
Python
国内常用镜像源
1 | 清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/ |
数据类型
数字型: bool int float
⾮数字型: str list tuple set dict
⽇期型: time datetime
例子:
1 | sno=1 |
1 | f'{value}'格式化输出 |
输⼊
使⽤ input 函数来接收⽤⼾从键盘输⼊ ,input 输⼊的内容是字符串型
passwd=input(“ 请输⼊密码: “) print(type(passwd)) 我们使⽤ int() 、 float() 、 str() 等转换。
运算符
- 算数: + - * / %( 取余 ) **( 幂 ) //( 取商 )
- ⽐较: == != > >= < <=
- 赋值: = += -= *= /= **= //=
- 逻辑: and or not
流程控制
选择结构 if
1 | sex="女" |
循环结构 while 和 for
1 | # 循环输出1-10数字 |
字符串 (String)
- 拼接 * 复制 “”” 保留格式
- 字符串的索引截取,变量名 [ 头下标 : 尾下标 ]
- 索引值以 0 为开始值,-1 为从末尾的开始位置。
1 | #索引切片 |
| 字符串函数 | 含义 |
|---|---|
| len(str) | 获取字符串长度 |
| str.find(‘str’,int1,int2) | 字符查找 ,找到返回索引,没找到返回-1.。int1,int2分别代表开始索引和结束索引 |
| str.rfind() | 代表从右侧开始查找 |
| str.isdigit() | 所有字符都是数字 |
| str.count() | 统计字符串里某个字符或子字符串出现的次数 |
Python 中的字符 ASCII 码运算
ASCII码表
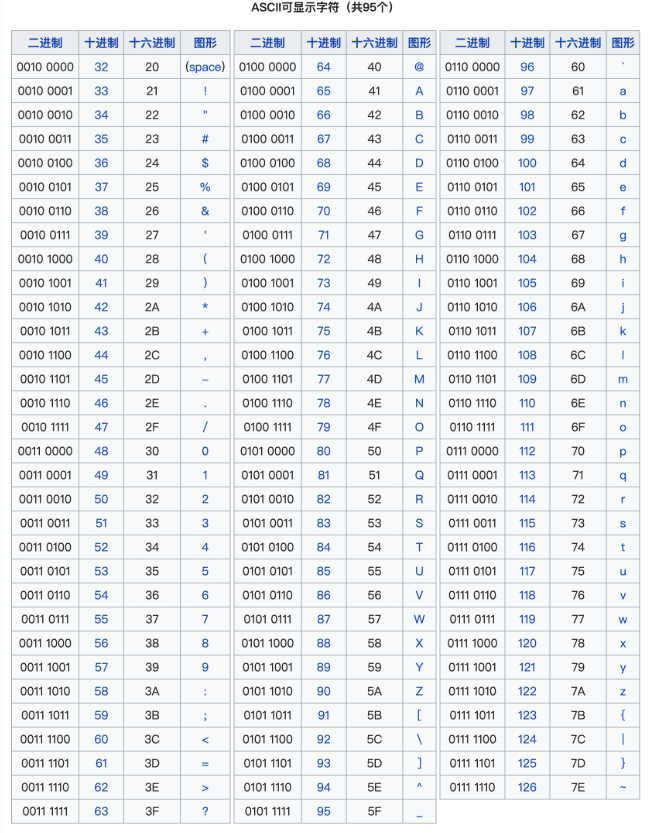
在 Python 中,字符的 ASCII 码运算可以通过 ord() 和 chr() 函数实现,允许你对字符进行数值操作。以下是详细解释和示例:
核心函数
ord(char)- 获取字符的 ASCII 码值1
2
3print(ord('A')) # 输出: 65 (大写字母 A)
print(ord('a')) # 输出: 97 (小写字母 a)
print(ord('0')) # 输出: 48 (数字 0)chr(code)- 将 ASCII 码转换为字符1
2
3print(chr(65)) # 输出: 'A'
print(chr(97)) # 输出: 'a'
print(chr(48)) # 输出: '0'
ASCII 码运算示例
1. 字符大小写转换
1 | # 大写转小写 |
2. 字符移位(凯撒密码)
1 | def caesar_cipher(text, shift): |
3. 字符比较
1 | char1 = 'a' |
4. 计算字符位置
1 | letter = 'G' |
5. 生成字母序列
1 | # 生成 A 到 Z |
ASCII 码表摘要
| 字符范围 | ASCII 范围 | 示例 |
|---|---|---|
| 数字 0-9 | 48-57 | ord('0') = 48 |
| 大写字母 A-Z | 65-90 | ord('A') = 65 |
| 小写字母 a-z | 97-122 | ord('a') = 97 |
| 特殊符号 | 32-47, 58-64, 91-96, 123-126 | ord('@') = 64 |
重要注意事项
Unicode 支持:
- Python 3 使用 Unicode,
ord()返回 Unicode 码点 - ASCII 字符的 Unicode 码点与 ASCII 值相同
- Python 3 使用 Unicode,
超出 ASCII 范围:
1
2
3# 处理非 ASCII 字符
print(ord('中')) # 输出: 20013 (中文字符的 Unicode)
print(chr(20013)) # 输出: '中'边界检查:
1
2
3
4
5# 确保在有效范围内操作
try:
print(chr(ord('z') + 1)) # 超出小写字母范围
except ValueError as e:
print(f"错误: {e}")
实际应用场景
- 数据加密/解密:实现简单的替换密码
- 文本处理:大小写转换、字符分类
- 算法实现:排序、搜索、字符串比较
- 编码转换:在不同字符编码间转换
- 输入验证:检查字符类型和范围
1 | # 实用函数:检查字符是否为数字 |
list (列表)
List (列表) 是 Python 中使⽤最频繁的数据类型。
专⻔⽤于存储⼀串数据,存储的数据称为元素
列表⽤ [] 定义,元素之间⽤逗号分隔
列表可以完成⼤多数集合类的数据结构实现。列表中元素的类型可以不相同,它⽀持数 字,字符串甚⾄可以包含列表(所谓嵌套)。 列表和字符串⼀样,索引从 0 开始,列表同样可以被索引和截取,列表被截取后返回⼀个 包含所需元素的新列表。
- List 可以使⽤ + 操作符进⾏拼接。
- ⽤星号 * 是重复操作
- 创建空列表: []
列表的常⽤操作
| 分类 | 关键字/函数/方法 | 说明 |
|---|---|---|
| 增加 | 列表.append(值) | 向列表末尾追加单个元素 |
| 列表.extend(值1,值2···,值n) | 向列表后面追加多个元素 | |
| 列表.insert(index,值) | 将某个元素插放到指定位置 | |
| 列表.pop(index) | 删除索引对应的元素,如果不加索引,默认删除最后元素,同时返回删除元素的引用关系 | |
| del 列表[1:2] | 按照切片指定索引删除列表元素 | |
| 列表.clear() | 按照切片指定索引删除列表元素 | |
| 修改 | 列表[索引]=值 | 修改指定索引的数据,数据不存在会报错 |
| 查询 | 列表[索引] | 根据索引取值,索引不存在会报错 |
| 列表.index(值) | 根据值取索引,值不存在会报错 | |
| 列表.count(值) | 返回列表中包含某个值的个数 | |
| 列表.sort() | 将列表中的元素进行排序,reverse=True代表降序 | |
| 列表.reverse() | 列表的反转,用来改变原列表的先后顺序 | |
| len(列表) | 列表长度(元素个数) | |
| max(列表) | 返回列表元素最大值 | |
| min(列表) | 返回列表元素最小值 | |
| sum(列表) | 返回列表元素的总和 |
字符串与列表转换
split 分割字符串为列表
join 拼接列表为字符串
1 | txt = "Google#Run,oob#Taobao#Facebook" |
tuple (元组)只读的列表。
1 | tuple1 = (1,2,34,5,6) |
set (集合) ⽆序,去掉重复数据。
1 | set1 = {1,2,3,4,5,5,4,3,2,1} |
不能使用下标访问set,所以修改操作一般为remove操作 + add操作
问题:如何定义一个空集合?
1 | set1=set() |
正确的类型声明是类型关键字()
dict (字典)
字典( dict )是 Python 中另⼀个⾮常有⽤的内置数据类型。
字典是键 (key) : 值 (value) 的 集合。
在同⼀个字典中,键 (key) 必须是唯⼀的。重复的后面的会覆盖前面的
创建空字典使⽤ { } 。
| 分类 | 函数 | 说明 |
|---|---|---|
| 增加 | dict[key]=value | 键不存在,会添加键值对 |
| 修改 | dict[key]=value | 键存在,会修改键值对 |
| 删除 | pop/del/clear | 没有索引 |
| 查询 | dict .keys() | 获取所有键,是一个视图 |
| dict.values() | 获取所有值,是一个视图 | |
| dict.items() | 获取键值对 |
在Python中,for i in dict: 循环迭代的是字典的键。在Python中,字典是一种键值对集合,每个键对应一个值。当你使用 for i in dict: 语法时,循环会遍历字典中的所有键,并将每个键依次赋值给变量 i12。
此外,Python还提供了其他几种遍历字典的方法:
- 遍历键:使用
.keys()方法,例如for key in dict.keys():。 - 遍历值:使用
.values()方法,例如for value in dict.values():。 - 遍历键值对:使用
.items()方法,例如for key, value in dict.items():12。
推导式
推导式格式为:表达式 for 变量 in 输⼊源 if 条件
推导式格式为:表达式 for 变量 in 输⼊源 if 条件 for 变量 in 输⼊源 if 条件
1 | # 给定一个列表,将每一位数字变成它的平方 alist = [1, 2, 3, 4, 5, 6, 7] |
数据源使⽤字典
1 | d1={"张三":20,"李四":30,"王五":40} |
list 、tuple、set、dict的区别
在 Python 中,list(列表)、tuple(元组)、set(集合)和 dict(字典)是四种核心数据结构,它们在特性、用途和性能上有显著区别:
📋 1. List(列表)
特性:有序集合,可变(可修改)
语法:
[元素1, 元素2, ...]特点:
- 保持元素插入顺序
- 允许重复元素
- 元素可以是不同类型
- 通过索引访问(
list[0])
操作:
1
2
3fruits = ["apple", "banana", "cherry"]
fruits.append("orange") # 添加元素
fruits[1] = "mango" # 修改元素时间复杂度:
- 访问:O(1)
- 插入/删除末尾:O(1)
- 插入/删除中间:O(n)
使用场景:需要保持顺序且可能修改的数据集合
📦 2. Tuple(元组)
特性:有序集合,不可变(创建后不能修改)
语法:
(元素1, 元素2, ...)或 单元素(元素,)特点:
- 比列表更节省内存
- 可哈希(可作为字典键)
- 保持元素插入顺序
- 允许重复元素
操作:
1
2
3colors = ("red", "green", "blue")
print(colors[0]) # 访问元素
# colors[1] = "yellow" # 错误!不可修改时间复杂度:访问 O(1)
使用场景:固定数据集合(如坐标点、数据库记录)、字典键
🧺 3. Set(集合)
特性:无序集合,可变,元素唯一
语法:
{元素1, 元素2, ...}或set(iterable)特点:
- 自动去重
- 不支持索引访问
- 只能包含可哈希对象(不可变类型)
- 支持集合运算(并集、交集等)
操作:
1
2
3
4vowels = {"a", "e", "i", "o", "u"}
vowels.add("y") # 添加元素
vowels.discard("i") # 删除元素
print("a" in vowels) # 成员检测时间复杂度:
- 添加/删除/成员检测:平均 O(1)
使用场景:去重、成员检测、集合运算
📖 4. Dict(字典)
特性:键值对集合,无序(Python 3.7+ 保持插入顺序),可变
语法:
{键1: 值1, 键2: 值2, ...}特点:
- 键必须是可哈希对象(通常为不可变类型)
- 键唯一,值可重复
- 通过键快速访问值
操作:
1
2
3person = {"name": "Alice", "age": 30}
person["email"] = "alice@example.com" # 添加/修改
print(person.get("age")) # 访问值时间复杂度:
- 访问/添加/删除:平均 O(1)
使用场景:键值映射、快速查找、JSON 数据表示
🆚 核心区别总结
| 特性 | List | Tuple | Set | Dict |
|---|---|---|---|---|
| 有序性 | ✔️ 保持顺序 | ✔️ 保持顺序 | ❌ 无序 | ❌ 无序(3.6+ 保持插入顺序) |
| 可变性 | ✔️ 可变 | ❌ 不可变 | ✔️ 可变 | ✔️ 可变 |
| 元素唯一性 | ❌ 允许重复 | ❌ 允许重复 | ✔️ 唯一 | 键唯一,值可重复 |
| 索引访问 | ✔️ 支持 | ✔️ 支持 | ❌ 不支持 | 通过键访问 |
| 内存效率 | 一般 | ✅ 较高 | 中等 | 中等 |
| 典型操作 | 增删改查 | 只读访问 | 集合运算/去重 | 键值查找 |
| 可哈希性 | ❌ 不可哈希 | ✅ 可哈希 | ❌ 不可哈希 | ❌ 不可哈希 |
| 空对象创建 | [] |
() |
set() |
{} |
💡 选择指南
- 需要有序且可修改 → 用 List
- 需要有序且不可变 → 用 Tuple(更安全、更快)
- 需要去重/成员检测 → 用 Set
- 需要键值映射 → 用 Dict
⚡ 性能对比(10万元素操作)
| 操作 | List | Tuple | Set | Dict |
|---|---|---|---|---|
| 查找元素 | O(n) | O(n) | O(1) | O(1) |
| 插入元素 | O(1)* | N/A | O(1) | O(1) |
| 内存占用(MB) | ~8.5 | ~7.2 | ~4.2 | ~4.8 |
列表插入末尾为 O(1),插入中间为 O(n)
函数
函数代码块以 def 关键词开头
return [ 表达式 ] 结束函数并返回,返回⼀个或多个值给调⽤⽅,不带表达式的 return 相 当于返回 None ,多个值为元组。
1 | # 声明 |
不定⻓参数
- 加了星号 * 的参数会以元组 (tuple) 的形式导⼊,存放所有未命名的变量参数。
- 加了两个 星号 ** 的参数会以字典的形式导⼊。
1 | def getNumTuple(n1,*n): |
值传递与引⽤传递
- 值传递:传递的是数值,适⽤于实参类型为不可变类型( int,float,bool,str,tuple )
- 引⽤传递:传递的是地址,适⽤于实参类型为可变类型( list,set,dict,class )
- 函数传参,能不传就不传,实在不行在传参。
main 函数– 程序的⼊⼝
1 | if __name__=="__main__": |
File( ⽂件 ) 读写
如果文件不存在,它会帮忙创建一个。
mode参数:
- w:覆盖写
- a(append):追加
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(Python 3 不支持)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
⽂本⽂件写
1
2
3
4with open("D:\\wtest.txt",mode='w',encoding='UTF-8') as f :
f.write("ccccccccccccccc\n")
f.write("ccccccccccccccc\n")
f.close()⽂本⽂件读
1
2
3
4
5with open("/root/python/test.txt",mode='r',encoding='UTF-8') as f:
result = f.read()
# resutl = f.readlines()
print(resutl)
f.close()- “相对路径不起作用”的真相:
- 问题不在
open(),而在于当前工作目录(CWD) 与你的预期不同 - CWD 是运行脚本时的终端路径,不是脚本所在路径
- 问题不在
- “相对路径不起作用”的真相:
Python 库 : 标准库 扩展库 ⾃定义库
在 python ⽤ import 或者 from … import 来导⼊相应的库。
- fieldnames在写的时候要提前准备好fieldnames列表,读的时候不用准备。
1 | import csv |
异常
一般是整个项目开发完,基础功能开发完,才开始做异常。不让整个程序崩溃。
这种异常一般是给用户提示用的。
程序崩溃
1 | try: |
⾃定义异常
使⽤ raise 语句抛出⼀个指定的异常 raise Exception(“ 不能是负数 “)
让程序崩溃,发生异常
⾯向对象 OOP 封装、继承、多态
类是抽象的,对象是具体的,先有类才有对象
封装
类及对象包含属性和⽅法
属性:静态特征 全局变量 成员
给类定义私有属性可以通过在属性名前加上双下划线
__来定义一个私有属性。这样做可以防止这个属性被外部代码直接访问和修改,从而保护类的内部状态。私有属性在类的外部是不可见的,但仍然可以在类的内部方法中使用。⽅法:动态特征 函数 功能
魔法⽅法:不需要调⽤就可以⾃动执⾏。
作⽤:初始化对象的成员 ( 给对象添加属性 )
1 | #类定义 |
继承
class ⼦类名 ( ⽗类名 ):
⼦类直接具备⽗类的属性和⽅法
解决代码重⽤问题,提⾼开发效率
1 | class Student(People): |
多态
多态从字⾯上理解就是⼀个事物可以呈现多种状态。
没有继承就没有多态。
多态是能⾃⼰进⾏判断该去执⾏什么 , 创建⼀个列表来体现 , ⾯向对象的列表。
1 | l1=[ldh,zjl] |
类的专有方法
- init : 构造函数,在生成对象时调用
- del : 析构函数,释放对象时使用
- repr : 打印,转换
- setitem : 按照索引赋值
- getitem: 按照索引获取值
- len: 获得长度
- cmp: 比较运算
- call: 函数调用
- add: 加运算
- sub: 减运算
- mul: 乘运算
- truediv: 除运算
- mod: 求余运算
- pow: 乘方
作业:
- 定义⼀个⽔果类,定义属性(名称和颜⾊),使⽤魔法⽅法,然后通过⽔果类,创建 苹果对象、橘⼦对象、西⽠对象并分别添加上颜⾊属性,定义⼀个⽅法分别输出 如:
红⾊的苹果真好吃
橙⾊的橘⼦真好吃
绿⾊的西⽠真好吃
猫类 Cat 。属性 : ⽑的颜⾊ color ,品种 breed ,亲和度 love 。⽅法 : 吃饭 eat()
狗类 Dog 。属性 : ⽑的颜⾊ color ,品种 breed ,忠诚度 loyal 。⽅法 : 吃饭 eat()
要求 : 使⽤封装、继承和多态
根据以上要求抽取⽗类为 Animal
重写 eat ⽅法
输出打印如下:
有⼀只亲和度是 10 级的花⾊的波斯猫正在吃⻥ …..
有⼀只忠诚度是 9 级的⿊⾊的藏獒正在啃⻣头 …..
有⼀只亲和度是 8 级的⽩⾊的加菲猫正在吃⻥ …..
有⼀只忠诚度是 6 级的棕⾊的茶杯⽝正在啃⻣头 …..
time&datetime 库
Python 中处理时间的标准库
- 提供获取系统时间并格式化输出功能
- 提供系统级精确计时功能,⽤于程序性能分析
time 库
包含三类函数
- 时间获取: localtime()
- 时间格式化: strftime() strptime() string format time 格式化字符串 string parse time 解析字符串
- 程序计时: sleep() perf_counter()
1 | import time |
连接 MySQL 操作
pymysql 是在 Python3.x 版本中⽤于连接 MySQL 服务器的⼀个库 在 vscode 终端下⾯直接运⾏ pip3 install pymysql 安装即可
1 | import pymysql |
结构操作
1 | # 使用预处理语句创建表 |
数据增删改操作
1 | c="insert into MovieType values(1,'喜剧','这是一种搞笑的视频',now())" |
数据查询操作
baoma.fetchone(): 执⾏完毕返回的结果集默认以元组显⽰
baoma.fetchall(): 元组的元组
1 | import pymysql |
上机练习 9
灵活使⽤ pymyql 来完成创建表、添加数据、查询数据
1
2
3
4
5
6
7
8
9create table if not exists MovieType(
tid int primary key,
tname varchar(20),
tcontent varchar(200),
tdate datetime
)
insert into MovieType values(1,'喜剧','这是一个搞笑的电影',now())
insert into MovieType values(2,'动作','这是一个打斗的电影',now())
select * from MovieType查询数据时⽇期处理成如下格式:
1 喜剧 这是⼀个搞笑的电影 2023 年 08 ⽉ 21 ⽇
2 动作 这是⼀个打⽃的电影 2023 年 08 ⽉ 21 ⽇
三层架构–面向对象思想
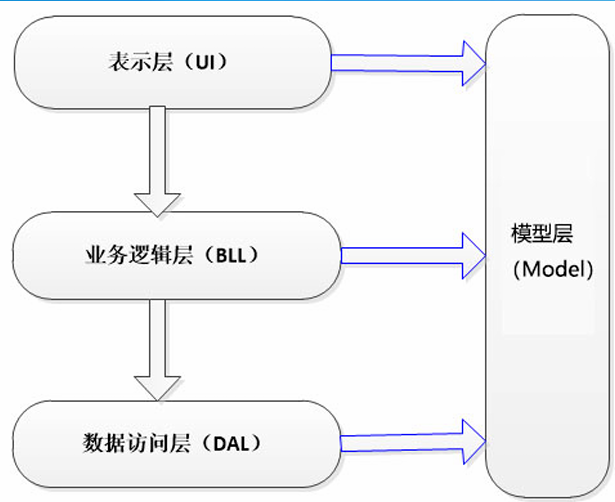
os库
os ( operating system )是 Python 程序与操作系统进⾏交互的接⼝
1 、 os.listdir ()返回对应⽬录下的所有⽂件及⽂件夹
2 、 os.mkdir ()创建⽬录(只⽀持⼀层创建)即新建⼀个路径
3 、 os.open ()创建⽂件相当于全局函数 open() ( IO 流) os.open(“t.txt”,os.O_CREAT)
4 、 os.remove (⽂件名或路径)删除⽂件
5 、 os.rmdir ()删除⽬录
6 、 os.system ()执⾏终端命令 os.system(“touch a.txt”)
pandas库
Pandas 是 Python 语⾔的⼀个扩展程序库,⽤于数据分析。
Pandas 名字衍⽣⾃术语 “panel data” (⾯板数据)
Pandas 可以从各种⽂件格式⽐如 CSV 、 JSON 、 Excel
Pandas 数据结构 - DataFrame
1 | data = {"Site":["Google", "Runoob", "Wiki"], "Age":[10, 12, 13],"sss":[22,33,44]} |
Pandas CSV ⽂件
1 | df = pd.read_csv("/root/shell/douban.csv") |
Pandas JSON
json.loads() 函数是将字符串转化为字典
1 | import pandas as pd |
Pandas excel ⽂件
- sheet_name 指定了读取 excel ⾥⾯的哪⼀个 sheet
- usecols 指定了读取哪些列 nrows 指定了总共读取多少⾏
- header 指定了列名在第⼏⾏,并且只读取这⼀⾏往下的数据
- index_col 指定了 index 在第⼏列
- engine=”openpyxl” 指定了使⽤什么引擎来读取 excel ⽂件
安装: pip3 install openpyxl
1 | import pandas as pd |
Numpy
NumPy(Numerical Python)是 Python 中用于科学计算的基础且极其核心的库。它提供了一个强大的 N 维数组对象以及一系列操作这些数组的函数和工具。几乎所有处理数值数据的 Python 库(如 Pandas, SciPy, Matplotlib, scikit-learn, TensorFlow, PyTorch 等)都建立在 NumPy 之上或与其深度集成。
以下是 NumPy 的关键特性和介绍:
核心对象:
ndarray(N-dimensional array)- 多维同质数组: 这是 NumPy 的核心数据结构。它是一个包含相同类型元素的表格(通常是数字),可以通过非负整数元组进行索引。
- 维度 (axes): 数组有维度。例如:
- 一维数组:
[1, 2, 3](1 个轴) - 二维数组:
[[1, 2, 3], [4, 5, 6]](2 个轴:行、列) - 三维数组:想象一个立方体的数据 (3 个轴)。
- 一维数组:
- 形状 (shape): 一个表示每个维度大小的元组。例如,上面的二维数组形状是
(2, 3)(2 行,3 列)。 - 数据类型 (dtype): 数组中元素的类型,如
int32,int64,float32,float64,bool_,string_等。定义类型对于内存占用和计算效率至关重要。 - 内存效率与速度:
ndarray在内存中连续存储(或按特定步幅存储),并使用编译后的低级代码(C/Fortran)进行操作,这比 Python 原生的列表 (list) 处理数值数据要快得多,内存效率高得多,尤其是对于大型数据集。
矢量化操作 (Vectorization)
NumPy 最重要的特性之一。它允许你对整个数组执行操作(加、减、乘、除、比较、函数应用等),无需编写显式的循环。
优势:
- 简洁性: 代码更短,更易读,更接近数学表达式。
- 高性能: 底层使用高效的预编译例程,避免了 Python 循环的解释器开销。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13import numpy as np
a = np.array([1, 2, 3, 4])
b = np.array([5, 6, 7, 8])
# 矢量化加法 - 对整个数组操作
c = a + b # 结果: array([6, 8, 10, 12])
# 矢量化乘法
d = a * 2 # 结果: array([2, 4, 6, 8])
# 数学函数作用于整个数组
e = np.sin(a) # 计算每个元素的正弦值
广播 (Broadcasting)
这是一组强大的规则,允许 NumPy 对形状不同的数组执行算术运算。
核心思想:将较小的数组“广播”到较大数组的形状,使它们具有兼容的形状,然后进行逐元素操作。
规则(简化):
- 如果两个数组维度数不同,小维度数组的形状会在其左边填充
1。 - 如果两个数组在某个维度上的大小相同,或者其中一个的大小为
1,则认为它们在该维度上是兼容的。 - 数组只能在所有维度都兼容的情况下广播。
- 广播后,每个数组的行为就像它拥有和最大数组一样的形状。
- 如果两个数组维度数不同,小维度数组的形状会在其左边填充
示例:
1
2
3
4
5
6
7
8
9
10a = np.array([[1, 2, 3], # shape (2, 3)
[4, 5, 6]])
b = np.array([10, 20, 30]) # shape (3,) -> 广播为 (1, 3) -> (2, 3)
c = a + b
# 结果:
# [[1+10, 2+20, 3+30],
# [4+10, 5+20, 6+30]]
# = [[11, 22, 33],
# [14, 25, 36]]
丰富的函数库
- 数学运算:
np.add(),np.subtract(),np.multiply(),np.divide(),np.exp(),np.log(),np.sin(),np.cos(),np.sum(),np.mean(),np.std(),np.min(),np.max()等。 - 线性代数:
np.dot()(点积/矩阵乘法),np.linalg.inv()(矩阵求逆),np.linalg.det()(行列式),np.linalg.eig()(特征值/特征向量) 等 (主要在numpy.linalg子模块)。 - 数组操作:
np.reshape(),np.concatenate(),np.split(),np.transpose(),np.sort(),np.ravel()(展平), 切片、索引(基础索引、布尔索引、花式索引)。 - 随机数生成:
np.random.rand(),np.random.randn(),np.random.randint(),np.random.normal()等 (在numpy.random子模块)。 - 逻辑运算:
np.logical_and(),np.logical_or(),np.logical_not(), 比较运算符 (==,!=,<,>,<=,>=) 返回布尔数组。 - 文件 I/O:
np.loadtxt(),np.savetxt(),np.load()(用于.npy格式),np.save()(用于.npy格式),方便读写数组数据。
- 数学运算:
与其他库的互操作性
- NumPy 数组是 Python 科学计算生态系统的通用数据交换格式。
- Pandas 的
DataFrame和Series可以轻松转换为 NumPy 数组 (.values或.to_numpy())。 - SciPy 为科学计算(优化、积分、插值、信号处理等)提供了更多高级函数,通常直接操作 NumPy 数组。
- Matplotlib 等绘图库直接接受 NumPy 数组进行绘图。
- scikit-learn、TensorFlow、PyTorch 等机器学习/深度学习框架的核心数据结构通常基于或兼容 NumPy 数组 (
numpy.ndarray或能与之转换的 tensor 类型)。
Matplotlib
Matplotlib 是 Python 生态系统中最核心的数据可视化库,由 John D. Hunter 于 2003 年创建。它提供了类似 MATLAB 的绘图接口,同时具备 Python 的灵活性和强大功能,已成为科学计算、数据分析和机器学习领域的标准可视化工具。
核心特点
- 全面的图表支持:
- 基础图表:折线图、散点图、柱状图、饼图、直方图
- 高级图表:等高线图、热力图、3D图、矢量场图
- 统计图表:箱线图、误差棒图、小提琴图
- 地理绘图:基础地图投影(需配合 Basemap 或 Cartopy)
- 多平台兼容:
- Jupyter Notebook 内嵌显示
- 独立的 GUI 窗口
- 多种格式导出:PNG, PDF, SVG, EPS 等
- Web 应用集成(通过 Agg 后端)
- 高度可定制:
- 细粒度控制每个图表元素
- 支持 LaTeX 数学公式
- 丰富的样式和颜色配置
- 与科学计算栈无缝集成:
- 原生支持 NumPy 数组
- 与 Pandas DataFrame 深度集成
- 作为 Seaborn、Plotly 等高级库的基础
关键对象
- Figure(图形):顶级容器,相当于画布
- Axes(坐标系):实际绘图区域,包含坐标轴、标题等
- Axis(坐标轴):处理刻度、标签和网格线
- Artist(艺术家):所有可见元素的基类
基本使用模式
1. 快速绘图(pyplot 方式)
1 | import matplotlib.pyplot as plt |
2. 面向对象方式(推荐用于复杂图表)
1 | # 创建图形和坐标系 |
常用图表类型示例
1. 多子图布局
1 | fig, axes = plt.subplots(2, 2, figsize=(12, 8)) |
2. 高级可视化:3D 曲面图
1 | from mpl_toolkits.mplot3d import Axes3D |
unittest
unittest 是 Python 标准库中的一个单元测试框架,也称为 PyUnit(受 JUnit 启发)。它提供了一套完整的工具来编写、组织和运行测试用例,帮助开发者验证代码的正确性,确保代码在修改或扩展后仍然能按预期工作。
核心组件
1. TestCase 类
- 每个测试用例都继承自
unittest.TestCase。 - 测试方法必须以
test_开头,例如test_addition()。 - 包含断言方法(如
assertEqual、assertTrue等)来验证预期结果。
1 | import unittest |
2. TestSuite 类
- 用于组合多个测试用例或测试套件,形成更大的测试集合。
- 可以通过
addTest()方法动态添加测试。
1 | suite = unittest.TestSuite() |
3. TestLoader 类
- 自动发现和加载测试用例。
- 可以扫描指定目录或模块,查找所有继承自
TestCase的类和方法。
1 | loader = unittest.TestLoader() |
4. TextTestRunner 类
- 用于运行测试套件并输出结果。
- 支持多种输出格式(如文本、XML、HTML 等)。
1 | runner = unittest.TextTestRunner() |
常用断言方法
| 方法 | 描述 |
|---|---|
assertEqual(a, b) |
验证 a == b |
assertNotEqual(a, b) |
验证 a != b |
assertTrue(x) |
验证 x 为真 |
assertFalse(x) |
验证 x 为假 |
assertIs(a, b) |
验证 a 和 b 是同一个对象 |
assertIsNot(a, b) |
验证 a 和 b 不是同一个对象 |
assertIsNone(x) |
验证 x 是 None |
assertIsNotNone(x) |
验证 x 不是 None |
assertIn(a, b) |
验证 a 在 b 中 |
assertNotIn(a, b) |
验证 a 不在 b 中 |
assertRaises(exc, fun, *args, **kwargs) |
验证 fun(*args, **kwargs) 抛出异常 exc |
测试夹具(Fixtures)
- **
setUp()**:在每个测试方法运行前执行,用于初始化测试环境。 - **
tearDown()**:在每个测试方法运行后执行,用于清理测试环境。 setUpClass()和 **tearDownClass()**:在类级别执行,分别用于类级别的初始化和清理(需使用@classmethod装饰器)。
1 | class MyTestCase(unittest.TestCase): |
运行测试
1. 命令行运行
使用
python -m unittest运行测试。可以指定模块、类或方法:
1
2
3python -m unittest tests.test_module
python -m unittest tests.test_module.MyTestCase
python -m unittest tests.test_module.MyTestCase.test_method
2. 发现测试
使用
1
discover
选项自动发现测试:
1
2bash
python -m unittest discover -s tests -p "test_*.py"
示例:完整测试流程
1 | # 文件:math_operations.py |
运行测试:
1 | bash |
输出:
1 | .. |
优点
- 内置支持:
unittest是 Python 标准库的一部分,无需额外安装。 - 结构清晰:通过继承
TestCase和方法命名约定,测试代码结构清晰。 - 功能丰富:提供多种断言方法和测试夹具,满足复杂测试需求。
- 易于集成:可以与持续集成工具(如 Jenkins、GitHub Actions)无缝集成。
适用场景
- 单元测试:验证单个函数或方法的正确性。
- 集成测试:验证多个模块或组件的交互。
- 回归测试:确保代码修改后不会引入新的问题。
总结
unittest 是 Python 中功能强大且易于使用的单元测试框架,适合大多数 Python 项目的测试需求。通过合理组织测试用例和利用测试夹具,可以显著提高代码的可靠性和可维护性。
Setuptools:Python 打包与分发的核心工具
Setuptools 是 Python 生态系统中最重要且广泛使用的包构建工具,它扩展了 Python 标准库中的 distutils 模块,为开发者提供了强大的项目打包、依赖管理和分发能力。几乎所有现代 Python 包都依赖于 Setuptools 进行构建和分发。
核心功能与价值
1. 项目打包
- 将 Python 代码组织成可分发的格式(源码包、wheel 等)
- 自动包含项目文件和非代码资源
- 支持复杂项目结构(命名空间包、多包项目)
2. 依赖管理
- 声明项目依赖(
install_requires) - 指定可选依赖组(
extras_require) - 自动解决依赖关系树
3. 元数据管理
- 定义项目元数据(名称、版本、作者等)
- 提供分类信息(PyPI 分类器)
- 支持许可证和项目URL
4. 可执行文件创建
- 自动生成平台相关的可执行脚本
- 通过入口点(entry points)创建命令行工具
5. 扩展构建
- 编译和打包 C/C++ 扩展
- 集成 Cython 等工具
核心组件解析
1. setup.py - 项目构建脚本
1 | from setuptools import setup, find_packages |
2. setup.cfg - 声明式配置(推荐)
1 | [metadata] |
3. pyproject.toml - 现代构建配置(PEP 517/518)
1 | [build-system] |
关键功能详解
1. 包发现与组织
1 | # 自动发现所有包 |
2. 依赖管理最佳实践
1 | install_requires = [ |
3. 入口点机制
1 | entry_points = { |
4. 数据文件与资源管理
1 | # 包含包内数据文件 |
工作流程与命令
1. 开发模式安装
1 | # 可编辑安装(代码变更实时生效) |
2. 构建分发包
1 | # 安装构建工具 |
3. 发布到PyPI
1 | # 安装发布工具 |
4. 常用开发命令
1 | # 安装开发依赖 |
现代打包最佳实践
1. 项目结构推荐
1 | my_project/ |
2. 版本管理策略
1 | # 在 __init__.py 中定义版本 |
3. 兼容性处理
1 | # 处理不同Python版本的依赖 |
高级功能
1. C扩展集成
1 | from setuptools import Extension, setup |
2. 自定义构建命令
1 | from setuptools import setup |
3. 动态元数据
1 | # setup.py 中动态生成元数据 |
常见问题解决
1. 包找不到问题
1 | # 正确设置包目录 |
2. 数据文件未包含
ini
1 | # setup.cfg 中启用包数据 |
3. 入口点不工作
1 | # 确保函数路径正确 |
生态系统整合
- 与 pip 集成:Setuptools 是 pip 安装过程的核心组件
- 与 virtualenv 协作:在隔离环境中构建和测试
- 与 tox 配合:跨多Python版本测试
- 与 cibuildwheel 集成:构建跨平台二进制wheel
- 与 Sphinx 结合:自动生成文档
演进与未来
- PEP 517/518:现代构建系统标准
pyproject.toml支持:逐步替代 setup.py- 静态元数据:减少动态执行需求
- 构建隔离:更安全的构建环境
Jupyter 介绍
Jupyter 是一个开源的交互式计算环境,广泛应用于数据科学、机器学习、科学计算和教育领域。它支持多种编程语言(如 Python、R、Julia 等),允许用户以交互式的方式编写代码、运行实验、可视化数据并记录结果。以下是 Jupyter 的核心特性和应用场景的详细介绍。
核心组件
1. Jupyter Notebook
- 交互式文档:以
.ipynb文件格式存储,包含代码、文本(Markdown)、公式(LaTeX)、图表和多媒体内容。 - 代码单元格(Code Cells):逐行或分块执行代码,实时查看输出结果。
- Markdown 单元格:支持富文本格式,用于解释代码、记录实验步骤或撰写报告。
- 输出可视化:直接在 Notebook 中显示图表(如 Matplotlib、Plotly)和交互式控件(如 ipywidgets)。
2. JupyterLab
下一代界面
:基于 Web 的交互式开发环境(IDE),提供更强大的功能:
- 多窗口布局:同时打开多个 Notebook、终端、文本编辑器等。
- 文件浏览器:直接管理项目文件和目录。
- 扩展支持:通过插件扩展功能(如调试器、Git 集成)。
兼容性:完全兼容 Jupyter Notebook,支持所有 Notebook 文件。
3. Jupyter Kernel
计算引擎
:负责执行代码的核心组件,支持多种编程语言:
- IPython Kernel:Python 的默认内核。
- IRKernel:R 语言支持。
- IJulia:Julia 语言支持。
- 其他内核:如 Bash、Scala、Go 等。
主要功能
1. 交互式计算
- 实时反馈:代码单元格执行后立即显示结果,适合快速迭代和调试。
- 魔法命令(Magic Commands):IPython 提供的特殊命令(如
%timeit测量代码性能)。
2. 数据可视化
- 静态图表:通过 Matplotlib、Seaborn 等库生成。
- 交互式图表:支持 Plotly、Bokeh 等库,允许用户缩放、平移和筛选数据。
3. 协作与分享
- Notebook 导出:支持导出为 HTML、PDF、LaTeX、Python 脚本等格式。
- 在线共享:通过 JupyterHub 或平台(如 Google Colab、Binder)共享 Notebook。
- 版本控制:与 Git 集成,方便团队协作和代码管理。
4. 教育与研究
- 教学工具:通过 Markdown 单元格编写教程,结合代码示例和可视化。
- 实验记录:记录实验步骤、参数和结果,方便复现和分享。
应用场景
1. 数据科学
- 数据清洗与探索性分析(EDA)。
- 机器学习模型训练与评估。
- 结果可视化与报告生成。
2. 科学计算
- 数值模拟与算法开发。
- 科学实验数据的分析与可视化。
3. 教育与培训
- 编程教学(如 Python、R 入门)。
- 数据科学课程实践。
4. 技术文档
- 编写技术文档或教程,结合代码示例和解释。
安装与使用
1. 安装 Jupyter
通过 pip 安装
1
2bash
pip install notebook通过 conda 安装
1
2bash
conda install -c conda-forge notebook安装 JupyterLab
:
1
2bash
pip install jupyterlab
2. 启动 Jupyter
启动 Notebook
1
2bash
jupyter notebook启动 JupyterLab
1
2bash
jupyter lab默认会在浏览器中打开
http://localhost:8888。
3. 创建 Notebook
- 在 Jupyter 界面中,点击 New → Python 3(或其他内核)创建新 Notebook。
高级功能
1. JupyterHub
- 多用户支持:允许多个用户同时使用 Jupyter Notebook,适合教育机构或企业。
- 部署方式:可通过 Docker、Kubernetes 等容器化技术部署。
2. Binder
- 免费在线环境:将 GitHub 仓库中的 Notebook 直接转换为可交互的在线环境。
- 示例:访问 mybinder.org 并输入仓库 URL。
3. 扩展与插件
- JupyterLab 扩展:如调试器、Git 集成、表格编辑器等。
- Notebook 扩展:如代码折叠、目录生成等。
与其他工具的集成
1. 与 Git 集成
- 通过
nbdime工具比较和合并 Notebook 版本。 - 在 JupyterLab 中直接使用 Git 插件。
2. 与云平台集成
- Google Colab:免费在线 Jupyter 环境,支持 GPU/TPU。
- AWS SageMaker:托管 Jupyter Notebook,支持大规模计算。
3. 与大数据工具集成
- Spark:通过 PySpark 内核在 Jupyter 中运行 Spark 作业。
- Dask:用于并行计算,支持大规模数据处理。
优缺点分析
优点
- 交互性强:适合快速迭代和实验。
- 可视化丰富:支持多种图表和交互式控件。
- 文档化:结合代码和文本,方便记录和分享。
- 多语言支持:支持 Python、R、Julia 等多种语言。
缺点
- 性能问题:对于大规模数据处理,Notebook 可能不如脚本高效。
- 版本控制困难:Notebook 文件是 JSON 格式,直接使用 Git 可能产生冲突。
- 安全性:默认情况下,Jupyter 服务器可能暴露在公网,需注意配置。
推荐使用场景
- 数据科学初学者:快速上手 Python 和数据分析。
- 实验性项目:需要频繁调整参数和可视化结果。
- 教学与培训:编写交互式教程。
- 技术文档:结合代码示例和解释。
总结
Jupyter 是一个功能强大且灵活的交互式计算环境,适合数据科学、科学计算和教育领域。通过 Jupyter Notebook 和 JupyterLab,用户可以以交互式的方式编写代码、可视化数据并记录结果。尽管存在一些性能和版本控制的挑战,但通过合理使用工具和最佳实践,Jupyter 可以显著提高工作效率和协作能力。
推荐工具组合
- 本地开发:JupyterLab + 常用扩展(如 Git 集成、调试器)。
- 在线协作:Google Colab 或 JupyterHub。
- 大规模计算:结合 Spark/Dask 或云平台(如 AWS SageMaker)。





