
亚马逊商品需求
需求
- 打开亚马逊网址
- 根据制定的大类类目,去每个小类目下统计Best Sellers前100名产品的商品ID、标题、图片、价格、链接
- 把相应信息写进数据库
- 把本次写入的数据跟上次写入的数据做分析
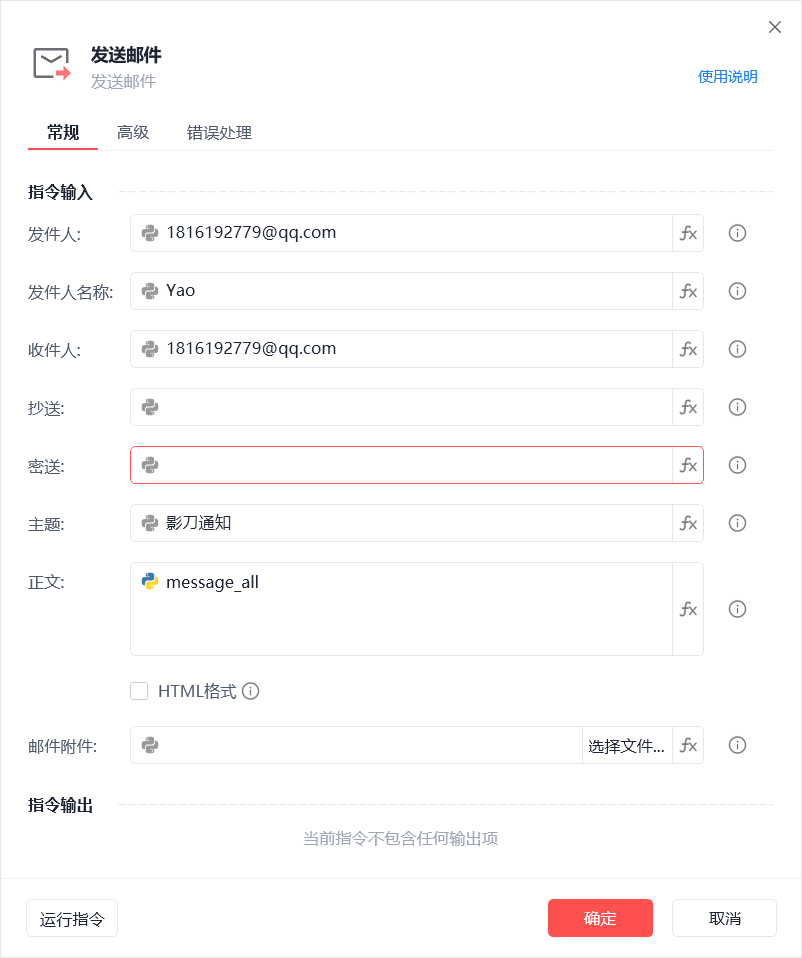
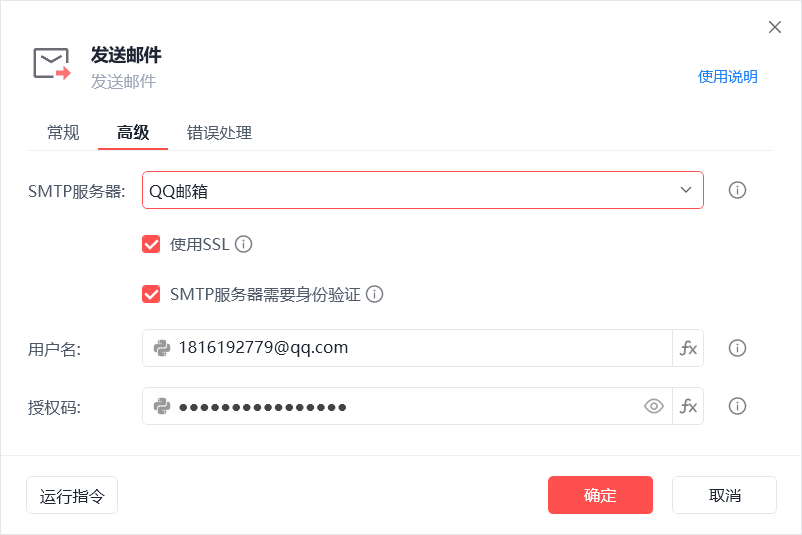
- 把有新冲上来的链接、哪条链接调价的结果,发消息通知我 (短信/微信/钉钉/系统通知/QQ邮箱)
表设计
1 | CREATE TABLE amazon_items ( |
流程
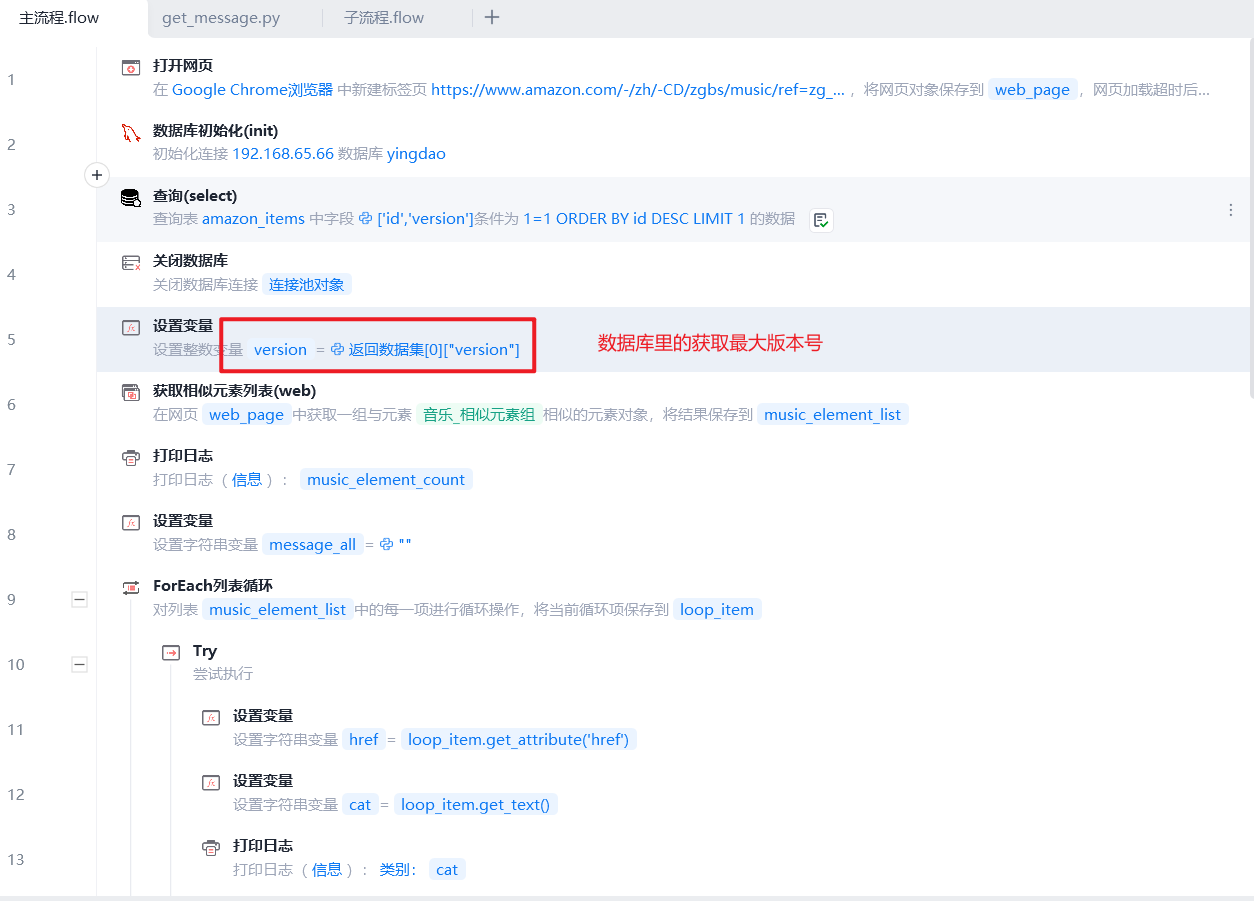
主流程:
- 连接数据库,获取最大版本号
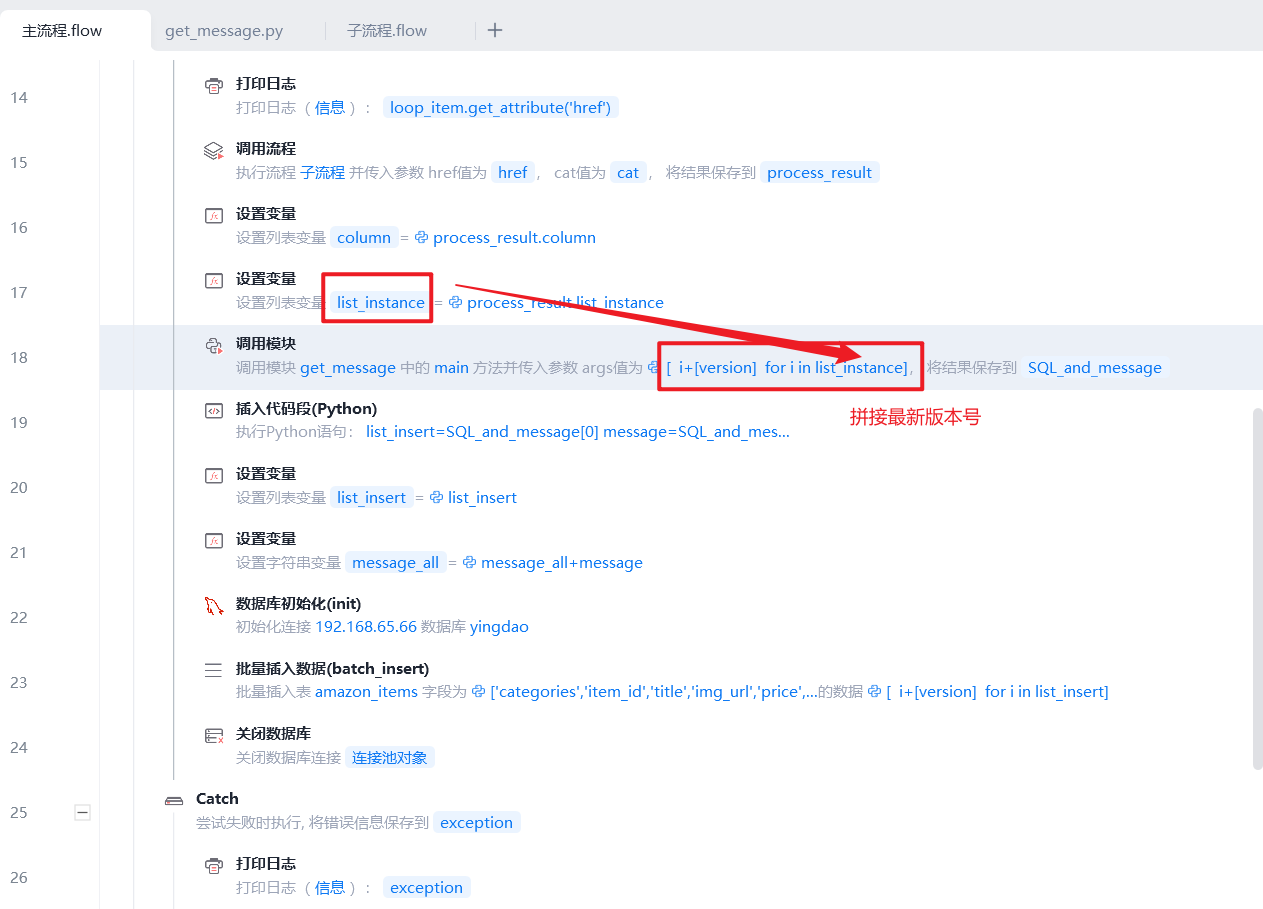
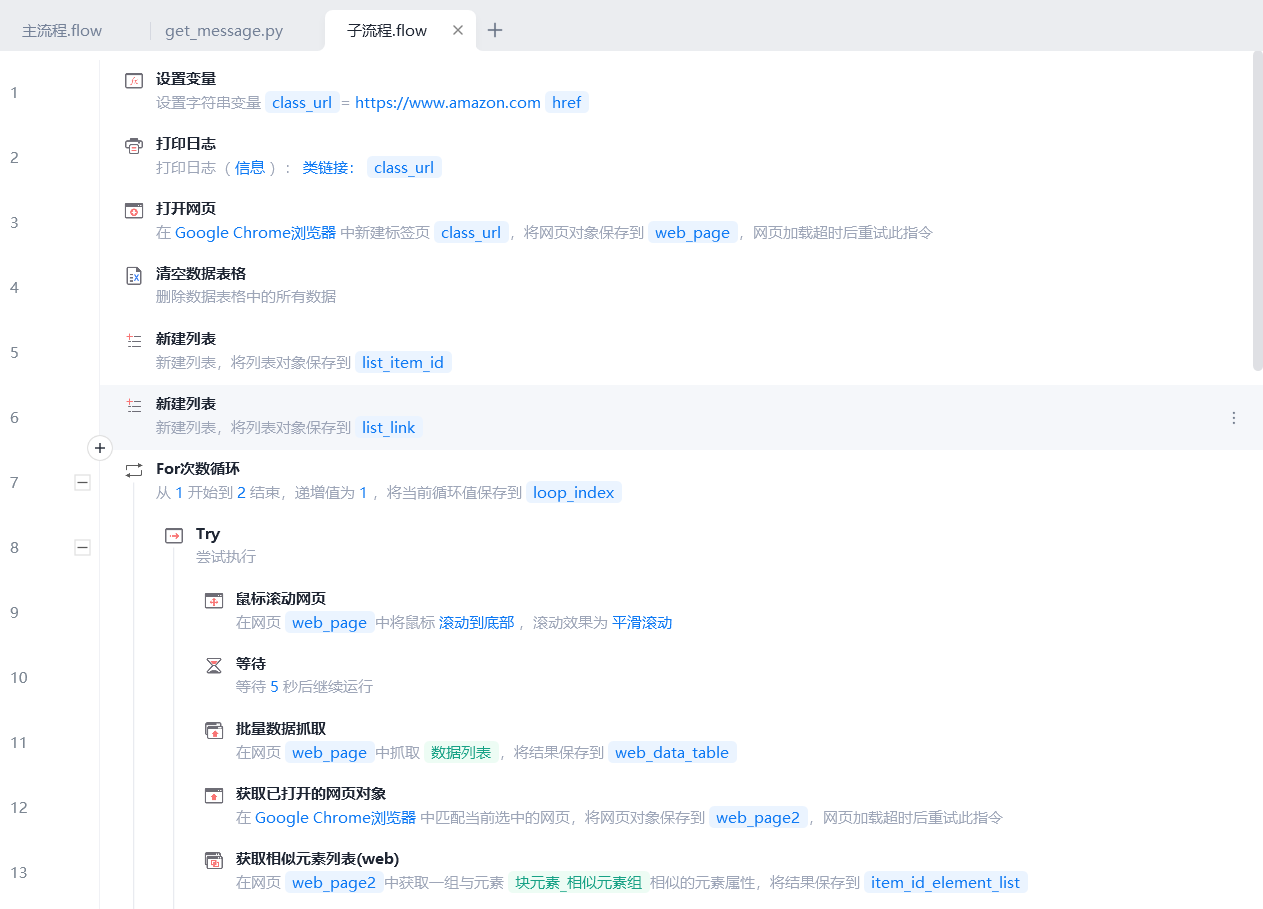
- 打开⼤类⽹⻚,获取⼦类相似元素, ForEach 循坏,获取其⽂本内容可取出⼦类标题 categories (即分类)和item_id,由于后⾯获取和存储其他商品详情在⼦流程中进⾏。编写了子流程.flow(用于获取要爬取的数据列表)和get_message.flow(用于输出要插入的数据列表和输出要更新的信息)
- 最终的数据列表插入数据库
- 发送信息

子流程:
- 拼接要访问的url
- 打开子类网页
- 新建全局列表list_item_id和list_link用于追加数据
- 设置点击下一页的循环次数
- 滚动网页到底部,等待加载,批量爬取数据
- 清洗批量爬取的数据,把US$29.90的字符串转化为float类型的29.90
- 拼接所有列表为数据库表名的字段的顺序的格式
- 输出最终列表
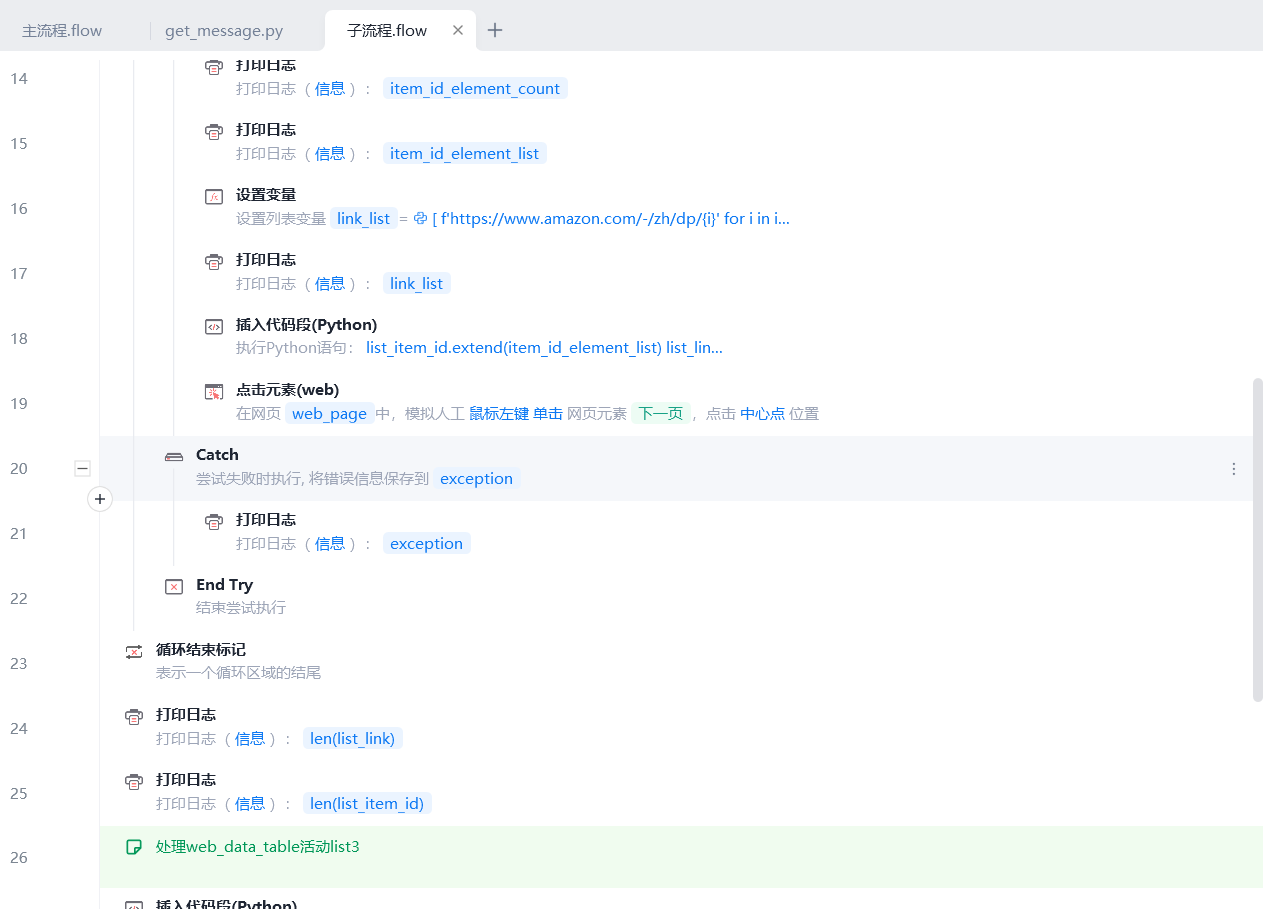
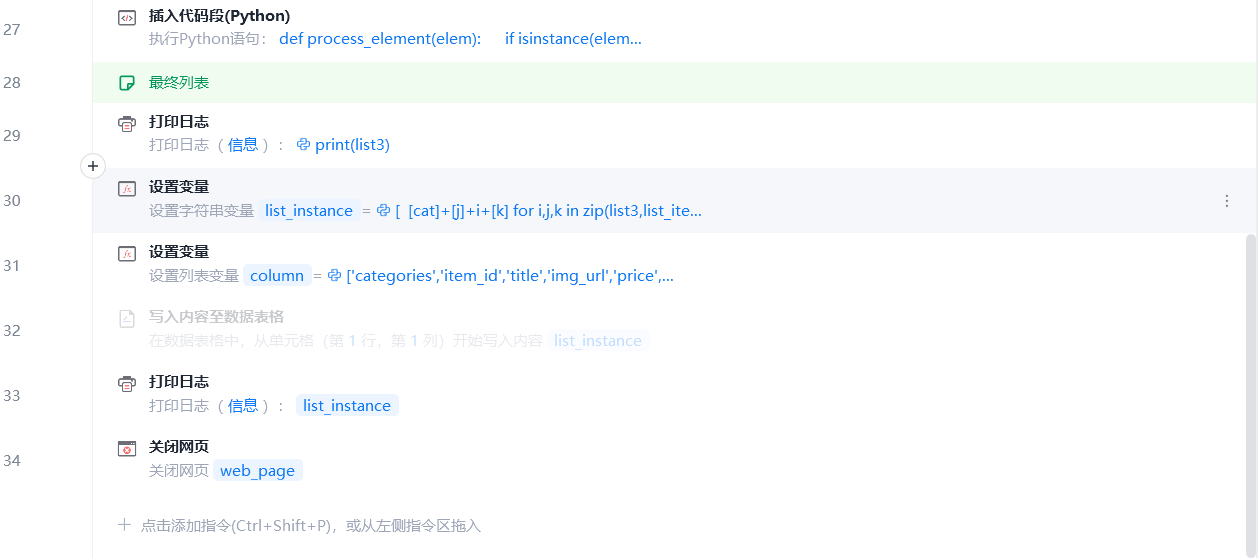
插入的代码块用于清洗数据
1 | def process_element(elem): |
get_message子模块:
- 连接数据库执行以下sql语句找出每个item_id最大版本的记录
1
2
3
4
5
6SELECT categories,a.item_id,title,img_url,price,link,a.version
FROM amazon_items a JOIN (
SELECT item_id, MAX(version) AS max_version FROM amazon_items GROUP BY
item_id
) s
ON a.item_id = s.item_id AND a.version = s.max_version; - 检查价格是否相同,价格不同,更新版本号并添加调价消息
- 反向删除需要移除的项,避免索引变化问题
- message处理成这样的格式:
1
message += f"有上新:【分类:{categories},商品id:{item_id},标题:{title},价格:{price},链接:{link}】\n"
- 返回要更新列表reslist和要发送的信息message
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
import pymysql
DBconnnectDict={
"host":'192.168.65.66',
"user":'Yao',
"passwd":'123456',
"db":'yingdao'
}
# 非空返回查询语句元组
def get_select_result():
try:
# 建立数据库连接
connection = pymysql.connect(
host=DBconnnectDict["host"],
port=3306,
user=DBconnnectDict["user"],
passwd=DBconnnectDict["passwd"],
db=DBconnnectDict["db"],
charset='utf8'
)
# 创建游标对象
cursor=connection.cursor()
# 定义SQL查询语句
sql="""
SELECT categories,a.item_id,title,img_url,price,link,a.version
FROM amazon_items a JOIN (
SELECT item_id, MAX(version) AS max_version FROM amazon_items GROUP BY
item_id
) s
ON a.item_id = s.item_id AND a.version = s.max_version;
"""
# 执行SQL查询
cursor.execute(sql)
# 获取查询结果(以列表形式保存)
result_list = cursor.fetchall()
# 如果需要将每条记录转换为字典(包含字段名),可以使用以下代码
# columns = [desc[0] for desc in cursor.description]
# result_list = [dict(zip(columns, row)) for row in cursor.fetchall()]
print(f"查询成功,共获取 {len(result_list)} 条记录")
except pymysql.MySQLError as e:
print(f"数据库操作出错: {e}")
result_list = [] # 出错时返回空列表
finally:
# 关闭游标和连接
if 'cursor' in locals() and cursor:
cursor.close()
if 'connection' in locals() and connection:
connection.close()
return result_list
def update_version_list(reslist):
result_tuple=get_select_result()
# 创建res_select 中商品ID 到版本号和价格的映射
print(result_tuple)
res_map = {}
for item in result_tuple:
categories, item_id, title, img_url, price, link, version = item
res_map[item_id] = (price, int(version))
# 初始化消息变量
message = ""
# 用于存储需要删除的reslist 索引
indices_to_remove = []
# 处理调价和相同价格的情况
for i, item in enumerate(reslist):
categories, item_id, title, img_url, price, link, version = item
if item_id in res_map:
res_price, res_version = res_map[item_id]
# 检查价格是否相同
if price == res_price:
indices_to_remove.append(i)
else:
# 价格不同,更新版本号并添加调价消息
new_version = res_version + 1
reslist[i][6] = str(new_version) # 更新版本号
message += f"有调价:【分类:{categories},商品id:{item_id},标题:{title},价格:{res_price}→{price},链接:{link}】\n"
# 反向删除需要移除的项,避免索引变化问题
for i in sorted(indices_to_remove, reverse=True):
del reslist[i]
# 处理上新的情况
res_ids = set(res_map.keys())
new_items = [item for item in reslist if item[1] not in res_ids]
for item in new_items:
categories, item_id, title, img_url, price, link, version = item
message += f"有上新:【分类:{categories},商品id:{item_id},标题:{title},价格:{price},链接:{link}】\n"
return reslist,message
def main(args):
"""
[['R&B','B0FHJ7BCJ3','Here For It All','https://images-na.ssl-images-amazon.com/images/I/61e7eyCsIfL._AC_UL600_SR600,400_.jpg',19.98,'https://www.amazon.com/-/zh/dp/B0FHJ7BCJ3',1]]
"""
reslist,message=update_version_list(args)
print(reslist)
print(message)
return reslist,message
结果
信息通知结果:
数据库查询结果: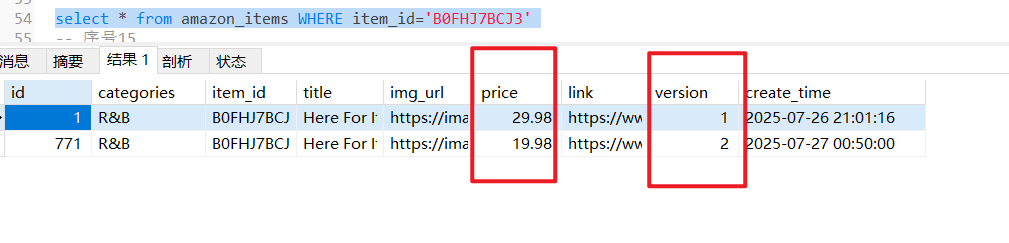
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Yinjin Yao的博客!
相关推荐

2025-05-28
Python
国内常用镜像源12345678910111213清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/阿里云:http://mirrors.aliyun.com/pypi/simple/中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/华中科技大学:http://pypi.hustunique.com/豆瓣源:http://pypi.douban.com/simple/腾讯源:http://mirrors.cloud.tencent.com/pypi/simple华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/ 数据类型 数字型: bool int float ⾮数字型: str list tuple set dict ⽇期型: time datetime 例子: 123456sno=1age=18sname="小明"high=1.786print(f"{sname&#...

2025-07-24
京东RPA爬虫
需求12345678910商品 ID item_id 商品链接 item_link 标题 item_title ⻔店名称 store 封⾯ cover_link 原价 original_cost 折扣价 discount_cost 品牌 brand 型号 type 评论数 comments mysql数据库建表1234567891011121314151617CREATE TABLE IF NOT EXISTS `jd_items` ( `id` INT NOT NULL AUTO_INCREMENT COMMENT '自增主键', `item_id` varchar(255) NOT NULL COMMENT '商品ID', `item_link` varchar(255) NOT NULL COMMENT '地址 http开头', `store` varchar(64) NOT NULL COMMENT '门店名称', `title` varchar(255) NOT NULL COM...

2025-07-28
医药器械法规数据爬取
名词解释需求 法律法规知识库的建立 AI环境与知识库 扣子AI智能体应用与系统集成 功能需求:实现输⼊商品信息接⼝ , 提交商品后根据现有法律法规判断商品是否 %%{init: {"flowchart": {"useMaxWidth": true}}}%% graph LR 系统A-->AI平台; 系统B-->AI平台; 系统C-->AI平台; 其他-->A工平台; AI平台-->知识库; AI平台-->AI大模型; A工平台-->功能-判断商品是否符合知识库里的法律法规; 知识库-网站; 知识库-->文档-Word_Exce1_Cs; 网站-->爬虫; 爬虫-->RPA; 爬虫-->Python; 文档-word_Excel_CsV-->Pandas; AI大模型-->本地AI; AI大模型-->云AI; 法律法规数据爬取网站 国家药品监督管理局 https://www.nmpa.gov.cn/ylqx/index.html (爬取目标1) 国家药品监督管理局医疗器械技术审评中⼼ https://www.cmde.org.cn/index.html (爬取目标2)...

