Hadoop简介
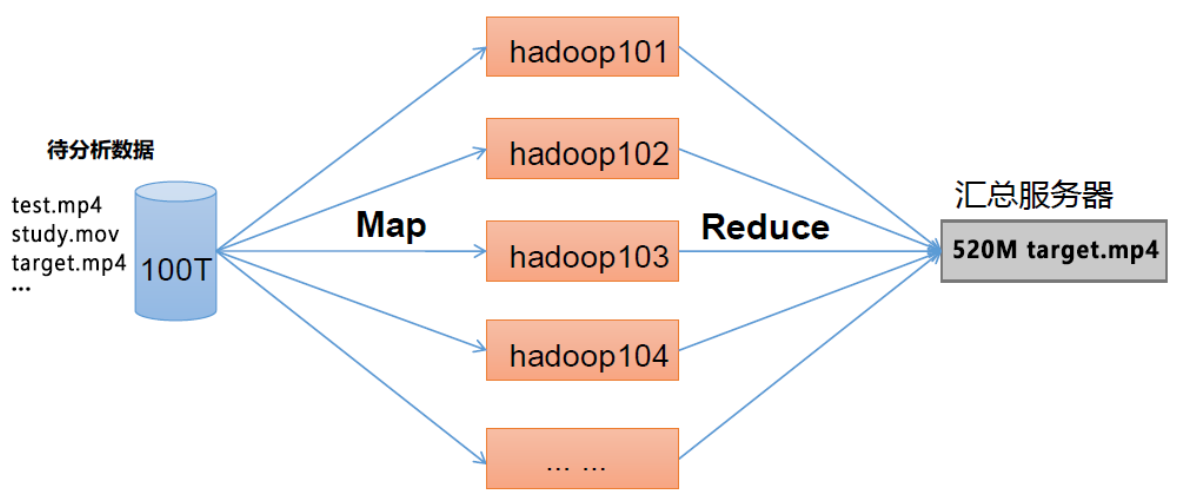
Hadoop是一个由Apache基金会所开发的分布式系统基础架构
主要解决,海量数据的存储和海量数据的分析计算问题
广义上来说,Hadoop通常是指一个更广泛的概念-Hadoop生态圈
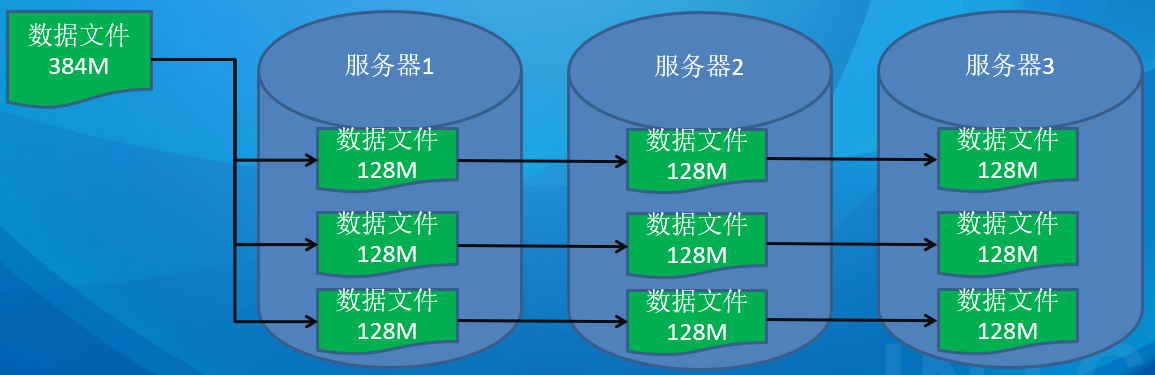
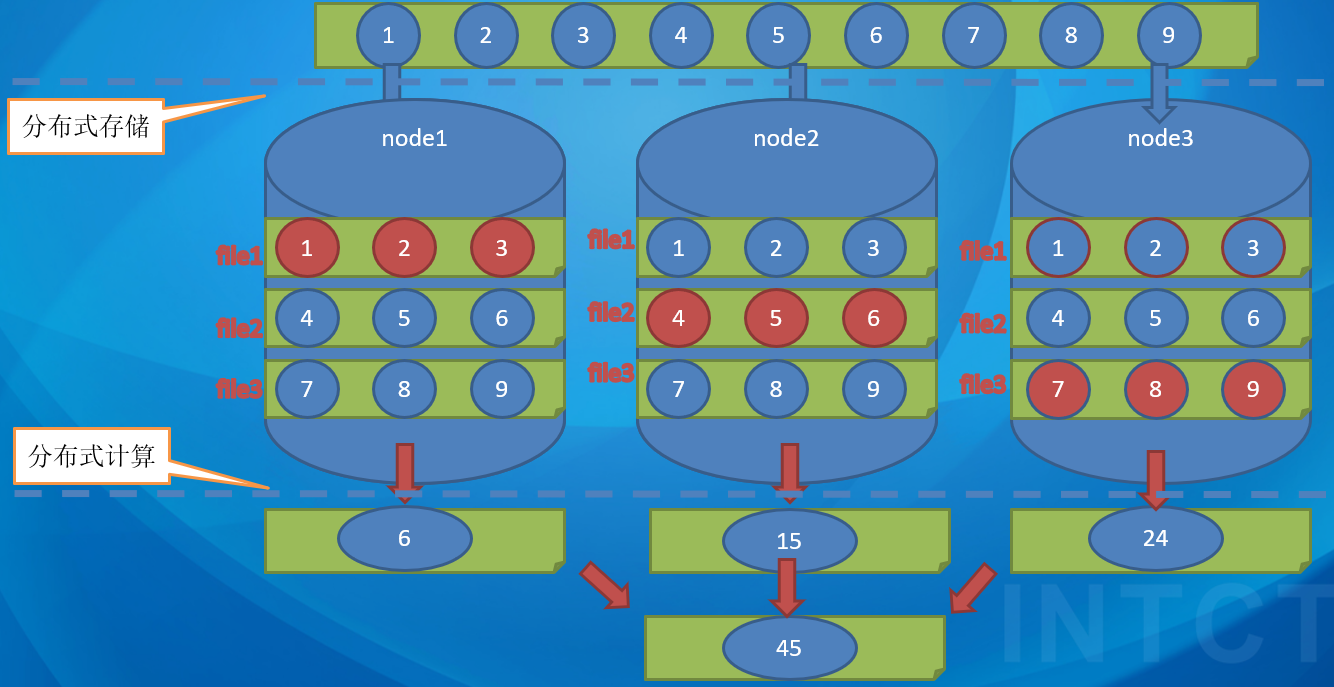
分布式存储 Hadoop 的分布式存储主要基于 HDFS(分布式文件系统):分割成多个数据块(block) ,这些数据块分散存储在集群中的不同节点上 。每个数据块会有多个副本,通常默认是 3 个副本.采用分布式存储在不同的节点上,提高了数据的可靠性和容错性。
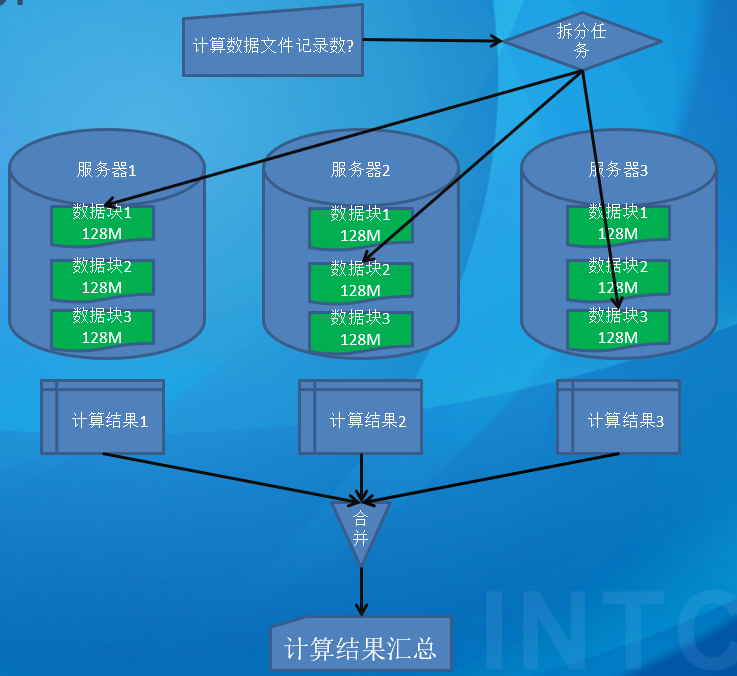
Hadoop的分布式核心组件是MapReduce编程模型:
Hadoop组件(面试重点) hadoop问答小测验
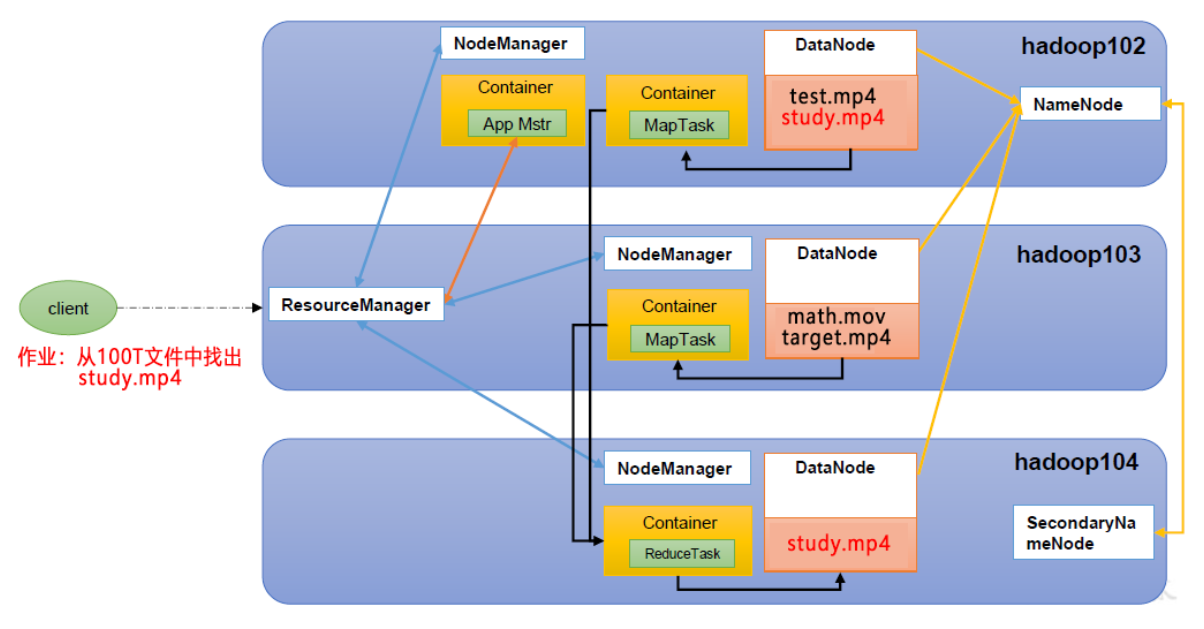
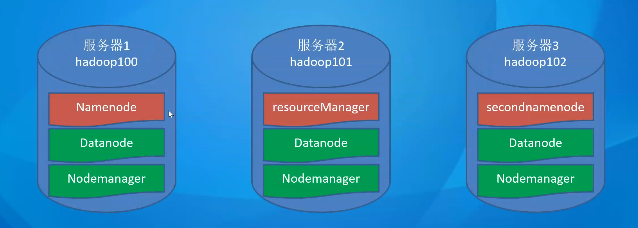
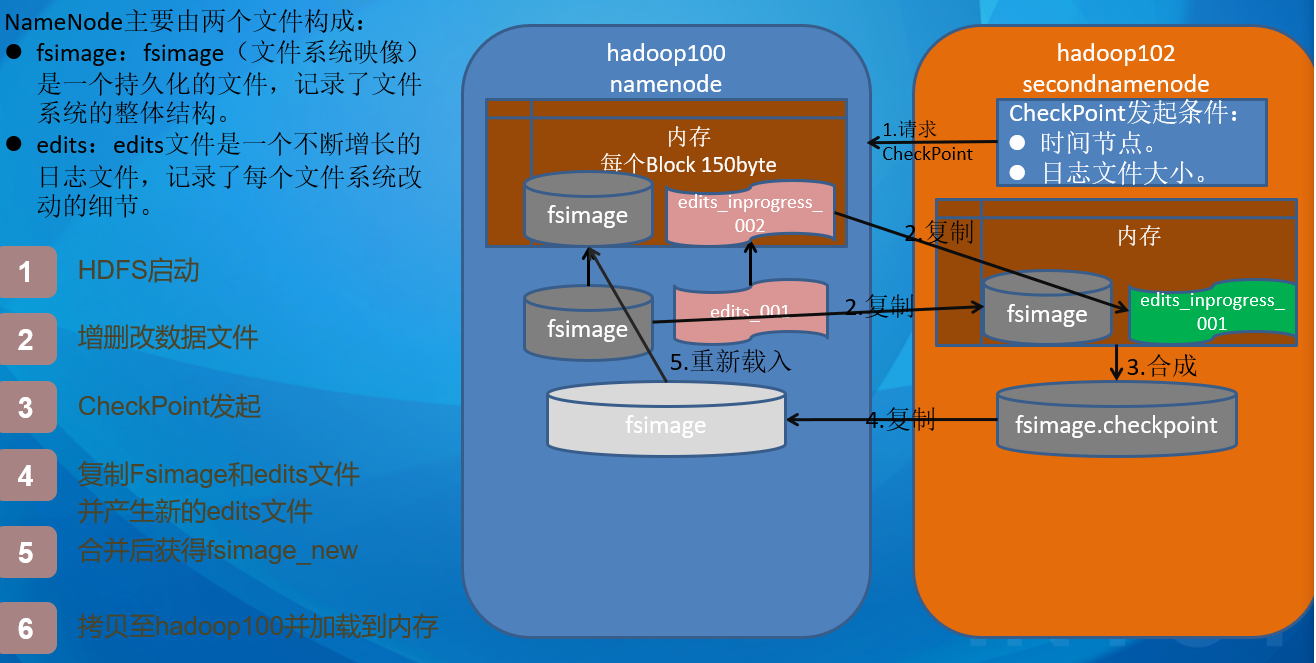
HDFS 架构概述 HDFS组件用于存储数据,主要由NameNode,DataNode,SecondaryNameNode 组成
NameNode (nn) : 存储文件的元数据 ,如文件名,文件目录结构,文件属性 (生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。DataNode(dn) : 在本地文件系统存储文件块数据,以及块数据的校验。 SecondaryNameNode(2nn) : 每隔一段时间对NameNode元数据进行备份
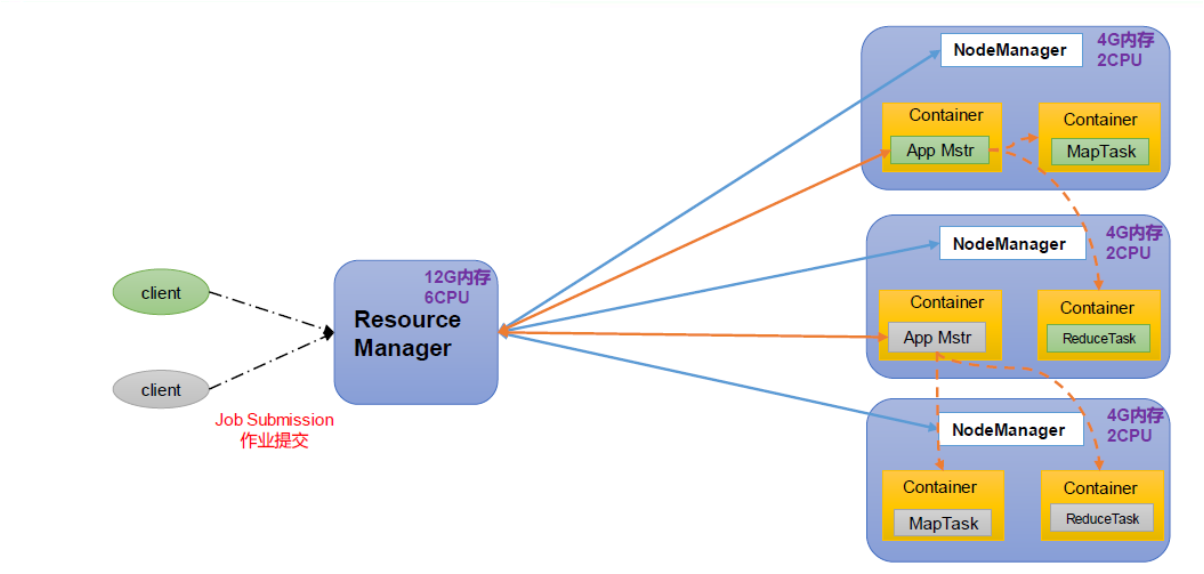
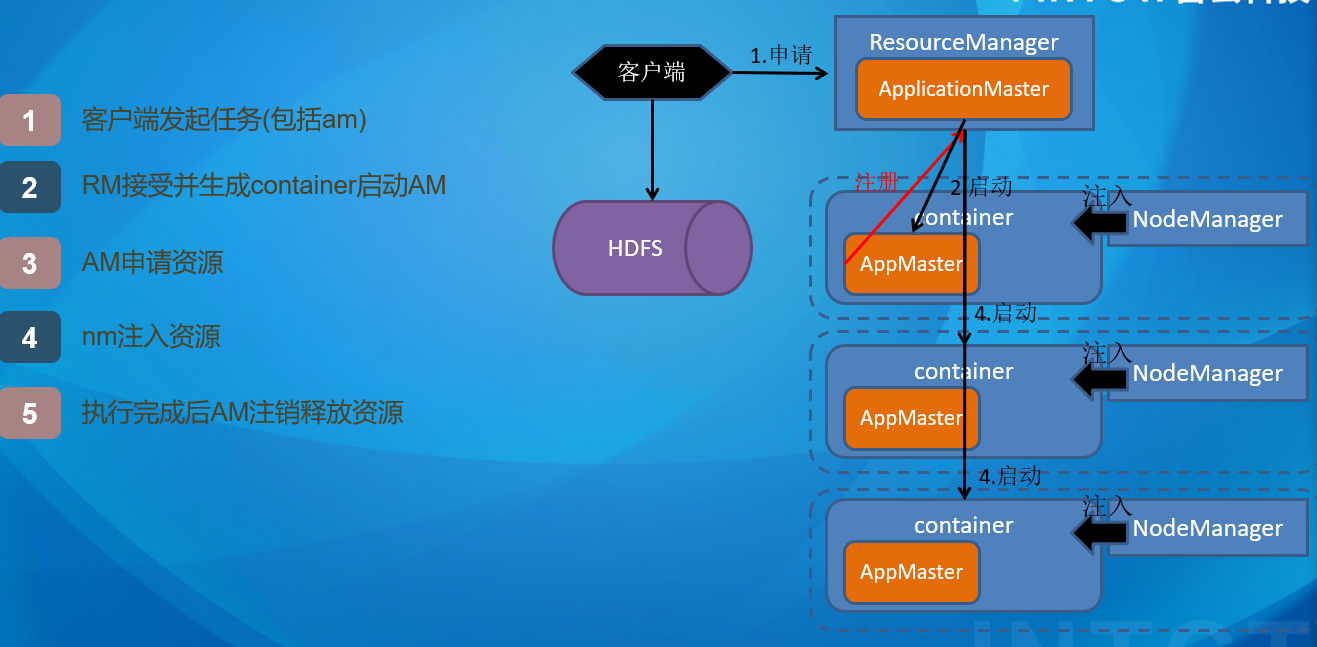
Yarn 架构概述 Yet Another Resource Negotiator 简称YARN ,另一种资源协调者,是Hadoop 的资源管理器。
Yarn资源调度负责硬件资源管理,主要由:ResourceManager,NodeManager,ApplicationMaster组成
ResourceManager (资源管理器):.YARN集群中的中心调度器和资源管理器。 负责整个集群的资源分配和调度 监控集群中的计算资源任务的运行状态 。NodeManager (节点管理器):单个节点服务器资源的管理者。 每个计算节点上运行的代理程序负责管理和监控节点上的资源和任务 。接收来自RM的任务调度请求;启动、停止和监控任务的执行;发送节点的状态和可用资源报告ApplicationMaster (应用程序管理器):单个任务运行的管理者 。每个应用程序在YARN中都有一个对应的AM.AppMaster负责协调和管理应用程序的执行。它与RM交互申请资源并监任务的执行。它还负责任务的划分和调度、容错和恢复、进度跟踪 等。Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如 内存、CPU、磁盘、网络
说明:
MapReduce 架构概述 MapReduce 将计算过程分为两个阶段:Map 和Reduce
Map 阶段并行处理输入数据
Reduce 阶段对Map 结果进行汇总
HDFS、YARN、MapReduce 三者关系
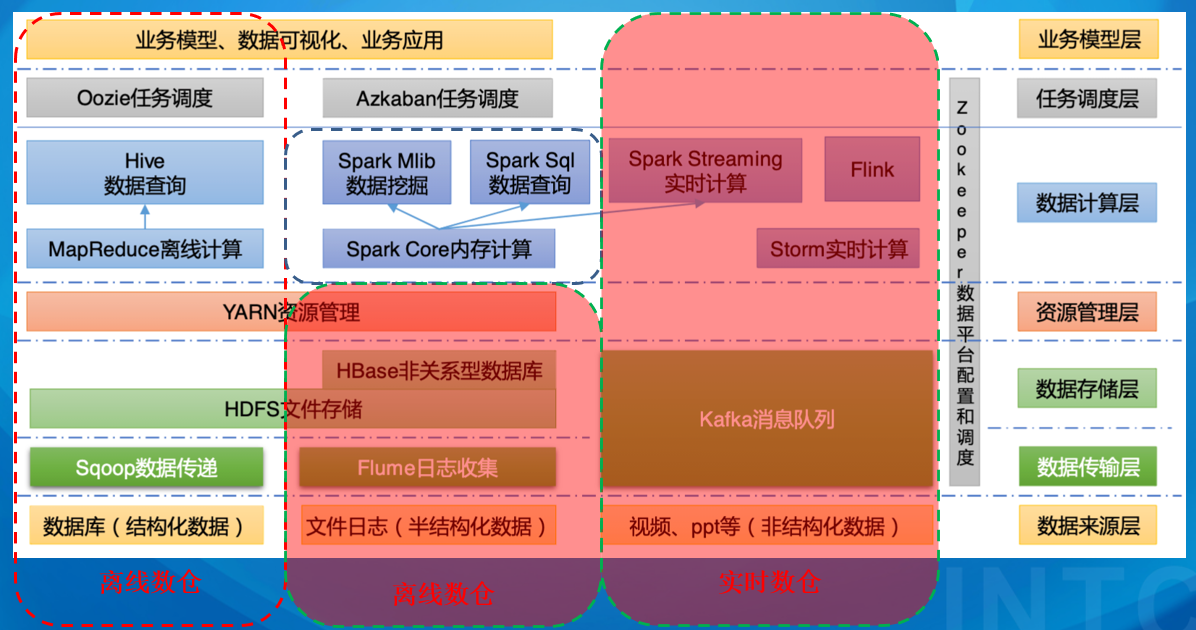
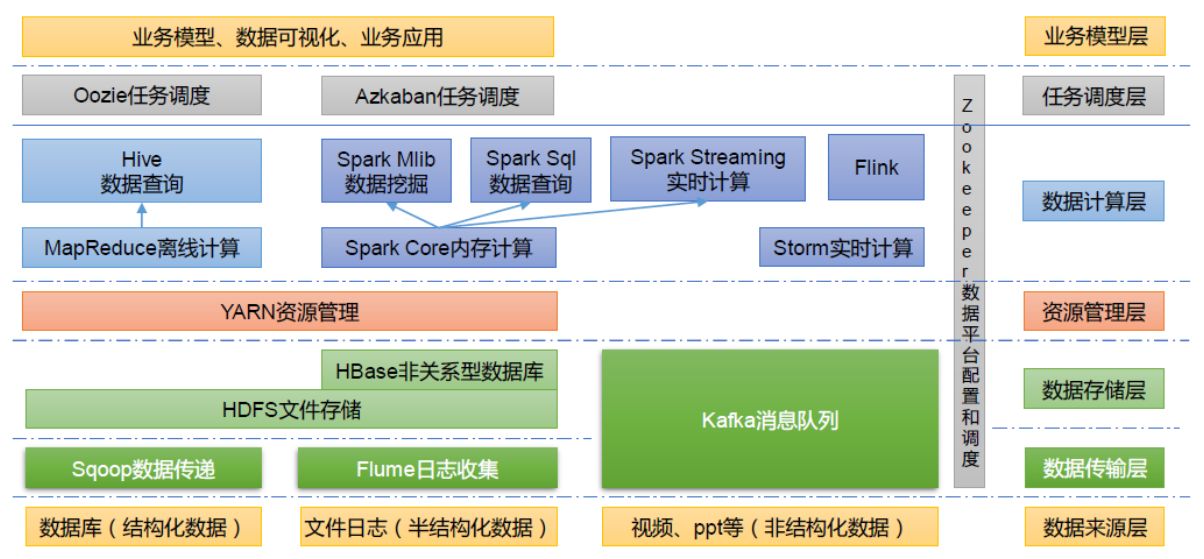
大数据技术生态体系
Sqoop:Sqoop 是一款开源的工具,主要用于在Hadoop、Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop 的HDFS 中,也可以将HDFS 的数据导进到关系型数据库中。Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据。Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统。Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于Hadoop 上存储的大数据进行计算。Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。Oozie:Oozie 是一个管理Hadoop 作业(job)的工作流程调度管理系统。Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。Hive:Hive 是基于Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL 查询功能,可以将SQL 语句转换为MapReduce 任务进行运行。其优点是学习成本低,可以通过类SQL 语句快速实现简单的MapReduce 统计,不必开发专门的MapReduce 应用,十分适合数据仓库的统计分析。ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
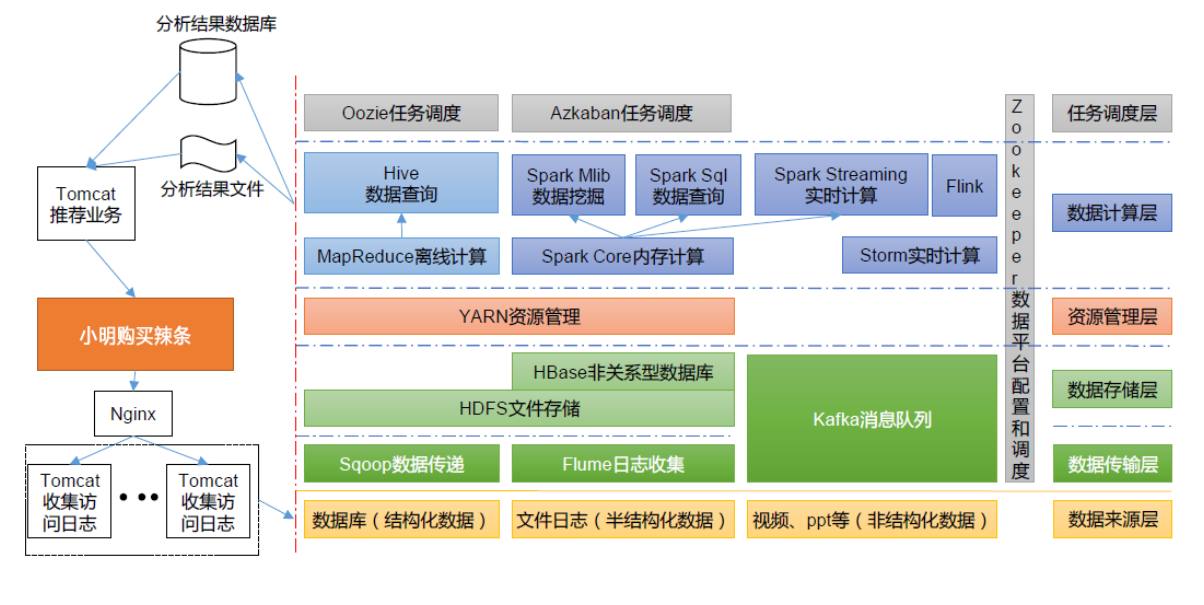
推荐系统框架图 推荐系统项目框架
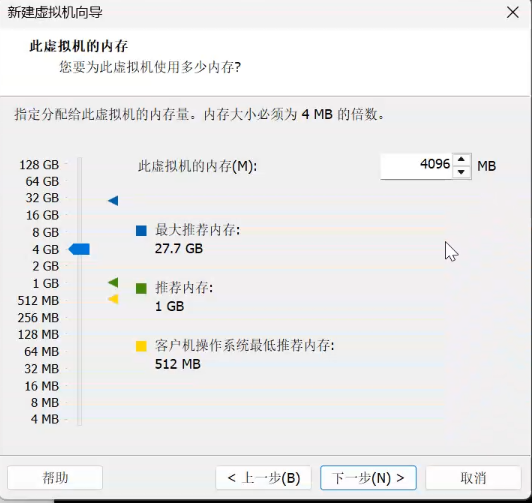
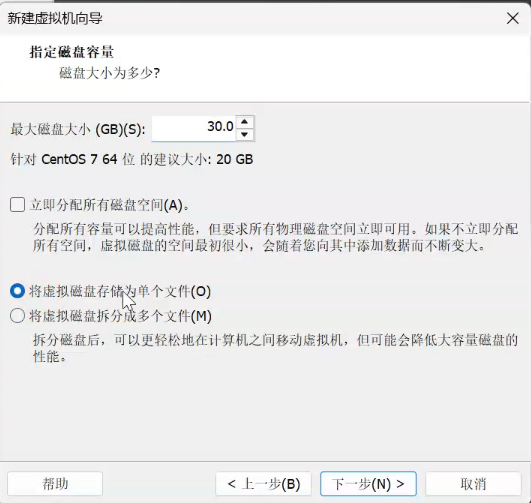
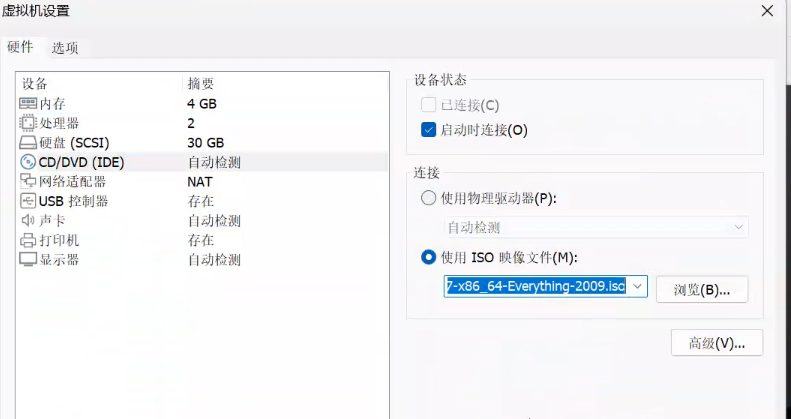
三个虚拟机配置分布式(环境搭建:开发重点)
安装步骤
操作系统环境
操作系统以及软件系统环境搭建
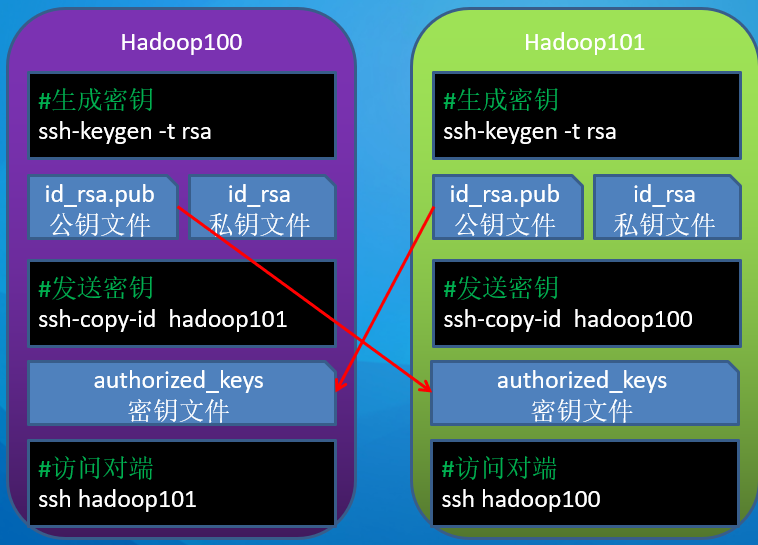
ssh免密操作
hadoop软件
软件安装
集群配置
环境配置
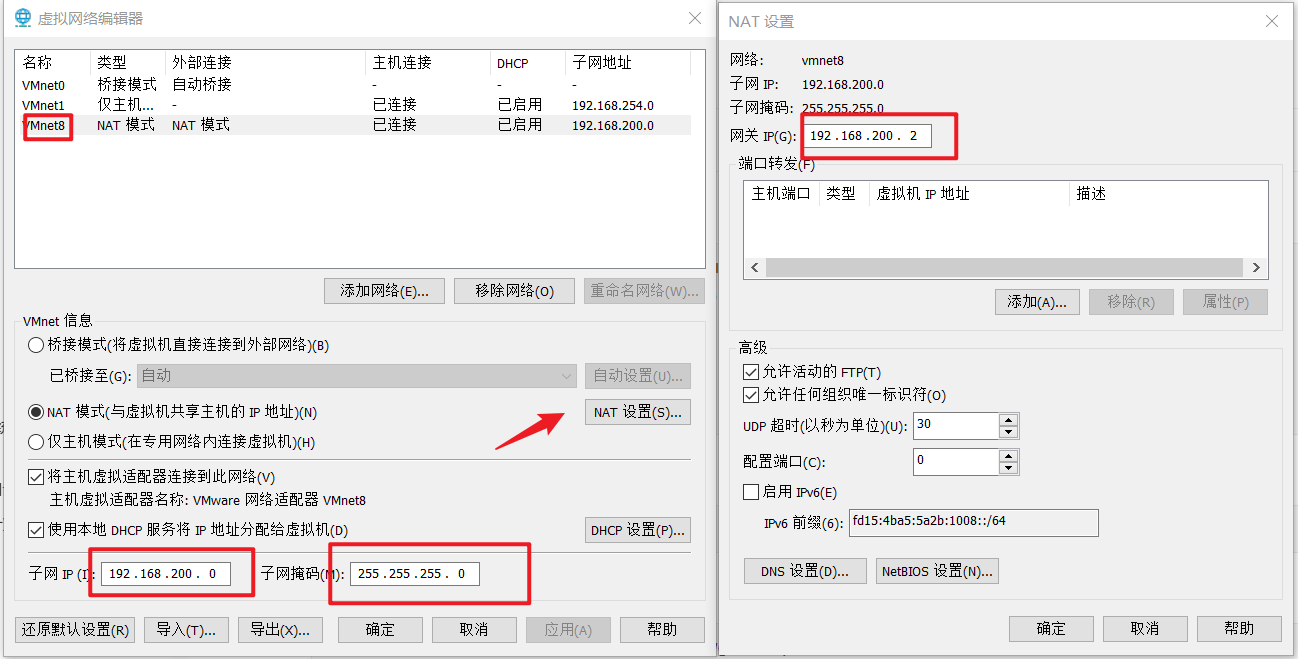
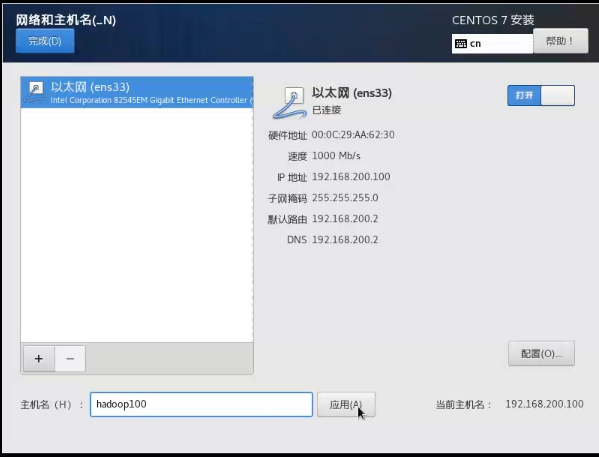
打开虚拟机->2.虚拟网络编辑->3.更改配置->
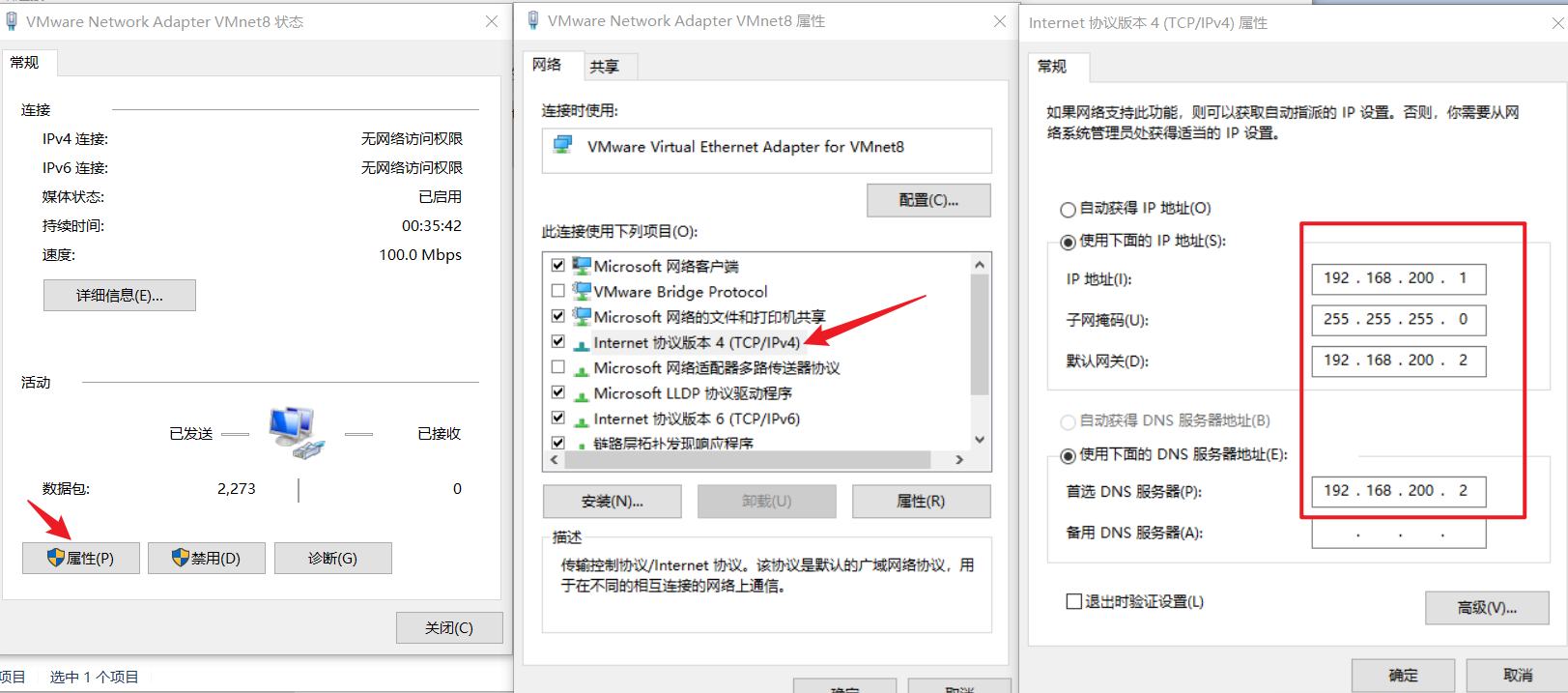
本机网络更改适配器选项,找到
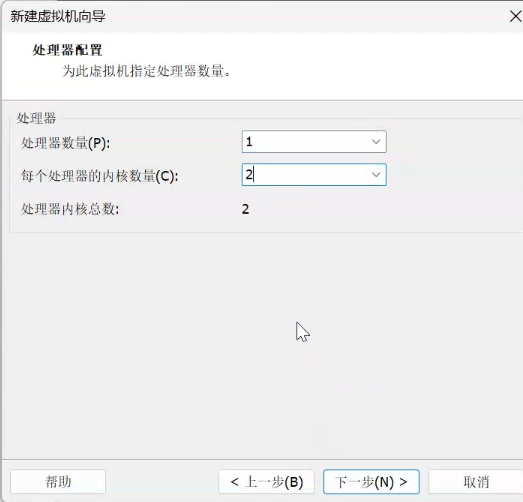
新建虚拟机->稍后安装操作系统->虚拟机名称改为hadoop100,位置改为D:vmware/hadoop100,
启动虚拟机
最小化安装
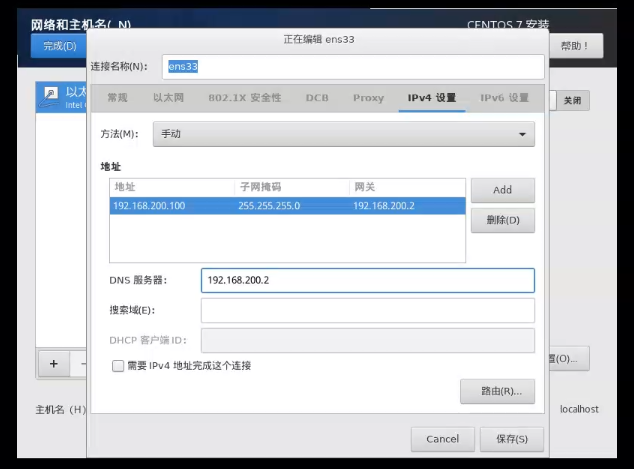
网络配置
开始安装->用户和密码都改为root
软件安装 软件准备/上传文件
jdk-8u212-linux-x64.tar.gz
hadoop-3.1.3.tar.gz
CentOS-Base.repo
hadoop安装过程 系统环境配置
下载源的调整
1 2 3 4 5 6 mv /etc/yum.repos.d/CentOS-Base.reposudo yum clean allsudo yum makecache
安装epel-release(软件仓库)
1 yum install -y epel-release
安装必要工具
1 yum install -y net-tools rsync vim wget ntp
关闭防火墙
1 2 systemctl stop firewalld systemctl disable firewalld.service
关闭selinux
1 2 3 4 vim /etc/selinux/config SELINUX=disabled
软件安装 1 2 3 vim /etc/hosts ip hostname
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/ vim /etc/profile.d/my_env.sh export JAVA_HOME=/opt/module/jdk1.8.0_212export PATH=$PATH :$JAVA_HOME /bintar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ vim /etc/profile.d/my_env.sh export HADOOP_HOME=/opt/module/hadoop-3.1.3export PATH=$PATH :$HADOOP_HOME /binexport PATH=$PATH :$HADOOP_HOME /sbinsource /etc/profilehadoop version
主机克隆操作 1 2 3 4 5 vim /etc/sysconfig/network-scripts/ifcfg-ens33 IPADDR="192.168.200.102" hostnamectl set-hostname hadoop101
SSH协议免密配置 1 2 3 4 ssh-keygen -t rsa ssh-copy-id hadoop100
配置集群文件 core-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://hadoop100:8020</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /opt/module/hadoop-3.1.3/data</value > </property > <property > <name > hadoop.http.staticuser.user</name > <value > root</value > </property > </configuration >
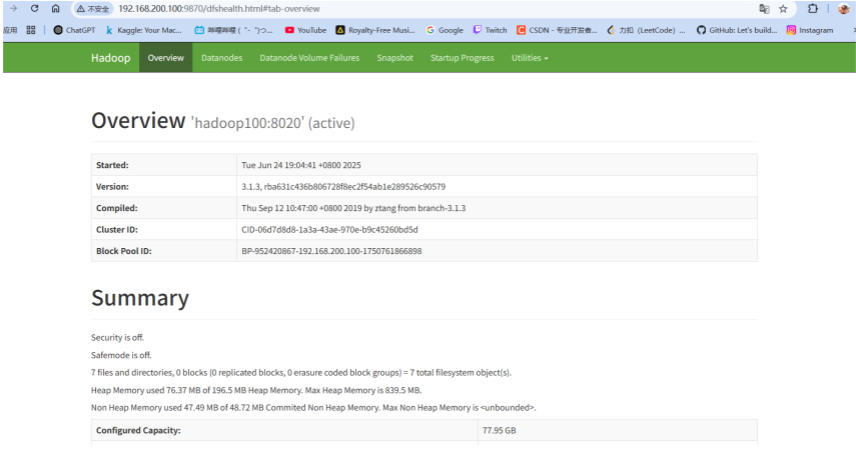
hdfs-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > dfs.namenode.http-address</name > <value > hadoop100:9870</value > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > hadoop102:9868</value > </property > </configuration >
yarn-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.resourcemanager.hostname</name > <value > hadoop101</value > </property > <property > <name > yarn.nodemanager.env-whitelist</name > <value > JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value > </property > </configuration >
mapred-site.xml 1 2 3 4 5 6 7 8 9 10 <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > </configuration >
workers 1 vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
1 2 3 hadoop100 hadoop101 hadoop102
格式化hdfs文件系统(谨慎使用 1 2 3 4 5 hdfs namenode -format hdfs dfsadmin -safemode leave hdfs dfsadmin -safemode forceExit
启动集群 start-dfs.sh stop-dfs.sh 1 2 3 4 5 6 7 8 vim sbin/start-dfs.sh vim sbin/stop-dfs.sh HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh stop-yarn.sh 1 2 3 4 5 6 vim sbin/start-yarn.sh vim sbin/stop-yarn.sh YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
配置历史服务器 mapred-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 vim mapred-site.xml mapred --daemon start historyserver <property > <name > mapreduce.jobhistory.address</name > <value > hadoop100:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > hadoop100:19888</value > </property >
配置历史聚集 yarn-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vim yarn-site.xml <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log.server.url</name > <value > http://hadoop101:19888/jobhistory/logs</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property >
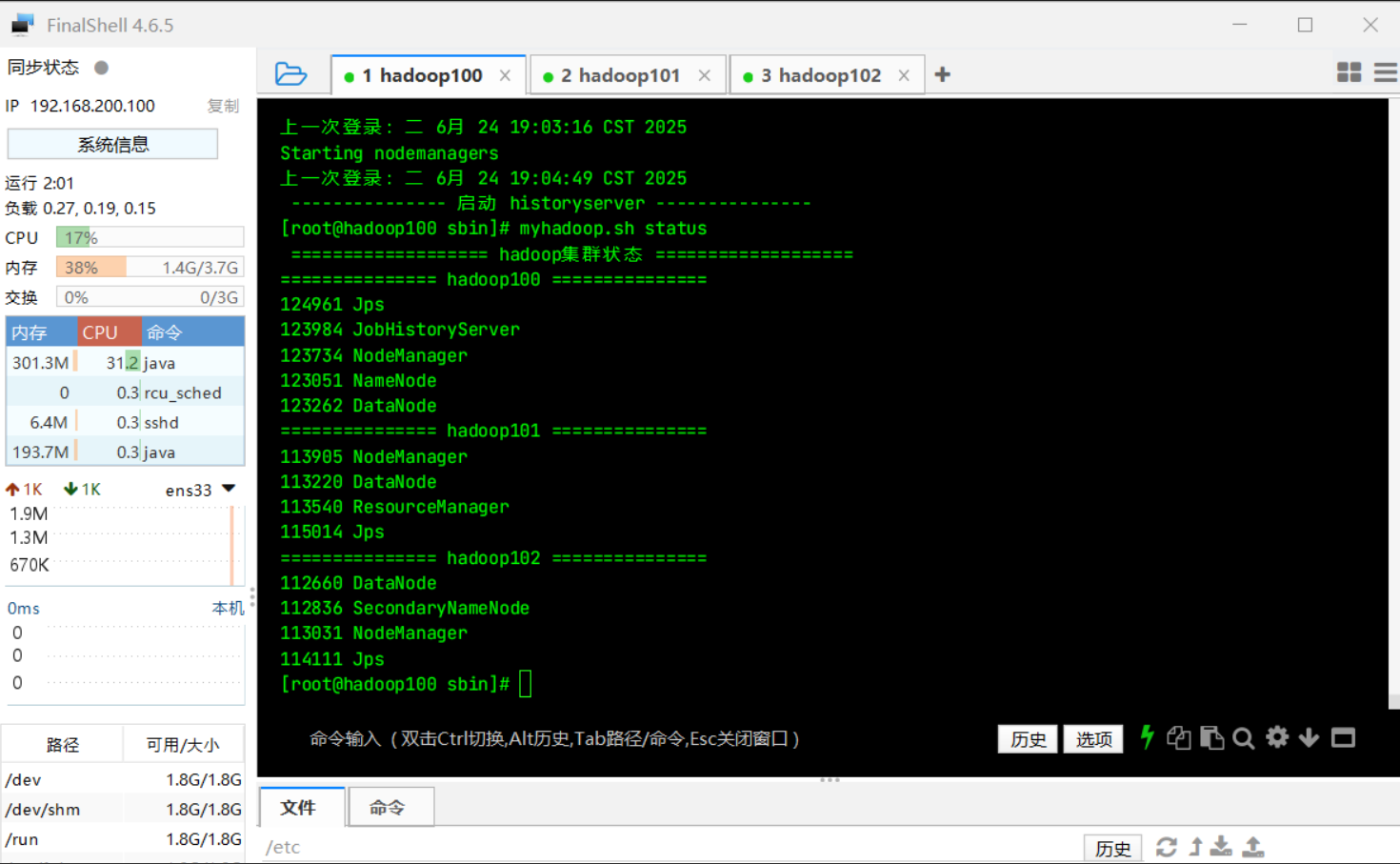
启停脚本 myhadoop.sh 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 # !/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh hadoop100 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh hadoop100 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver" ;; "stop") echo " =================== 关闭 hadoop集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh hadoop100 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh hadoop100 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" ;; "status") echo " =================== hadoop集群状态 ===================" for host in hadoop100 hadoop101 hadoop102 do echo =============== $host =============== ssh $host jps done ;; *) ;; esac
同步脚本 在/root/bin目录下创建xsync文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 # !/bin/bash # 1. 判断参数个数 if [ $# -lt 1 ] then echo "请输入文件目录的路径" exit; fi # 2. 遍历集群所有机器 for host in hadoop100 hadoop101 hadoop102 do echo ==================== $host ==================== #3. 遍历所有⽬录,挨个发送 for file in $@ do #4. 判断⽂件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前⽂件的名称 fname=$(basename $file) rsync -av $pdir/$fname $host:$pdir else echo "文件不存在 $file" fi done done xsync abc
修改脚本xsync具有执行权限
结果截图
hadoop大数据平台-hive组件部署介绍
Hadoop平台-进程启停命令 1 2 3 4 5 6 mapred --daemon start historyserver hdfs --daemon start namenode/datanode/secondarynamenode yarn --daemon start/stop resourcemanager/nodemanager
Hadoop平台-HDFS文件系统命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 -ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]: -mkdir [-p] <path> ...: -moveFromLocal <localsrc> ... <dst>: -moveToLocal <src> <localdst>: -mv <src> ... <dst>: -put [-f] [-p] [-l] [-d] <localsrc> ... <dst>: -renameSnapshot <snapshotDir> <oldName> <newName>: -rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...: -rmdir [--ignore-fail-on-non-empty] <dir > ...: -setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]: -setfattr {-n name [-v value] | -x name} <path>: -setrep [-R] [-w] <rep> <path> ...: -stat [format] <path> ...: -tail [-f] [-s <sleep interval>] <file>: -test -[defsz] <path>: -text [-ignoreCrc] <src> ...: -touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...: -touchz <path> ...: -truncate [-w] <length> <path> ...: -usage [cmd ...]: -appendToFile <localsrc> ... <dst>: -cat [-ignoreCrc] <src> ...: -checksum <src> ...: -chgrp [-R] GROUP PATH...: -chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...: -chown [-R] [OWNER][:[GROUP]] PATH...: -copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>: -copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>: -count [-q] [-h] [-v] [-t [<storage type >]] [-u] [-x] [-e] <path> ...: -cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>: -createSnapshot <snapshotDir> [<snapshotName>]: -deleteSnapshot <snapshotDir> <snapshotName>: -df [-h] [<path> ...]: -du [-s] [-h] [-v] [-x] <path> ...: -expunge: -find <path> ... <expression> ...: -get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>: -getfacl [-R] <path>: -getfattr [-R] {-n name | -d} [-e en] <path>: -getmerge [-nl ] [-skip-empty-file] <src> <localdst>: -head <file>: -help [cmd ...]:
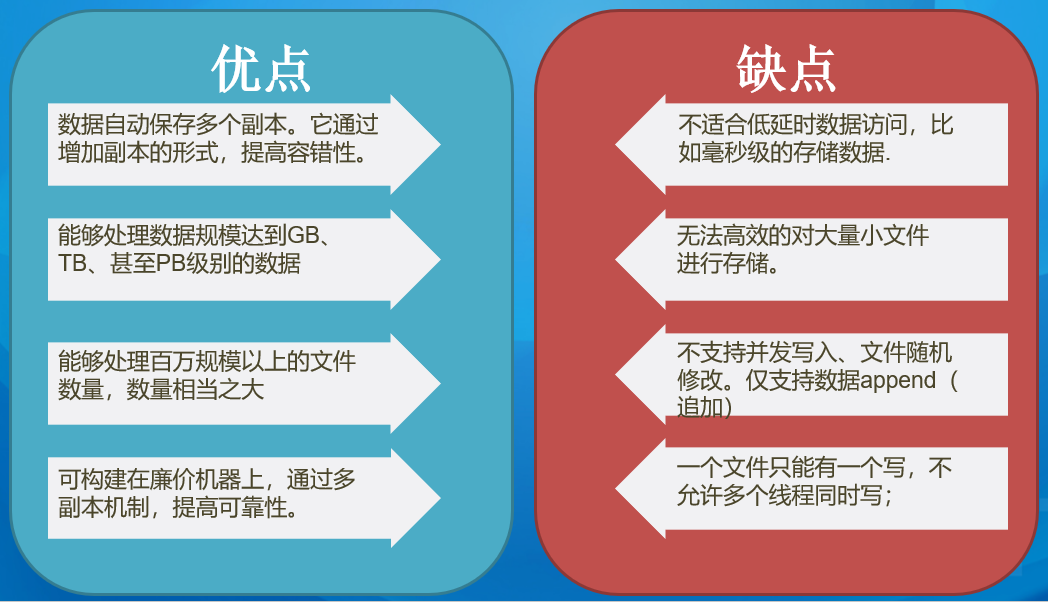
Hadoop平台-HDFS优缺点 HDFS组件用于存储数据,主要由*NameNode,DataNode,SecondaryNameNode 组成
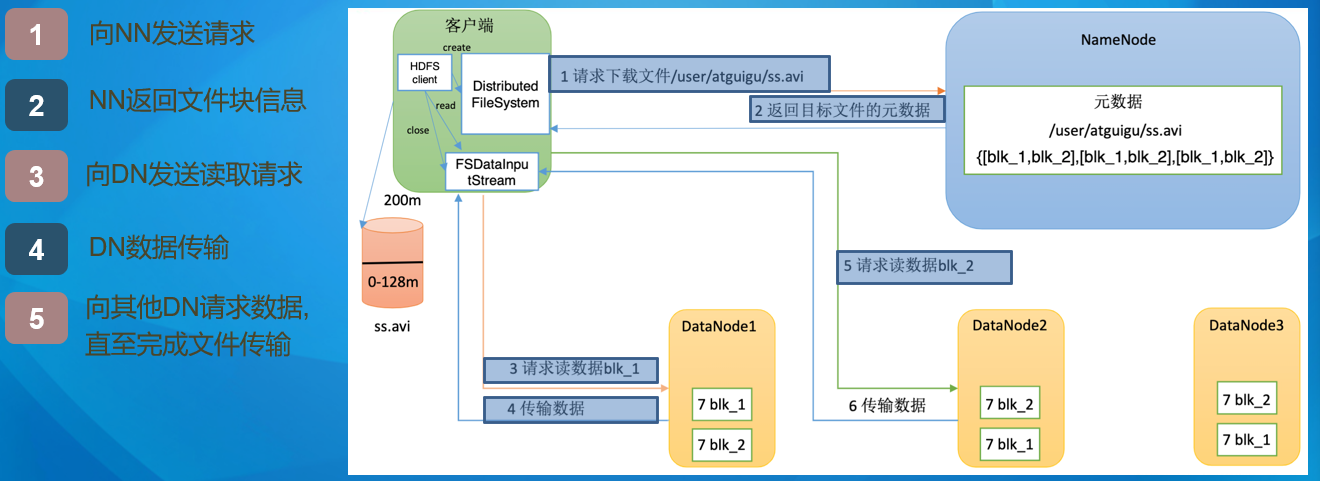
Hadoop平台-HDFS读取流程
Hadoop平台-NameNode更新流程
Hadoop平台-yarn工作流程
Hadoop平台-mapreduce工作流程
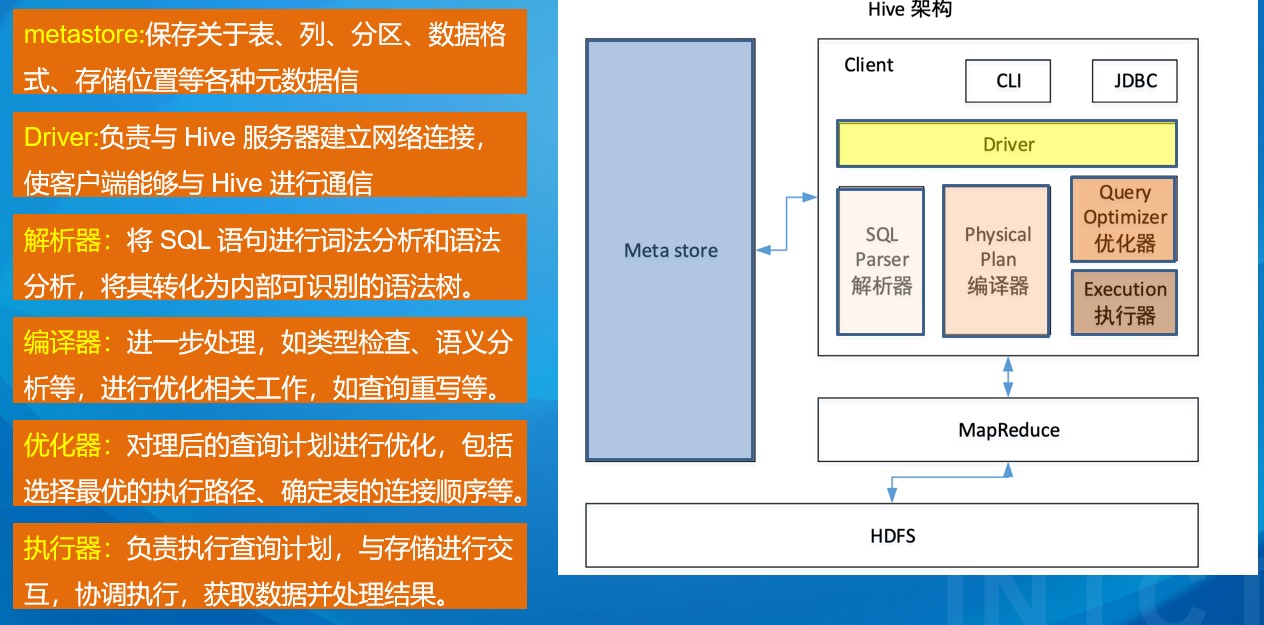
什么是HIVE Hive 是基于 Hadoop 的一个数据仓库工具 。以下是具体介绍:
功能特点 :Hive 可以将结构化的数据文件映射为一张数据库表 ,并提供完整的 SQL 查询功能,能将 SQL 语句转换为 MapReduce 任务进行运行。它允许熟悉 SQL 的用户方便地查询数据,也支持熟悉 MapReduce 的开发者自定义 mapper 和 reducer,以处理复杂的分析工作。优势 :学习成本低,通过类 SQL 语句可快速实现简单的 MapReduce 统计,无需开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。应用场景 :常用于对时效性要求不高的数据分析场景。由于 Hive 底层依赖 Hadoop 的 HDFS 存储数据 ,利用 MapReduce 进行计算,因此能够处理大规模的数据,在处理海量结构化日志的数据统计等方面应用广泛。与数据库的区别 :
数据库一般用于在线应用,支持对某一行或某些行数据的更新、删除等操作,采用 “写时模式”,数据加载慢但查询快。
而 Hive 不支持对具体行的操作,也不支持事务和索引,采用 “读时模式”,适合处理非结构化或存储模式未知的数据,更侧重于对海量数据的批量处理和分析。
HIVE安装 配置mysql安装源 (在线安装方法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 wget https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm yum localinstall mysql57-community-release-el7-11.noarch.rpm rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022 vim /etc/yum.repos.d/mysql-community.repo 修改 baseurl 为 https://mirrors.cloud.tencent.com/mysql/yum/mysql-5.7-community-el7-x86_64/ yum install -y mysql-community-server
安装mysql (本地安装方法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 00#rpm包安装 cd /usr/localtar -zxvf mysql-5.7.22-linux-glibc2.12-x86_64.tar mv mysql-5.7.22-linux-glibc2.12-x86_64 mysql-5.7.22ln -s mysql-5.7.22 mysqlgroupadd mysql useradd -g mysql mysql cd /usr/local/mysqlmkdir datachown -R mysql:mysql ././bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql/m'y' s'q --datadir=/usr/local/mysql/data #将mysql/目录下除了data/目录的所有文件,改回root用户所有 chown -R root . #mysql用户只需作为mysql-5.7.22/data/目录下所有文件的所有者 chown -R mysql data #5.复制启动文件 cp support-files/mysql.server /etc/init.d/mysqld chmod 755 /etc/init.d/mysqld cp bin/my_print_defaults /usr/bin/ #6.修改启动脚本 vi /etc/init.d/mysqld #修改项: basedir=/usr/local/mysql-5.7.22/ datadir=/usr/local/mysql-5.7.22/data port=3306 #加入环境变量,编辑 /etc/profile,这样可以在任何地方用mysql命令了 vi ~/.bash_profile #添加mysql路径,加入下面内容,按ESC-->:wq保存 export PATH=$PATH:/usr/local/mysql-5.7.22/bin #刷新立即生效 source ~/.bash_profile #7.修改mysql配置项 vi /etc/my.cnf #配置如下: [mysqld] basedir = /usr/local/mysql datadir = /usr/local/mysql/data socket = /tmp/mysql.sock user = mysql tmpdir = /tmp symbolic-links=0 [mysqld_safe] log-error = /usr/local/mysql/data/error.log pid-file = /usr/local/mysql/data/mysql.pid #!includedir /etc/my.cnf.d #8.启动mysql service mysqld start #如启动失败,删除 /usr/local/mysql-5.7.22/data下所有文件,重新执行./bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data,再启动 #9.进入mysql修改初始密码,修改远程连接的用户权限问题 mysql -uroot -p ALTER USER ' root'@' localhost' IDENTIFIED BY ' root'; use mysql; UPDATE user SET host=' %' WHERE user=' root'; flush privileges; #开机自启动 chkconfig --add mysqld chkconfig mysqld on chkconfig --list mysqld 0:关 1:关 2:开 3:开 4:开 5:开 6:关
配置mysql
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 systemctl start mysqld systemctl enable mysqld systemctl daemon-reload vim /etc/my.cnf validate_password=OFF systemctl restart mysqld grep 'temporary password' /var/log/mysqld.log mysql -uroot -p ALTER USER 'root' @'localhost' IDENTIFIED BY 'root' ; use mysql; UPDATE user SET host='%' WHERE user='root' ; flush privileges; create database metastore DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
安装HIVE 1 2 3 4 5 6 7 8 9 10 tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/ vim /etc/profile.d/my_env.sh export HIVE_HOME=/opt/module/apache-hive-3.1.2-bin export PATH=$PATH :$HIVE_HOME /bin source /etc/profile
hive基础配置
1 2 3 4 5 mv $HIVE_HOME /lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME /lib/log4j-slf4j-impl-2.10.0.bakcp /opt/software/mysql-connector-java-5.1.27-bin.jar $HIVE_HOME /lib
配置hive-site.xml
挑转到/opt/module/apache-hive-3.1.2-bin/conf/目录新建文件 hive-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 <?xml version="1.0" encoding="utf-8" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > javax.jdo.option.ConnectionURL</name > <value > jdbc:mysql://hadoop100:3306/metastore?useSSL=false</value > </property > <property > <name > javax.jdo.option.ConnectionDriverName</name > <value > com.mysql.jdbc.Driver</value > </property > <property > <name > javax.jdo.option.ConnectionUserName</name > <value > root</value > </property > <property > <name > javax.jdo.option.ConnectionPassword</name > <value > root</value > </property > <property > <name > hive.metastore.schema.verification</name > <value > false</value > </property > <property > <name > hive.metastore.event.db.notification.api.auth</name > <value > false</value > </property > <property > <name > hive.metastore.warehouse.dir</name > <value > /user/hive/warehouse</value > </property > <property > <name > hive.server2.enable.doAs</name > <value > false</value > </property > <property > <name > hive.exec.mode.local.auto</name > <value > true</value > </property > <property > <name > mapred.map.child.java.opts</name > <value > -Xmx2048m</value > </property > </configuration >
初始化Hive元数据库
1 schematool -initSchema -dbType mysql -verbose
优化mapreduce 1 vim $HADOOP_HOME /etc/hadoop/mapred-site.xml
增加配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <property > <name > mapreduce.map.memory.mb</name > <value > 1536</value > </property > <property > <name > mapreduce.map.java.opts</name > <value > -Xmx1024M</value > </property > <property > <name > mapreduce.reduce.memory.mb</name > <value > 3072</value > </property > <property > <name > mapreduce.reduce.java.opts</name > <value > -Xmx2560M</value > </property >
配置beeline 配置core-site.xml 使其任意节点都可以访问hadoop
1 2 3 4 5 6 7 8 <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property>
启动 hiveserver2
1 2 3 4 hiveserver2 nohup hiveserver2 &
登录命令
1 2 beeline -u jdbc:hive2://localhost:10000 -n root -p 123456 [密码随意] beeline -u jdbc:hive2://localhost:10000 -n root -p 123456 -e 'show tables;'
dbeaver登录
获取文件 hadoop-common-3.1.3.jar
获取文件 hive-jdbc-3.1.2-standalone.jar
添加hive数据库链接
hive 数据操作语句元数据查看语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 show database db_hiveshow databases like 'db_hive*' ;desc database db_hivedesc database extended db_hive;show tables;desc dept;desc extended emp;show formatted emp;show partitions emp;
建库操作 1 2 3 4 5 CREATE DATABASE [IF NOT EXISTS ] database_name[COMMENT database_comment] [LOCATION hdfs_path]
建表操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 CREATE [EXTERNAL ] TABLE [IF NOT EXISTS ] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC | DESC ], ...)] INTO num_buckets BUCKETS] [ROW FORMAT DELIMITED [FIELDS TERMINATED BY char ] [COLLECTION ITEMS TERMINATED BY char ] [MAP KEYS TERMINATED BY char ] [LINES TERMINATED BY char ]] [STORED AS file_format] [LOCATION hdfs_path] [TBLPROPERTIES (property_name= property_value, ...)] [AS select_statement]
上传数据 1 2 3 4 5 6 7 8 9 10 11 load data [local ] inpath '数据的path' [overwrite] into table student [partition (partcol1= val1,…)]; dfs - put / opt/ module / hive/ datas/ student.txt / user / atguigu/ hive; insert into table student_par values (1 ,'wangwu' ),(2 ,'zhaoliu' );insert overwrite table student_par select id, name from student ;
下载数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 insert overwrite local directory '数据的path' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' dql_command;dfs - get / user / hive/ warehouse/ student/ student.txt / opt/ module / datas/ export/ student3.txt;bin/ hive - e 'select * from default.student;' > / opt/ module / hive/ datas/ export/ student4.txt; export table default.student to '/user/hive/warehouse/export/student' ;
select语句 1 2 3 4 5 6 7 8 9 SELECT [ALL | DISTINCT ] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [ORDER BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ] [LIMIT number]
Hive复合数据类型
数组array : array<value数据类型>
相同数据类型
有序的排列
下标为数字
1 2 3 4 5 select a_score[0 ] from student2select array (值,值) from student
集合struct : struct<key值:value数据类型,key值:value数据类型>
预定义个数
预定义顺序
key预定义
数据类型可不同
1 2 3 4 5 6 select s_score.chinese from student2select named_struct(key,value ,key,value )from student
字典map : map<key数据类型,value数据类型>
标准字典类型
key自定义
数据类型可不同
个数不限
1 2 3 4 5 6 select m_score['语文' ] from student2select map(key,value ,key,value )from student
hive 内置函数1 2 3 4 5 6 show functions;desc function upper;desc function extended upper;
python连接hive linux环境安装python 1 2 3 4 5 6 7 8 9 10 11 12 13 wget https://www.python.org/ftp/python/3.9.0/Python-3.9.0.tgz wget https://www.python.org/ftp/python/3.9.9/Python-3.9.9.tgz tar -zxvf Python-3.9.10.tgz -C /opt/module/ yum install openssl-devel libffi-devel bzip2-devel gcc gcc-c++ wget -y ./configure --enable-optimizations make altinstall
配置环境变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vim /etc/profile.d/my_env.sh PATH=$PATH :/opt/python39/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin source /etc/profilecp libpython3.9.a /usr/lib64/ln -s /root/software/python3.9/Python-3.9.10/python /usr/bin/python3ln -s /opt/module/Python-3.9.10/python /usr/bin/python3
安装pyhive库 1 2 3 4 5 6 7 8 9 10 11 pip3 install -i https://mirrors.aliyun.com/pypi/simple/ thrift pip3 install -i https://mirrors.aliyun.com/pypi/simple/ thrift-sasl pip3 install -i https://mirrors.aliyun.com/pypi/simple/ PyHive pip3 install -i https://mirrors.aliyun.com/pypi/simple/ PyM from pyhive import hiveconn=hive.connect(host='localhost' ,port=10000 ,username='root' ,database='db_hive' ) cursor=conn.cursor() sql='show tables' cursor.execute(sql) print (cursor.fetchall())
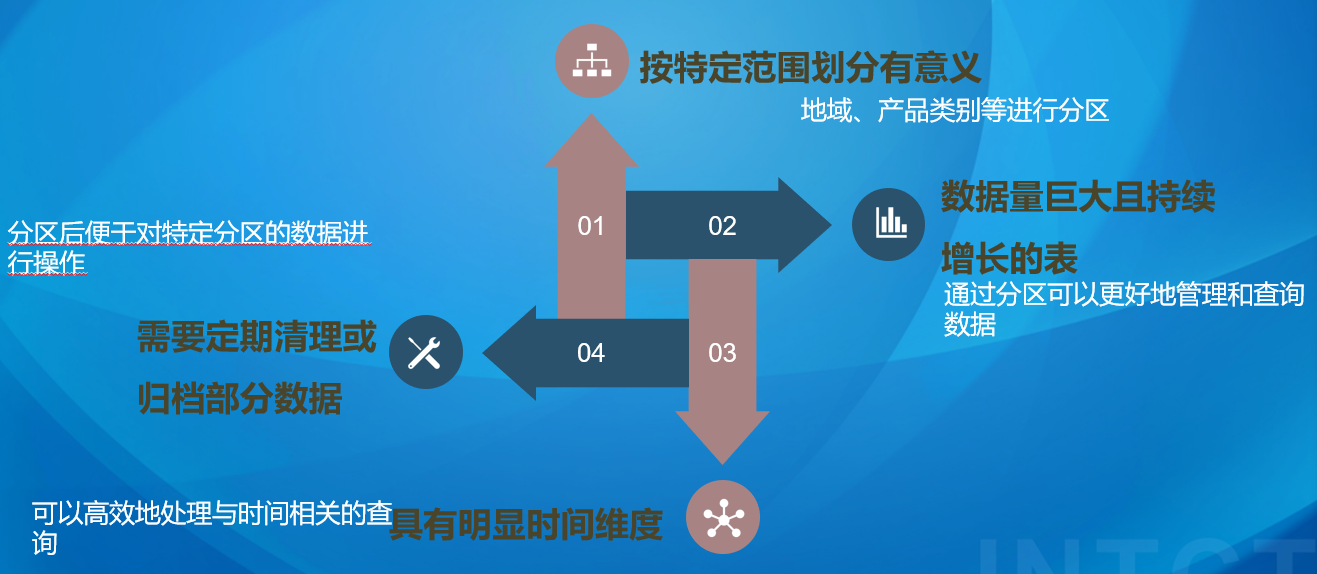
分区表
分区应用场景
oracle 分区表种类
范围分区 (range)列表分区 (list)散列分区 (hash)组合组合分区 (subpartition)
oracle 分区-范围分区1 2 3 4 5 6 7 8 9 10 11 12 13 14 CREATE TABLE ORDER_ACTIVITIES ( ORDER_ID NUMBER(7 ) NOT NULL , ORDER_DATE DATE , TOTAL_AMOUNT NUMBER, CUSTOTMER_ID NUMBER(7 ), PAID CHAR (1 ) ) PARTITION BY RANGE (ORDER_DATE) ( PARTITION ORD_ACT_PART01 VALUES LESS THAN (TO_DATE('01- MAY -2003' ,'DD-MON-YYYY' )) TABLESPACE ORD_TS01, PARTITION ORD_ACT_PART02 VALUES LESS THAN (TO_DATE('01-JUN-2003' ,'DD-MON-YYYY' )) TABLESPACE ORD_TS02, PARTITION ORD_ACT_PART02 VALUES LESS THAN (MAXVALUE) TABLESPACE ORD_TS03 );
oracle分区-列表分区 1 2 3 4 5 6 7 8 CREATE TABLE ORDER_ACTIVITIES ( PROBLEM_ID NUMBER(7 ) NOT NULL PRIMARY KEY , CUSTOMER_ID NUMBER(7 ) NOT NULL , STATUS VARCHAR2(20 )) PARTITION BY LIST (STATUS) ( PARTITION PROB_ACTIVE VALUES ('ACTIVE' ) TABLESPACE PROB_TS01, PARTITION PROB_INACTIVE VALUES ('INACTIVE' ,'unknow' ) TABLESPACE PROB_TS02 );
oracle分区-散列分区 1 2 3 4 5 6 7 8 9 10 CREATE TABLE HASH_TABLE ( COL NUMBER(8 ), INF VARCHAR2(100 ) ) PARTITION BY HASH (COL) ( PARTITION PART01 TABLESPACE HASH_TS01, PARTITION PART02 TABLESPACE HASH_TS02, PARTITION PART03 TABLESPACE HASH_TS03 )
oracle 分区-组合分区1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 CREATE TABLE SALES ( PRODUCT_ID VARCHAR2(5 ), SALES_DATE DATE , SALES_COST NUMBER(10 ), STATUS VARCHAR2(20 ) ) PARTITION BY RANGE (SALES_DATE) SUBPARTITION BY LIST (STATUS) ( PARTITION P1 VALUES LESS THAN(TO_DATE('2003-01-01' ,'YYYY-MM-DD' ))TABLESPACE rptfact2009 ( SUBPARTITION P1SUB1 VALUES ('ACTIVE' ) TABLESPACE rptfact2009, SUBPARTITION P1SUB2 VALUES ('INACTIVE' ) TABLESPACE rptfact2009 ), PARTITION P2 VALUES LESS THAN (TO_DATE('2003-03-01' ,'YYYY-MM-DD' )) TABLESPACE rptfact2009 ( SUBPARTITION P2SUB1 VALUES ('ACTIVE' ) TABLESPACE rptfact2009, SUBPARTITION P2SUB2 VALUES ('INACTIVE' ) TABLESPACE rptfact2009 ) )
oracle 分区-分区表操作1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ALTER TABLE SALES ADD PARTITION P3 VALUES LESS THAN(TO_DATE('2003-06-01' ,'YYYY-MM-DD' )); ALTER TABLE SALES MODIFY PARTITION P3 ADD SUBPARTITION P3SUB1 VALUES ('COMPLETE' ); ALTER TABLE SALES DROP PARTITION P3; ALTER TABLE SALES DROP SUBPARTITION P4SUB1;ALTER TABLE table_name EXCHANGE PARTITION partition_name WITH TABLE nonpartition_name;
hive分区-创建分区表 在 Hadoop 中,Hive 分区表通常以特定的目录结构来存储。
每个分区对应一个独立的目录,目录名通常包含分区列的值。数据文件会存储在相应的分区目录下。
1 2 3 4 5 6 7 create table dept_partition(deptno int , dname string, loc string ) partitioned by (day string) row format delimited fields terminated by '\t' ;
hive分区-分区表操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 load data local inpath '/opt/module/hive/datas/dept_20200401.log' into table dept_partition partition (day = '20200401' ); insert into table log_list_6 partition (dat= '20221231' ) select * from log_list_tmpfrom student insert overwrite table student partition (month = '201707' )select id, name where month = '201707' insert overwrite table student partition (month = '201706' )select id, name where month = '201706' ; show partitions tab_name;alter table dept_partition add partition (day = '20200404' ) ;alter table dept_partition add partition (day = '20200405' ) partition (day = '20200406' );alter table dept_partition drop partition (day = '20200406' );show partitions dept_partition;desc formatted dept_partition;ALTER TABLE table_name PARTITION (dt= '2008-08-08' ) SET LOCATION "new location";ALTER TABLE table_name PARTITION (dt= '2008-08-08' ) RENAME TO PARTITION (dt= '20080808' );
超市分区表示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 create table supermarket_p (id string, ord_id string comment '订单 ID' , ord_date string comment '订单日期' , exch_date string comment '发货日期' , exch_type string comment '邮寄方式' , cust_id string comment '客户 ID ' , cust_name string comment '客户名称' , d_type string comment '细分' , city string comment '城市' , prov string comment '省/自治区' , country string comment'国家' , area string comment '地区' , pro_id string comment '产品 ID' , type1 string comment '类别' , type2 string comment '子类别' , pro_name string comment '产品名称' , sales float comment '销售额' , count1 int comment '数量 ' , discount float comment '折扣 ' , profit float comment '利润' ) partitioned by (c_type1 string) row format delimited fields terminated by '\t'
动态分区配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 --开启动态分区(默认开启) set hive.exec.dynamic.partition=true --指定非严格模式 nonstrict模式表示允许所有的分区字段都可以使用动态分区 set hive.exec.dynamic.partition.mode=nonstrict--在所有执行MR的节点上,最大一共可以创建多少个动态分区。默认1000 set hive.exec.max.dynamic.partitions=1000--在每个执行MR的节点上,最大可以创建多少个动态分区(分区字段有多少种设多少个) set hive.exec.max.dynamic.partitions.pernode=100--整个MR Job中,最大可以创建多少个HDFS文件。默认100000 set hive.exec.max.created.files=100000--当有空分区生成时,是否抛出异常 set hive.error.on.empty.partition=false --打开正则查询模式`(dt|hr)?+.+` set hive.support.quoted.identifiers=none
分桶表
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分区针对的是数据的存储路径 ;分桶针对的是数据文件 。
分桶表注意事项
分桶策略
Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方 式决定该条记录存放在哪个桶当中
==reduce的个数设置为-1,让Job自行决定需要用多少个reduce或者将reduce的个数设置为大于等于分桶表的桶数==
==从hdfs中load数据到分桶表中,避免本地文件找不到问题 ==
==不要使用本地模式 ==
hive分桶表-创建分桶表 1 2 3 4 5 6 7 8 9 10 11 12 create table stu_bucket(id int , name string)clustered by (id) into 4 bucketsrow format delimited fields terminated by '\t' ;set mapreduce.job.reduces= 3 set mapred.reduce.tasks= 3 load data inpath '/student.txt' into table stu_bucket;
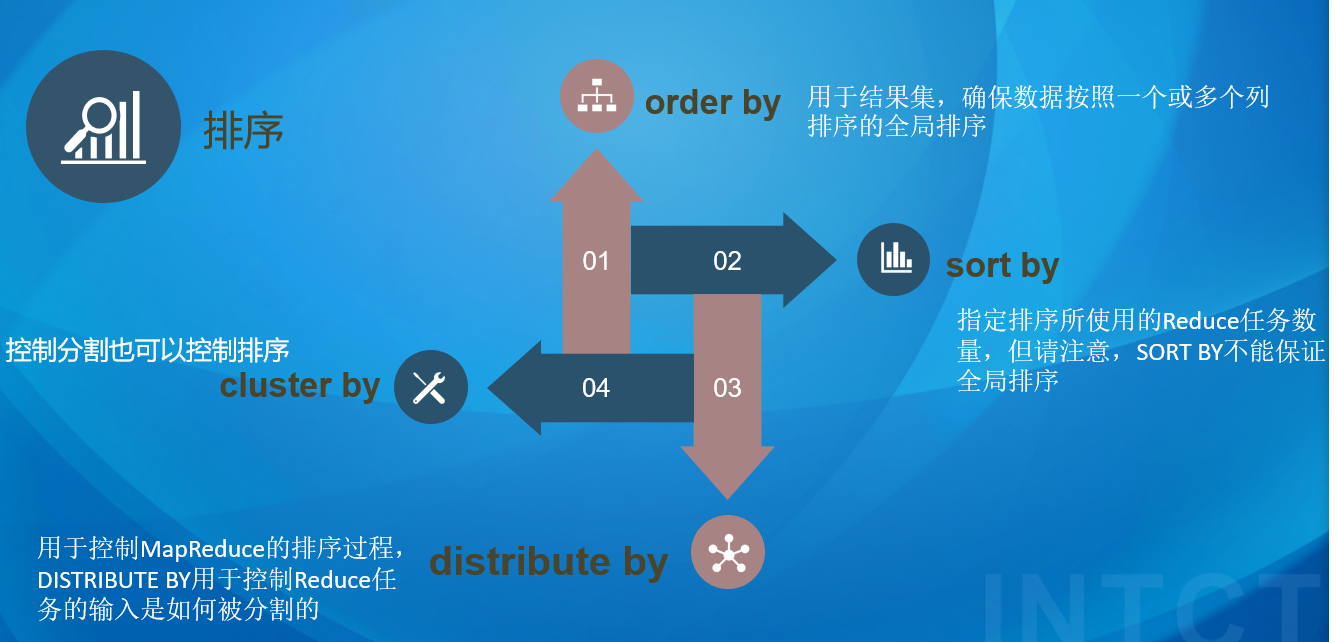
hive排序关键字
##hive****排序语句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 select * from student2 order by idselect * from student2 sort by class_name desc set mapreduce.job.reduces= 15 ;select * from student2 distribute by class_name sort by id desc insert overwrite local directory '/root/student2/' row format delimited fields terminated by '\t' select * from student2_b distribute by sex sort by chinese desc select * from student2 cluster by class_name
使用awk 清洗 log 1 2 3 4 5 6 7 8 9 10 11 cat 2021-05-20.log | awk -F "\"-\"" '{split($1, arr, " ");\ split(substr(arr[4],2),dd,":");\ split(dd[1],ee,"/");\ print arr[1]"\t"ee[1]"- "ee[2]"-"ee[3]" "dd[2]":"dd[3]":"dd[4]"\t"arr[7]"\t"$2}' | \awk -F "\t" '{"date -d \""$2"\" +%Y%m%d%H%M%S" | getline d;print $1"\t"d"\t"$3"\t"$4 }' | \awk -F "\t" '{print $1"\t"$2"\t"$3"\t"(index($4,"Windows")?"Windows": (index($4,"Linux")?"Linux":"Mac"))"\t"(index($4,"Chrome")?"Chrome": (index($4,"Version")?"Safari":(index($4,"Firefox")?"Firefox":"Opera")))}' >new_2021-05-20.log
sqoop
安装sqoop
sqoop介绍
Sqoop 是 Apache 旗下一款专为 Hadoop 设计的数据同步工具 ,全称为 “SQL to Hadoop”,主要用于在关系型数据库 (如 MySQL、Oracle)和Hadoop 生态系统 (如 HDFS、Hive、HBase)之间高效传输数据。它通过 MapReduce 任务并行处理数据,支持大规模数据的批量导入导出,是 Hadoop 生态中连接结构化数据和非结构化数据的重要桥梁。
核心功能与特点
数据导入(Import)
支持增量导入 :可基于时间戳或主键增量同步变化的数据。并行处理 :通过 MapReduce 并行读取数据库分片,提升传输效率。
数据导出(Export) 多种数据库支持 元数据映射 与 Hadoop 生态集成
总结
sqoop使用
安装
配置mysql
1 2 3 4 5 6 7 8 9 10 11 create database testDEFAULT CHARACTER SET utf8DEFAULT COLLATE utf8_general_ci;show databases;Create user 'test' @'%' identified by 'test' ;Grant all privileges on test.* to test@'%' identified by 'test' with grant option; flush privileges;
1 2 3 4 5 6 7 8 9 10 11 12 13 tar -zvxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/ vim /etc/profile.d/my_env.sh export SQOOP_HOME=/opt/module/sqoop-1.4.6.bin__hadoop-2.0.4-alphaexport PATH=$PATH :$SQOOP_HOME /binsource /etc/profile
安装sqoop 1 2 3 4 5 6 7 8 9 10 11 cd $SQOOP_HOME /confcp sqoop-env-template.sh sqoop-env.shexport HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3export HIVE_HOME=/opt/module/apache-hive-3.1.2-bincp mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/lib/
4.测试连接
1 sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username root --password root
分区重构 1 2 beeline -u "jdbc:hive2://hadoop100:10000/db_hive" \ --outputformat=csv2 --showHeader=false -n root -p 123456 -e "msck repair table log_sqoop"
DataX 项目地址:https://github.com/alibaba/DataX https://github.com/alibaba/DataX/blob/master/introduction.md
DataX 是阿里巴巴开源的一个异构数据源离线同步工具 ,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件 ,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
安装 datax 确保hadoop集群没有问题
将 datax.tar.gz 上传到 hadoop100 的 /root目录下, 解压安装
1 2 3 tar -zxvf datax.tar.gz -C /opt/moudule xsync /opt/moudule/datax
编写配置文件 开发目录
1 2 3 4 mkdir -p /zhiyun/lijinquancd /zhiyun/lijinquanmkdir jobs sql python shell data
datax的配置文件需要放在 jobs 目录下
1 vim /zhiyun/lijinquan/jobs/c_org_busi.json
加入内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 { "job" : { "setting" : { "speed" : { "channel" : 3 } , "errorLimit" : { "record" : 0 , "percentage" : 0.02 } } , "content" : [ { "reader" : { "name" : "mysqlreader" , "parameter" : { "username" : "zhiyun" , "password" : "zhiyun" , "column" : [ "*" ] , "connection" : [ { "table" : [ "c_org_busi" ] , "jdbcUrl" : [ "jdbc:mysql://192.168.50.179:3306/his?useSSL=false" ] } ] } } , "writer" : { "name" : "hdfswriter" , "parameter" : { "defaultFS" : "hdfs://hadoop100:8020" , "fileType" : "orc" , "path" : "/zhiyun/lijinquan/ods/c_org_busi" , "fileName" : "c_org_busi.data" , "column" : [ { "name" : "col1" , "type" : "TINYINT" } , .. ] , "writeMode" : "truncate`" , "fieldDelimiter" : "\t" } } } ] } }
运行
1 python /opt/datax/bin/datax.py /zhiyun/lijinquan/jobs/c_org_busi.json
列名的处理
1 2 1. 一个列一个列的处理 2. vscode多行编辑 alt+shift+鼠标拖动
抽取 c_org_busi 表
1 2 3 4 5 您配置的path: [/zhiyun/lijinquan/ods/c_org_busi] 不存在, 请先在hive端创建对应的数据库和表. datax不会自动创建HDFS上的路径, 需要手动创建 hadoop fs -mkdir -p /zhiyun/lijinquan/ods/c_org_busi
确保抽取成功, 没有报错
Hive建表 1 2 3 4 5 6 7 8 9 10 create database if not exists ods_lijinquan location "/zhiyun/lijinquan/ods";create external table if not exists ods_lijinquan.c_org_busi(... ) row format delimited fields terminated by "\t" lines terminated by "\n" stored as orc location "/zhiyun/lijinquan/ods/c_org_busi";
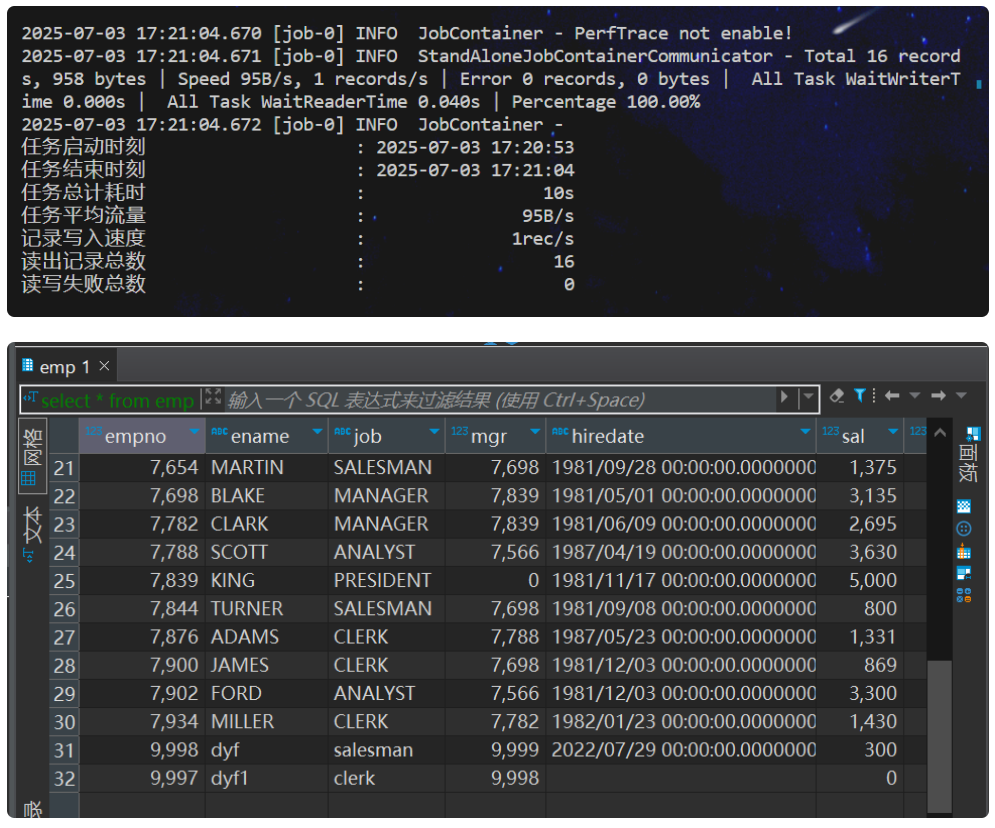
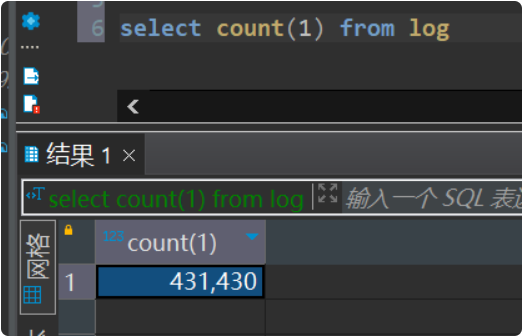
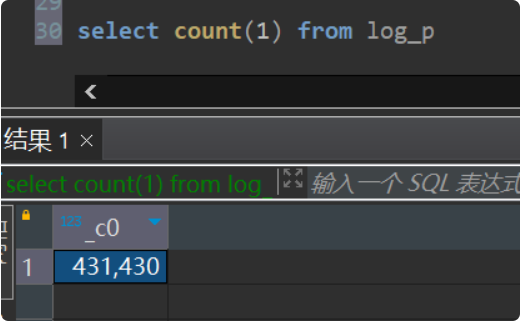
验证数据 1 2 select * from ods_lijinquan.c_org_busi limit 1 ;select count (1 ) from ods_lijinquan.c_org_busi;
调度平台的安装 将目录 \07_医药\xxl-job-student-20221220上传到 hadoop100的 /opt目录下
1 2 3 4 5 6 7 8 mv /opt/xxl-job-student-20221220 /opt/xxljobmysql -uroot -proot source /opt/xxljob/tables_xxl_job.sql;quit;
编写启停脚本
内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 # !/bin/bash act=$1 start(){ echo "starting xxl-job" ssh root@hadoop100 "cd /opt/xxljob; nohup java -jar xxl-job-admin-2.3.0.jar > xxl-job.log 2>&1 &" ssh root@hadoop100 "cd /opt/xxljob; nohup java -jar xxl-job-executor-sample-springboot-2.3.0.jar > xxl-job-executor.log 2>&1 &" ssh root@hadoop101 "cd /opt/xxljob; nohup java -jar xxl-job-executor-sample-springboot-2.3.0.jar > xxl-job-executor.log 2>&1 &" ssh root@hadoop102 "cd /opt/xxljob; nohup java -jar xxl-job-executor-sample-springboot-2.3.0.jar > xxl-job-executor.log 2>&1 &" } stop(){ echo "stopping xxl-job" ssh root@hadoop100 "ps -aux | grep xxl-job-admin | grep -v grep | awk '{print \$2}' | xargs kill -9" ssh root@hadoop100 "ps -aux | grep xxl-job-executor-sample | grep -v grep | awk '{print \$2}' | xargs kill -9" ssh root@hadoop101 "ps -aux | grep xxl-job-executor-sample | grep -v grep | awk '{print \$2}' | xargs kill -9" ssh root@hadoop102 "ps -aux | grep xxl-job-executor-sample | grep -v grep | awk '{print \$2}' | xargs kill -9" } status(){ echo "=============== hadoop102 =================" ssh root@hadoop102 "ps -aux | grep xxl-job-executor-sample | grep -v grep" echo "=============== hadoop101 =================" ssh root@hadoop101 "ps -aux | grep xxl-job-executor-sample | grep -v grep" echo "=============== hadoop100 =================" ssh root@hadoop100 "ps -aux | grep xxl-job | grep -v grep" } case $act in start) start status ;; stop) stop status ;; restart) stop start status ;; status) status ;; esac
加权限
使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 同步 xsync /opt/xxljob # 启动 xxl start =============== hadoop102 ================= root 2340 0.0 1.2 2679420 22952 ? Sl 15:40 0:00 java -jar xxl-job-executor-sample-springboot-2.3.0.jar =============== hadoop101 ================= root 2293 134 2.2 2679420 42324 ? Sl 15:40 0:01 java -jar xxl-job-executor-sample-springboot-2.3.0.jar =============== hadoop100 ================= root 20685 146 2.0 2679452 38340 ? Sl 15:40 0:01 java -jar xxl-job-admin-2.3.0.jar root 20710 150 2.1 2679424 40340 ? Sl 15:40 0:01 java -jar xxl-job-executor-sample-springboot-2.3.0.jar # 状态 xxl status
等到 8080 端口启动成功后, 可以访问:
http://192.168.200.100:8080/xxl-job-admin
登录 admin / 123456
执行器: 调度平台会随机使用任一执行器去执行任务
Hive 表导出到 MySQL 数据库 test_read_hdfs.json将 HDFS 中的数据同步到 MySQL 数据库
从 HDFS 路径 /user/hive/warehouse/db_hive.db/sqoop_emp 读取数据
按制表符分隔解析文本行,提取 8 个字段
通过 3 个并发通道将数据传输到 MySQL
将数据插入到 MySQL 的 test.emp 表中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 { "job" : { "setting" : { "speed" : { "channel" : 3 } } , "content" : [ { "reader" : { "name" : "hdfsreader" , "parameter" : { "path" : "/user/hive/warehouse/db_hive.db/sqoop_emp" , "defaultFS" : "hdfs://hadoop100:8020" , "column" : [ { "index" : 0 , "type" : "string" } , { "index" : 1 , "type" : "string" } , { "index" : 2 , "type" : "string" } , { "index" : 3 , "type" : "string" } , { "index" : 4 , "type" : "string" } , { "index" : 5 , "type" : "string" } , { "index" : 6 , "type" : "string" } , { "index" : 7 , "type" : "string" } ] , "fileType" : "text" , "encoding" : "UTF-8" , "fieldDelimiter" : "\t" } } , "writer" : { "name" : "mysqlwriter" , "parameter" : { "writeMode" : "insert" , "username" : "test" , "password" : "test" , "column" : [ "empno" , "ename" , "job" , "mgr" , "hiredate" , "sal" , "comm" , "deptno" ] , "session" : [ "set session sql_mode='ANSI'" ] , "connection" : [ { "jdbcUrl" : "jdbc:mysql://hadoop100:3306/test?useSSL=False&useUnicode=true&characterEncoding=utf-8" , "table" : [ "emp" ] } ] } } } ] } }
exp_log.sh
生成配置文件 :根据传入的日期分区参数 $1,动态生成 DataX 配置文件 exp_log.json,配置从 HDFS 读取指定日期分区的数据,并写入 MySQL 表。创建目标表 :在 MySQL 中创建 log 表(如果不存在),定义五个 VARCHAR 类型的字段用于存储日志数据。执行数据同步 :调用 DataX 工具执行数据导出任务,将 HDFS 上的文本格式数据(/user/hive/warehouse/db_hive.db/log/dt=$part)按字段映射关系写入 MySQL 的 log 表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 #!/bin/bash part=$1 echo '{ "job": { "setting": { "speed": { "channel": 3 } }, "content": [ { "reader": { "name": "hdfsreader", "parameter": { "path": "/user/hive/warehouse/db_hive.db/log/dt=' $part '", "defaultFS": "hdfs://hadoop100:8020", "column": [ { "index": 0, "type": "string" }, { "index": 1, "type": "string" }, { "index": 2, "type": "string" }, { "index": 3, "type": "string" }, { "index": 4, "type": "string" } ], "fileType": "text", "encoding": "UTF-8", "fieldDelimiter": "\t" } }, "writer": { "name": "mysqlwriter", "parameter": { "writeMode": "insert", "username": "test", "password": "test", "column": [ "ip", "date_l", "url", "osinfo", "bowser" ], "session": [ "set session sql_mode=' "'ANSI'" '" ], "connection": [ { "jdbcUrl": "jdbc:mysql://hadoop100:3306/test?useSSL=False&useUnicode=true&characterEncoding=utf-8", "table": [ "log" ] } ] } } } ] } }' > /root/datax/json/exp_log.jsonmysql -utest -ptest --database=test -e \ 'create table if not exists log ( ip varchar(500), date_l varchar(500), url varchar(500), osinfo varchar(500), bowser varchar(500) )' /usr/local/bin/python3.9 /opt/module/datax/bin/datax.py /root/datax/json/exp_log.json
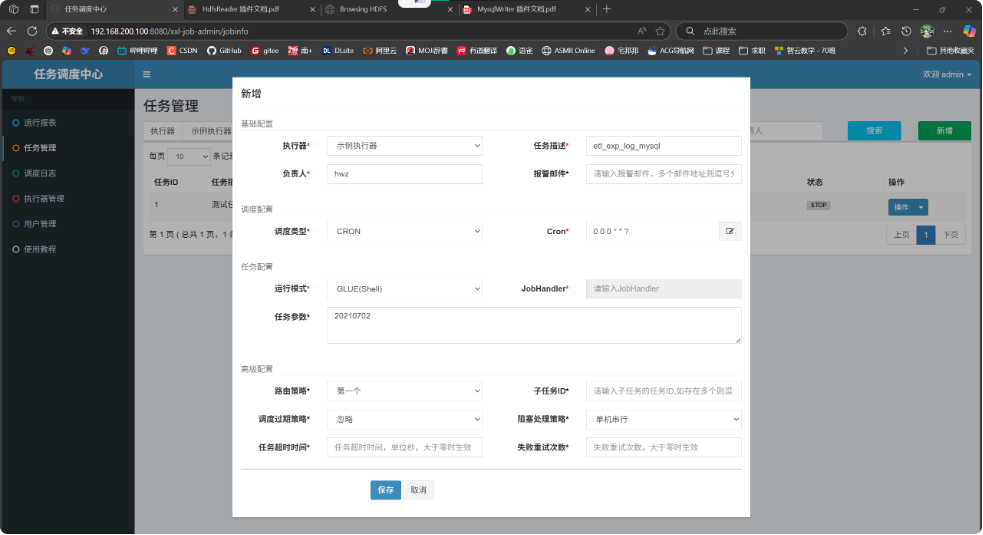
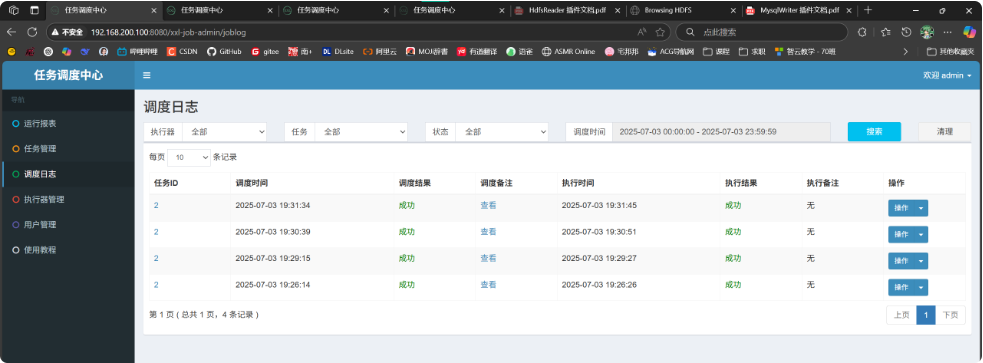
xxl-job-任务调度中心-新增任务管理
GLUE IDE
1 2 3 4 5 6 7 8 9 10 #!/bin/bash echo "xxl-job: hello shell" echo "脚本位置:$0 " echo "任务参数:$1 " echo "分片序号 = $2 " echo "分片总数 = $3 " /root/datax/shell/exp_log.sh $1 echo "Good bye!" exit 0
分别手动执行一次\
mysql.test中查询log数据量
动态分区表导入导出 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 { "job" : { "setting" : { "speed" : { "channel" : 3 } , "errorLimit" : { "record" : 0 , "percentage" : 0.02 } } , "content" : [ { "reader" : { "name" : "mysqlreader" , "parameter" : { "username" : "test" , "password" : "test" , "column" : [ "*" ] , "splitPk" : "db_id" , "connection" : [ { "querySql" : [ "select * from log where osinfo = 'Windows';" ] , "jdbcUrl" : [ "jjdbc:mysql://hadoop100:3306/test?useSSL=False&useUnicode=true&characterEncoding=utf-8" ] } ] } } , "writer" : { "name" : "hdfswriter" , "parameter" : { "defaultFS" : "hdfs://hadoop100:8020" , "fileType" : "orc" , "path" : "/user/hive/warehouse/db_hive.db/log_tmp" , "fileName" : "log_p" , "column" : [ { "name" : "ip" , "type" : "string" } , { "name" : "date_l" , "type" : "string" } , { "name" : "url" , "type" : "string" } , { "name" : "osinfo" , "type" : "string" } , { "name" : "browser" , "type" : "string" } ] , "writeMode" : "truncate" , "fieldDelimiter" : "\t" , "compress" : "NONE" } } } ] } }
在db_hive中建log_temp表
1 2 3 4 5 6 7 8 9 10 11 12 create table log_tmp( ip string, date_l string, url string, osinfo string, browser string ) row format delimitedfields terminated by '\t' lines terminated by '\n' stored as orc
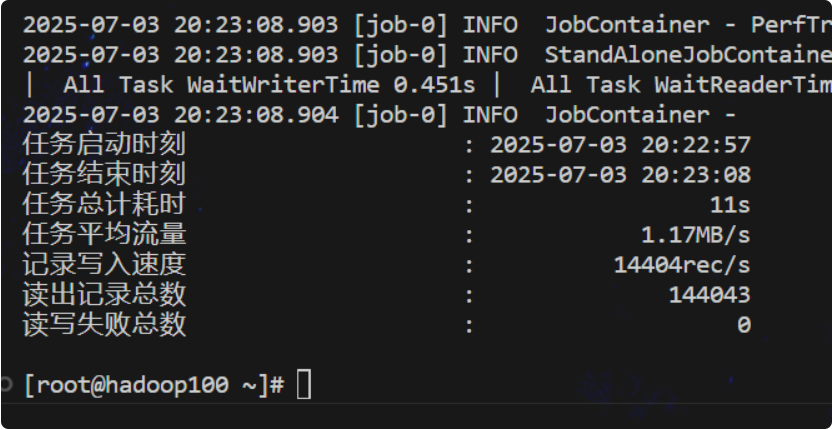
运行脚本/usr/local/bin/python3.9 /opt/module/datax/bin/datax.py /root/datax/json/imp_log.json
imp_log.sh
JSON 配置文件生成 :创建 DataX 任务配置文件 imp_log.json,配置从 MySQL 读取数据并写入 HDFS 的 ORC 文件格式。Hive 表创建:使用 Beeline 连接 Hive,创建两个 ORC 格式的表:
log_tmp:临时表,用于存储从 MySQL 导入的原始数据log_p:分区表,按操作系统类型 (os_tp) 分区
数据抽取与导入 :调用 DataX 工具执行数据同步任务,将 MySQL 的 log 表数据导入到 Hive 的 log_tmp 表。动态分区插入 :配置 Hive 动态分区参数,将 log_tmp 表的数据按 osinfo 字段的值自动分配到 log_tmp2 表的不同分区中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 #!/bin/bash echo ' { "job": { "setting": { "speed": { "channel": 3 }, "errorLimit": { "record": 0, "percentage": 0.02 } }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "test", "password": "test", "column": [ "*" ], //"splitPk": "db_id", "connection": [ { "table": [ "log;" ], "jdbcUrl": [ "jdbc:mysql://hadoop100:3306/test?useSSL=False&useUnicode=true&characterEncoding=utf-8" ] } ] } }, "writer": { "name": "hdfswriter", "parameter": { "defaultFS": "hdfs://hadoop100:8020", "fileType": "orc", "path": "/user/hive/warehouse/db_hive.db/log_tmp", "fileName": "log_tmp", "column": [ { "name": "ip", "type": "string" }, { "name": "date_l", "type": "string" }, { "name": "url", "type": "string" }, { "name": "osinfo", "type": "string" }, { "name": "browser", "type": "string" } ], "writeMode": "truncate", "fieldDelimiter": "\t", "compress": "NONE" } } } ] } }' > /root/datax/json/imp_log.jsonbeeline -u jdbc:hive2://hadoop100:10000/db_hive -u root -p 545456 -e \ "CREATE TABLE if not exists log_tmp( ip string, date_l string, url string, osinfo string, browser string ) row format delimited fields terminated by '\t' lines TERMINATED by '\n' STORED AS orc; CREATE TABLE if not exists log_p( ip string, date_l string, url string, osinfo string, browser string ) partitioned by (os_tp string) row format delimited fields terminated by '\t' lines TERMINATED by '\n' STORED AS orc " echo '*******************建表完成--***********************' /bin/python3 /opt/module/datax/bin/datax.py /root/datax/json/imp_log.json echo '*****************数据导入成功************************' beeline -u jdbc:hive2://hadoop100:10000/db_hive -u root -p 545456 -e \ " set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; set hive.exec.max.dynamic.partitions=200; set hive.exec.max.dynamic.partitions.pernode=50; set hive.exec.max.created.files=1000; set hive.error.on.empty.partition=false; set hive.support.quoted.identifiers=none; insert into log_p partition (os_tp) select l.*,osinfo from log_tmp l; " echo '------------------完成------------------'