
医药器械法规数据爬取
名词解释
需求
- 法律法规知识库的建立
- AI环境与知识库
- 扣子AI智能体应用与系统集成
功能需求:
实现输⼊商品信息接⼝ , 提交商品后根据现有法律法规判断商品是否
%%{init: {"flowchart": {"useMaxWidth": true}}}%%
graph LR
系统A-->AI平台;
系统B-->AI平台;
系统C-->AI平台;
其他-->A工平台;
AI平台-->知识库;
AI平台-->AI大模型;
A工平台-->功能-判断商品是否符合知识库里的法律法规;
知识库-网站;
知识库-->文档-Word_Exce1_Cs;
网站-->爬虫;
爬虫-->RPA;
爬虫-->Python;
文档-word_Excel_CsV-->Pandas;
AI大模型-->本地AI;
AI大模型-->云AI;
法律法规数据爬取网站
- 国家药品监督管理局 https://www.nmpa.gov.cn/ylqx/index.html (爬取目标1)
- 国家药品监督管理局医疗器械技术审评中⼼ https://www.cmde.org.cn/index.html (爬取目标2)
- 国家药典委员会 (API) https://www.chp.org.cn/
- 聚合平台 - 药智医械数据 https://db.yaozh.com/qx (爬取目标3)
需要获取的数据
- 标题
- 索引号
- 分类
- 日期
- 文章内容
- 多个附件(难点,需要下载,保持文件格式,按照文章存放,判断如果已存在则跳过)
一定要做好异常处理
存入到MySQL,一个网站一个表, 名字_平台,字段自定义
数据插入文件inser_data.py
1 | import xbot |
爬取npm网站
表创建
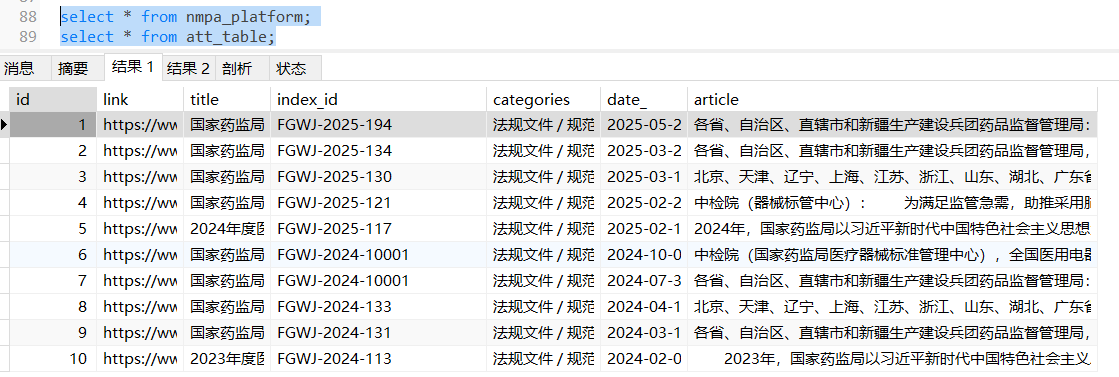
- nmpa_platform主表创建
1
2
3
4
5
6
7
8
9
10
11create table nmpa_platform(
id int primary key AUTO_INCREMENT,
link VARCHAR(100) not NULL comment '链接',
title varchar(64) not null comment '标题',
index_id varchar(16) not null comment '索引号',
categories varchar(16) not NULL comment '主题分类',
date_ varchar(16) not NULL COMMENT '发布日期',
article text not NULL COMMENT '文章内容'
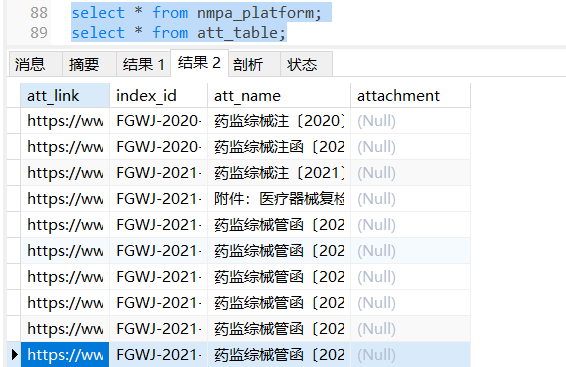
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci; - att_table附件表创建
1
2
3
4
5
6create table att_table(
att_link varchar(300) PRIMARY key comment '附件链接',
index_id varchar(16) not null comment '索引号',
att_name varchar(64) not null comment '附件名',
attachment text comment '附件内容'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
get_table1_data.py
1 | import xbot |
结果
爬取cmde网站
表创建
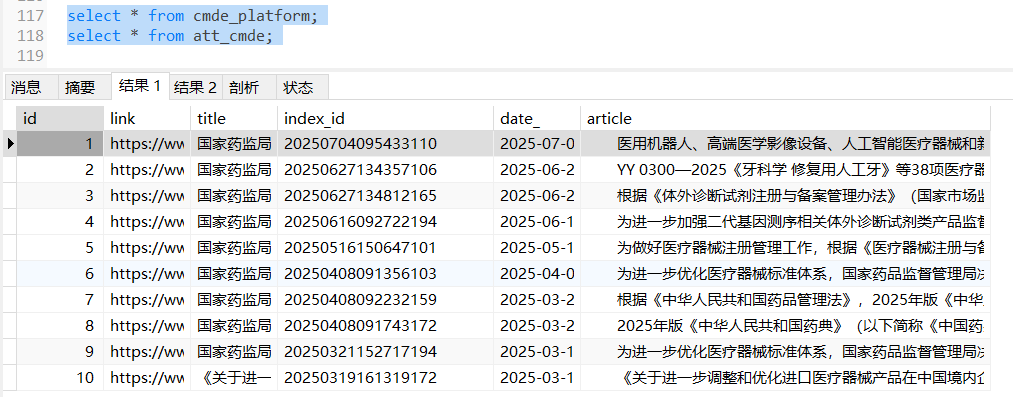
- cmde_platform主表创建
1
2
3
4
5
6
7
8
9create table cmde_platform(
id int primary key AUTO_INCREMENT,
link VARCHAR(200) not NULL comment '链接',
title varchar(128) not null comment '标题',
index_id varchar(32) not null comment '索引号',
-- categories varchar(16) not NULL comment '主题分类',
date_ varchar(16) not NULL COMMENT '发布日期',
article text not NULL COMMENT '文章内容'
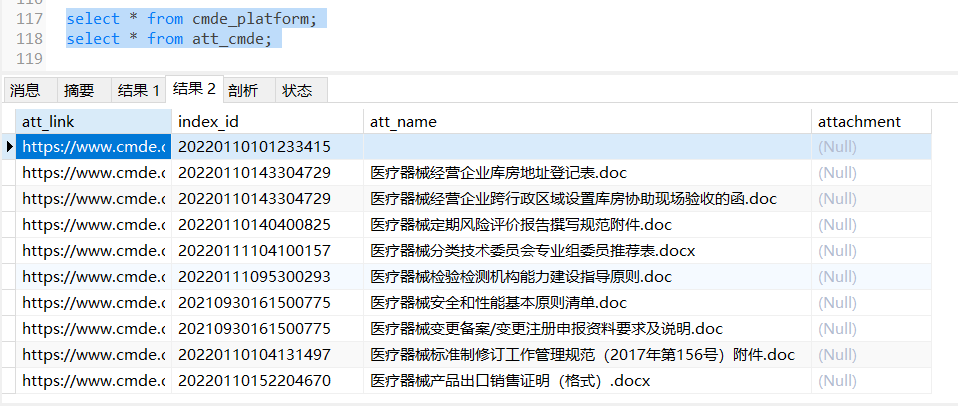
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci; - att_cmde附件表创建
1
2
3
4
5
6create table att_cmde(
att_link varchar(200) PRIMARY key comment '附件链接',
index_id varchar(32) not null comment '索引号',
att_name varchar(64) not null comment '附件名',
attachment text comment '附件内容'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
get_table2_data.py
1 | import xbot |
结果
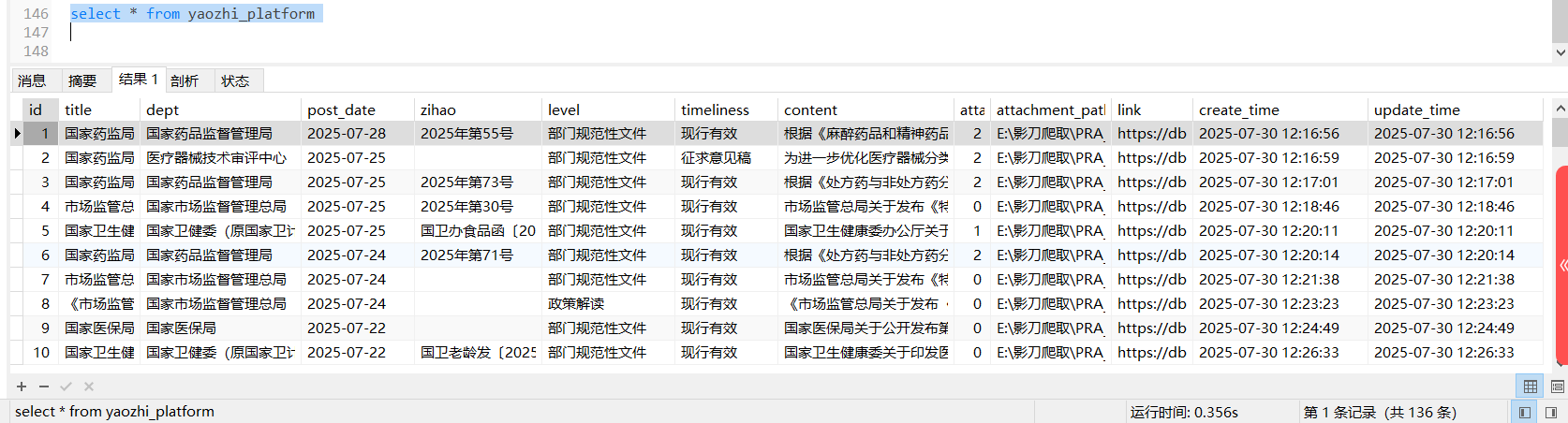
爬取yaozhi网站
表创建
主表yaozhi_platform
1 | CREATE TABLE `yaozhi_platform` ( |
yaozhi.py
1 | # 使用提醒: |
结果
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Yinjin Yao的博客!
相关推荐

2025-07-24
京东RPA爬虫
需求12345678910商品 ID item_id 商品链接 item_link 标题 item_title ⻔店名称 store 封⾯ cover_link 原价 original_cost 折扣价 discount_cost 品牌 brand 型号 type 评论数 comments mysql数据库建表1234567891011121314151617CREATE TABLE IF NOT EXISTS `jd_items` ( `id` INT NOT NULL AUTO_INCREMENT COMMENT '自增主键', `item_id` varchar(255) NOT NULL COMMENT '商品ID', `item_link` varchar(255) NOT NULL COMMENT '地址 http开头', `store` varchar(64) NOT NULL COMMENT '门店名称', `title` varchar(255) NOT NULL COM...

2025-05-28
Python
国内常用镜像源12345678910111213清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/阿里云:http://mirrors.aliyun.com/pypi/simple/中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/华中科技大学:http://pypi.hustunique.com/豆瓣源:http://pypi.douban.com/simple/腾讯源:http://mirrors.cloud.tencent.com/pypi/simple华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/ 数据类型 数字型: bool int float ⾮数字型: str list tuple set dict ⽇期型: time datetime 例子: 123456sno=1age=18sname="小明"high=1.786print(f"{sname&#...

2025-07-27
亚马逊商品需求
需求 打开亚马逊网址 根据制定的大类类目,去每个小类目下统计Best Sellers前100名产品的商品ID、标题、图片、价格、链接 把相应信息写进数据库 把本次写入的数据跟上次写入的数据做分析 把有新冲上来的链接、哪条链接调价的结果,发消息通知我 (短信/微信/钉钉/系统通知/QQ邮箱) 表设计1234567891011CREATE TABLE amazon_items ( id INT PRIMARY KEY AUTO_INCREMENT, -- 自增主键categories VARCHAR(64) COMMENT '分类', item_id VARCHAR(64) COMMENT '商品ID', title VARCHAR(255) COMMENT '标题', img_url VARCHAR(255) COMMENT '图片链接', price DECIMAL(8, 2) COMMENT '价格', link VARCHAR(255)...

