程共享的部分) |
S |
进程状态(R:运行;S:休眠;T:停止;Z:僵尸;D:不可中断休眠) |
%CPU |
进程占用 CPU 的百分比(自上次刷新以来) |
%MEM |
进程占用物理内存的百分比 |
TIME+ |
进程累计使用的 CPU 时间 |
COMMAND |
进程启动命令(可能被截断,可通过 -c 参数显示完整命令) |
2.常用快捷键(在 top 界面中使用)
- 排序相关:
P:按%CPU使用率从高到低排序(默认)M:按%MEM使用率从高到低排序N:按PID从小到大排序T:按TIME+(累计 CPU 时间)从高到低排序。
- 刷新频率:
s:修改刷新间隔时间(输入数字后回车,单位秒,默认 3 秒)。
- 筛选与查找:
u:输入用户名,只显示该用户的进程k:输入 PID 并回车,再输入信号(如 9 代表强制终止),可杀死指定进程f:进入字段选择界面,按方向键选择字段,按空格键勾选 / 取消,回车返回(自定义显示哪些字段)o:进入排序条件设置,按字段首字母设置排序规则(如输入%MEM按内存排序)/:输入关键词,搜索进程命令(按n切换下一个结果)。
- 其他操作:
H:显示 / 隐藏线程(默认只显示进程,开启后显示线程)c:切换显示完整命令 / 命令名(默认显示命令名,开启后显示完整路径)i:忽略闲置进程(只显示正在运行的进程)q:退出 top 界面。
3. 常用命令参数(启动 top 时使用)
top -d N:指定刷新间隔为 N 秒(如top -d 5每 5 秒刷新一次)top -p PID1,PID2:只监控指定 PID 的进程(如top -p 123,456)top -u 用户名:只显示指定用户的进程(如top -u root)top -c:启动时直接显示完整命令(无需按c切换)top -b:批处理模式(非交互式,可用于输出到文件,如top -b -n 1 > top.log保存一次快照)top -n N:刷新 N 次后自动退出(结合-b使用,如top -b -n 3刷新 3 次后退出)。
4. 示例场景
- 查看系统中 CPU 占用最高的进程:
输入top后按P,顶部进程即为 CPU 消耗最高的进程。 - 杀死一个占用内存过高的进程:
找到该进程的PID,按k,输入 PID,再输入9并回车(强制终止)。 - 监控特定用户(如 www)的进程:
方法 1:启动时使用top -u www
方法 2:在 top 界面按u,输入www回车。 - 将进程快照保存到文件:
top -b -n 1 -c > process_snapshot.log(保存一次完整命令的进程快照)。
通过熟练使用 top 命令,可快速定位系统资源瓶颈(如 CPU 过高、内存泄漏等),是 Linux 系统管理的必备技能。
ps 显示系统执行的进程
1 | ps -aux 查看所有用户所有进程 |
pstree 查看进程树
pstree 1660 # 树状的形式显示进程的pid
kill
最常用的信号是:
1 | 1 (HUP):重新加载进程。 |
systemctl 服务管理
1 | systemctl [ start | stop | restart | status] 服务名 |
注:直接关死即可,单机版使用防火墙
防火墙
一、防火墙的开启、关闭、禁用命令
设置开机启用防火墙:
1
systemctl enable firewalld
设置开机禁用防火墙:
1
systemctl disable firewalld
启动防火墙:
1
systemctl start firewalld
关闭防火墙:
1 | systemctl stop firewalld 或 systemctl stop firewalld.service |
检查防火墙状态
1
systemctl status firewalld
二、使用firewall-cmd配置端口
查看防火墙状态:
1
firewall-cmd --state
重新加载配置:
1
firewall-cmd --reload
查看开放的端口:
1
firewall-cmd --list-ports
开启防火墙端口:
1
firewall-cmd --zone=public --add-port=9200/tcp --permanent
命令含义:
–zone #=作用域=pubic
–add-port=9200/tcp #添加端口,格式为:端口/通讯协议
–permanent #永久生效,没有此参数重启后失效
注意:添加端口后,必须用命令firewall-cmd –reload重新加载一遍才会生效
关闭防火墙端口:
1
firewall-cmd --zone=public --remove-port=9200/tcp --permanent
常用命令
1.版本信息
1 | [root@localhost]# cat /etc/os-release |
配置静态ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33 网卡配置文件
重启网络 service network restart
netstat 端口
netstat -nltp 查看网络
oracle监听
lsnrctl (status 状态 start 启动 stop 停止)
其他扩展类
echo输出字符串
1 | 换行打印输入字符 解释 |
date显示当前日期 (用于日期转字符串)
1 | date (显示当前时间) |
date -d 日期解析(用于字符串转日期)
1 | date -d "2009-12-12" |
date 设置日期
1 | date -s 字符串时间 |
linux网络对时
1 | 1.安装netdate |
cal查看日历
1 | cal [[[日] 月] 年] |
显示当前日历 cal
显示2023年日历 cal 2023
显示2023年1月日历 cal 01 2023
显示2023年1月15日日历 cal 15 01 2023
wget命令
用来从指定的URL下载文件。
python下载地址:https://www.python.org/ftp/python
1 | wget https://www.python.org/ftp/python/3.9.0/Python-3.9.0.tar.xz |
seq命令
用于产生从某个数到另外一个数之间的所有整数。
- seq [选项]… 尾数
- seq [选项]… 首数 尾数
- seq [选项]… 首数 增量 尾数
正序输出:
1 | seq 1 10 |
倒序输出:
1 | seq 100 -1 1 |
Linux 定时执行计划
方式一:修改配置文件:/etc/crontab (要指明执行用户)
1 | 分 时 日 月 周 用户名 执行的命令 |
方式二:通过crontab命令(不需要指明执行用户,默认就是当前用户)
crontab -e 注:编辑用户的cron配置文件;
crontab -l 注:查看用户的计划任务;
crontab -r 注:删除用户的计划任务;
1 | 5 * * * * date > /root/time.txt |
特殊符号说明
| 符号 | 含义 |
|---|---|
| * | 任何时间。比如第一个 * 就代表一小时中每分钟都执行一次的意思。 |
| , | 不连续的时间。比如 0 8,12,16 * * * ,在每天的8点0分,12点0分,16点0分都执行一次命令 |
| - | 连续的时间范围。比如 0 5 * * 1-6 ,在周一到六凌晨5点0分执行命令 |
| */n | 每隔多久执行一次。比如 */10 * * * * ,每隔10分钟就执行一遍命令 |
1 | date +"\%Y" > /root/time.txt # 注:定时任务中的特殊符号需要转义% |
分区及挂载
fdisk
1 | fdisk -l 可以查看系统所有硬盘的分区情况 |
df
用于显示 Linux 系统中各文件系统的硬盘使用情况,包括文件系统所在硬盘分区的总容量、已使用的容量、剩余容量等。
1 | df -h 查看磁盘使用及挂载情况 |
linux添加硬盘分区挂载
1 | 1.关闭虚拟机添加硬盘:虚拟机-设置-添加-硬盘-1G-单个文件存储-打开虚拟机 |
shell
系统变量
1 | $HOME :当前登录用户的 "家目录" 路径 |
自定义变量
变量名=值;常量:readonly
1 | xm="你好" |
在shell编程中,``(反引号)的主要作用是命令替换。具体来说,反引号会将其中的命令执行,并将输出结果赋值给变量。
##特殊变量
1 | 特殊变量 |
read 读取终端输入
-p:指定读取值时的提示符;
-t:指定读取值时等待的时间(秒)。
read -p “请输入密码:” s
read -p “请输入密码:” -t 10 mima
运算符
赋值运算符 =
算数运算符 + - * / %
比较运算符
字符串比较: == !=
数值比较:-eq 等于 -ne 不等于 -lt 小于 -le 小于等于 -gt 大于 -ge 大于等于
类型权限:-f 存在且是文件 -d 存在且是目录-r 读 (read) -w 写(write) -x 执行 (execute)
逻辑运算符 -a -o !
算数运算符
$((运算式)) 或 $[运算式]
**+, - , , /, % 加,减,乘,除,取余*
1 | echo 3 + 4 |
选择结构
改变程序的执行顺序
选择一个结果
条件为bool类型,只能选择一个执行,
if和case两种
if结构,if、 if else、多重if
可以随意嵌套,两种方法都可以互相实现,选择更适合的方法实现
if 选择结构 —then 独立一行
[ ] 必须用空格隔开条件判断。
1 | if [ 条件判断 ] |
case语句 等值判断
1 | case $变量名 in |
1 | # if结构 |
1 | # case结构 |
1 | # 多条件应用 |
for 循环
循环语句
循环具备的两个条件:循环条件和循环操作
条件为bool类型,plsql的循环能够让一段代码反复执行,为实现这一功能一共提供了三
种不同的循环结构:
loop简单循环或无限循环,其他语言叫do while
for循环
while循环
循环结构
三种循环各有差异但每个结构都包含两个部分:循环边界以及循环体。循环边界有一些
保留词组成,包括初始化循环、终止循环条件、完成循环的 end loop 语句。
循环结构和选择结构随意嵌套,同一功能可以互相实现,选择合适的方法
WHILE循环
while循环时一个条件循环,只要循环边界处定义的布尔条件的值为真,循环就会继续。
while循环的特性:
| 属性 | 描述 |
|---|---|
| 循环结束语句 | 当循环边界的布尔表达式为false 或者null时循环结束。 |
| 结束循环语句位置 | 结束循环语句放在while关键字后,在循环体要执行前进行判断,所以while循环可能一次都不会执行循环体。 |
| while循环使用场景 | 无法明确循环体会循环几次,但有明确的循环停止条件,并且循环体不是一定要执行的情况使用 while循环。 |
for循环
for循环的特性
| 属性 | 描述 |
|---|---|
| 循环结束语句 | for循环达到范围区间的循环次数就结束,或者在循环体中使用exit等语句停止。 |
| 结束循环语句位置 | 每次循环体执行后,程序自动递增循环索引的值,直到超过区间范围后停止循环。 |
| while循环使用场景 | 有明确循环次数,并不提前结束循环的情况使用for循环。 |
for i in 集合
1 | \# 序列 |
1 | # 字符串 |
while 循环
while [ 条件判断 ]
1 | i=1 |
乘法表(双层嵌套)
1 | for i in `seq 1 9` |
循环控制
1 | break |
二重循环
循环里面嵌套循环,外层循环先开始,内层循环结束后,再开始外层的下一个循环:
1 | for i in `seq 1 5` |
自定义函数
1 | name(){ |
因为shell脚本是从上到下逐行运行,不会像其它语言一样先编译,所以函数必须在调用之前,先声明。
函数返回值,return后只能跟数值n(0-255)
接收返回值方法:在函数内部使用 echo命令将结果输出,在函数外部使用$()或者``捕获结果。
1 | # 无输入无返回 |
###可以输入参数
1 | read -p "请输入第一个数:" n1 |
可以互相调用
1 | he(){ |
递归自己调用自己
# 输入一个目录显示里面的所有目录
1 | fun(){ |
Shell工具
sort
sort命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出。
| 选项 | 说明 |
|---|---|
| -n | 依照数值的大小排序 |
| -r | 以相反的顺序来排序 |
| -t | 设置排序时所用的分隔字符 |
| -k | 指定需要排序的列 |
参数:指定待排序的文件列表
shell下面建立如下文件sort.txt
1 | bb:40:5.4 |
按照“:”分割后的第三列倒序排序。
1 | sort -t ":" -nrk 3 /root/shell/sort.txt |
grep 、sed、awk被称为linux中的三剑客。
我们总结一下这三个”剑客”的特长。
grep 更适合单纯的查找或匹配文本
sed 更适合编辑匹配到的文本
- awk 更适合格式化文本,对文本进行较复杂格式处理
sed
sed: stream editor(流编辑器)的简称。
它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中(“模式空间“),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。
p 打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
i 插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
a 新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)
s 取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!
1 | 1.显示文件的第 2 行的内容: |
awk
一个完整的awk命令形式如下:
1 | awk [options] 'BEGIN{ commands } { commands } END{ commands }' file |
-v 指定 FS 和 OFS 字段分隔符和输出字段分隔符
内置参数:
NF 分割完字段的数量
$1 代表文本行中的第 1 个数据字段;
$2 代表文本行中的第 2 个数据字段;
输出指定列:{print $1,$2}
分隔符相同的情况输出一整行:{print}
1 | 1.以:为分隔符,打印第2列和第1列 |
内置变量
FS
输入字段分隔符,默认空格或制表符。
示例:1
awk 'BEGIN{FS=":"} {print $1}' /etc/passwd # 等价于 `-F:`:cite[3]:cite[7]。
OFS
输出字段分隔符,默认空格。
示例:1
awk 'BEGIN{OFS="|"} {print $1, $2}' data.txt # 输出字段以 `|` 分隔:cite[3]:cite[7]。
RS和ORSRS:输入记录分隔符(默认换行符)。1
awk 'BEGIN{RS=";"} {print $0}' data.txt # 以分号分隔记录:cite[3]:cite[7]。
ORS:输出记录分隔符(默认换行符)。1
awk 'BEGIN{ORS=";"} {print $0}' data.txt # 输出以分号结尾:cite[3]:cite[7]。
NR和FNRNR:全局行号(跨文件累计)。FNR:当前文件行号(每个文件从1开始)。
示例:
1
awk '{print NR, FNR, $0}' file1.txt file2.txt # 显示全局和文件行号:cite[3]:cite[7]。
NF
当前行的字段数。
示例:1
awk '{print NF, $NF}' data.txt # 打印字段数和最后一个字段:cite[3]:cite[7]。
mysqldump命令
1 | 1.导出education数据库里面的users表的表数据和表结构(下面以users表为例) |
上机练习17
实现每天凌晨3点10分备份数据库test到/root/backup/,db
一、编写shell脚本为root/shell/backdb.sh
- 判断路径root/backup/db是否存在,不存在创建,存在开始备份
- 备份后的文件以时间命名,如20230401110101.sal
- 在备份的同时,检查是否有10天前的备份数据库文件,有则删除之
二、编写定时任务,任务是执行上面的she脚本
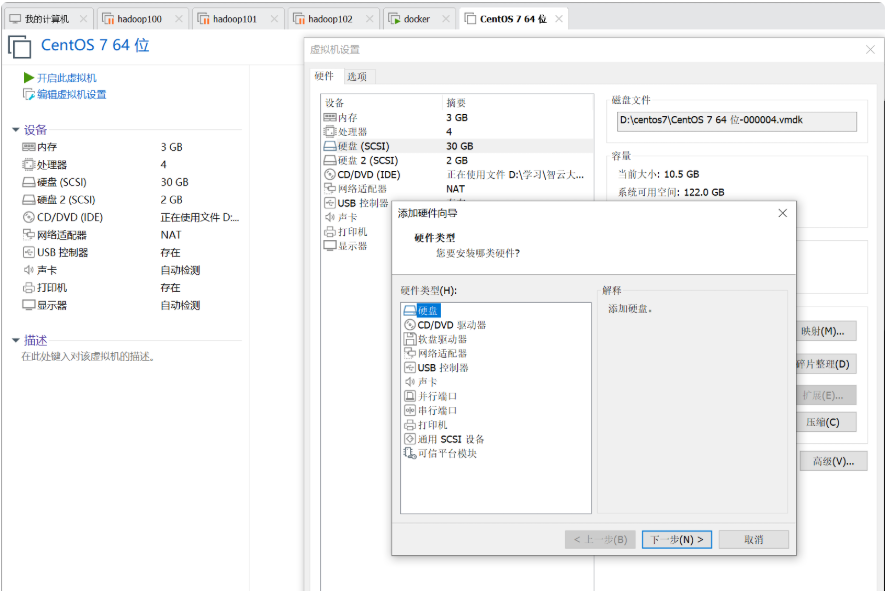
Linux根目录扩容
第一步:先关机
第二步:添加硬盘-SCSI-创建新虚拟磁盘-设置需要添加的磁盘大小(写作最大磁盘大小)(10G)(存储为单个文件)-下一步-完成
1 | # 查看当前磁盘占用情况 |