
datax
DataX简介
DataX概述
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
datax源码地址:https://github.com/alibaba/DataX
DataX支持的数据源
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图。
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| Kingbase | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADB | √ | 写 | ||
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | 写 | ||
| Hologres | √ | 写 | ||
| AnalyticDB For PostgreSQL | √ | 写 | ||
| 阿里云中间件 | datahub | √ | √ | 读 、写 |
| SLS | √ | √ | 读 、写 | |
| 图数据库 | 阿里云 GDB | √ | √ | 读 、写 |
| Neo4j | √ | 写 | ||
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 数仓数据存储 | StarRocks | √ | √ | 读 、写 |
| ApacheDoris | √ | 写 | ||
| ClickHouse | √ | √ | 读 、写 | |
| Databend | √ | 写 | ||
| Hive | √ | √ | 读 、写 | |
| kudu | √ | 写 | ||
| selectdb | √ | 写 | ||
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 | |
| TDengine | √ | √ | 读 、写 |
DataX架构原理
DataX设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。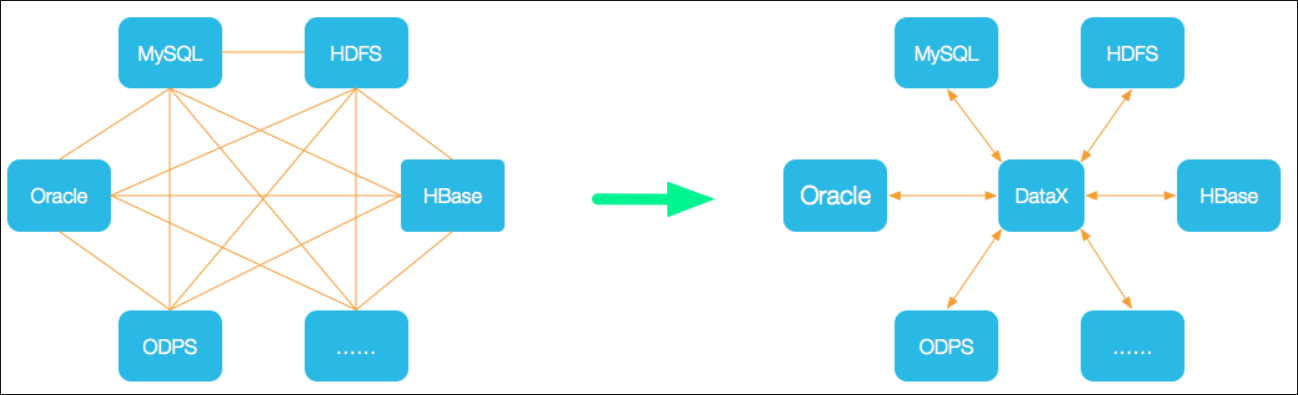
DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader�为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。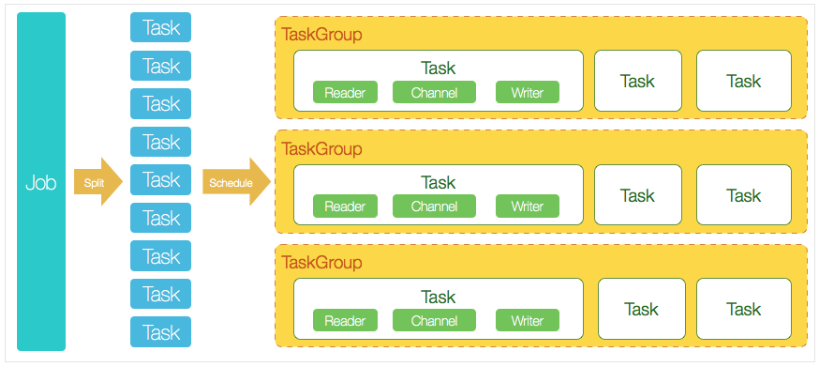
核心模块介绍:
- job:单个数据同步的作业,称之为一个Job,一个job启动一个进程。
- Task:根据不同数据源的切分策略,一个Job会切分为多个Task,Task是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
- TaskGroup:Scheduler调度模块会对Task进行分组,每个Task组称为一个Task Group,每个Task Group2负责以一定的并发度运行其所分得的Task,单个Task Group的并发度为5。
- Reader-→Channel-→Writer:每个Task启动后,都会固定启动Reader-→Channel-→Writer的线程来完成同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
DataX和Sqoop对比
| 功能 | Datax | Sqoop |
|---|---|---|
| 运行模式 | 单进程多线程 | MR |
| 分布式 | 不支持,可以通过调度系统规避 | 支持 |
| 流控 | 有流控功能 | 需要定制 |
| 统计信息 | 己有一些统计,上报需定制 | 没有,分布式的数据收集不方便 |
| 数据校验 | 在core部分有校验功能 | 没有,分布式的数据收集不方便 |
| 监控 | 需要定制 | 需要定制 |
DataX部署
下载DataX安装包并上传到hadoop102的/opt/software
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz解压datax.tar.gz到/opt/module
1
tar -zxvf datax.tar.gz -C /opt/module/
自检,执行如下命令
1
python /opt/module/datax/bin/datax.py /opt/module/datax/job/job.json
出现如下内容,则表明安装成功
DataX使用
官方文档https://github.com/alibaba/DataX/blob/master/userGuid.md
DataX使用概述
DataX任务提交命令
Datax的使用十分简单,用户只需要根据自己同步数据的数据源和目的地选择相应的Reader和Writer,并将Reader和Writer的信息配置在一个json文件中,然后执行如下命令提交数据同步任务即可。
1 | python bin/datax.py path/to/your/job.json |
DataX配置文件格式
可以使用如下命名查看DataX配置文件模板。
1 | python bin/datax.py -r mysqlreader -w hdfswriter |
配置文件模板如下,json最外层是一个job,job包含setting和content两部分,其中
- setting用于对整个job进行配置,
- content用户配置数据源和目的地。
1 | Please save the following configuration as a json file and use |
同步MySQL数据到HDFS案例
案例要求:同步gmall数据库中base_province表数据到HDFS的/base_province目录
需求分析:要实现该功能,需选用MySQLReader和HDFSWriter,MySQLReader具有两种模式分别是TableMode和QuerySQLMode,前者使用table,column,where等属性声明需要同步的数据;后者使用一条SQL查询语句声明需要同步的数据。
下面分别使用两种模式进行演示。
MySQLReader之TableMode
编写配置文件
(1) 创建配置文件base_province.json1
vim /opt/module/datax/job/base_province.json
(2) 配置文件内容如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"region_id",
"area_code",
"iso_code",
"iso_3166_2"
],
"where": "id>=3",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/gmall"
],
"table": [
"base_province"
]
}
],
"password": "000000",
"splitPk": "",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "name",
"type": "string"
},
{
"name": "region_id",
"type": "string"
},
{
"name": "area_code",
"type": "string"
},
{
"name": "iso_code",
"type": "string"
},
{
"name": "iso_3166_2",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "\t",
"fileName": "base_province",
"fileType": "text",
"path": "/base_province",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}配置文件说明
(1) Reader参数说明
(2) Writer参数说明
[!tip]
注意事项:
HFDS Writer并未提供nullFormat参数:也就是用户并不能自定义null值写到HFDS文件中的存储格式。默认情况下,HFDS Writer会将null值存储为空字符串(‘’),而Hive默认的null值存储格式为\N。所以后期将DataX同步的文件导入Hive表就会出现问题。
(3)Setting参数说明
提交任务
(1)在HDFS创建/base_province目录
使用DataX向HDFS同步数据时,需确保目标路径已存在1
hadoop fs -mkdir /base_province
(2)进入DataX根目录
(3)执行如下命令1
python bin/datax.py job/base_province.json
查看结果
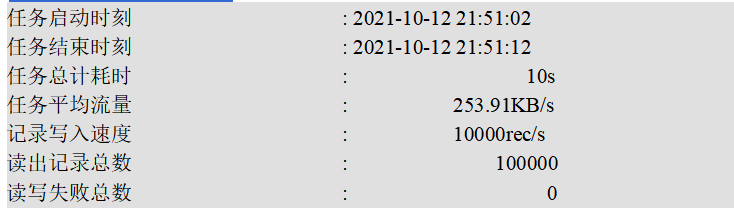
(1)DataX打印日志
(2)查看HDFS文件1
hadoop fs -cat /base_province/* | zcat
MySQLReader之QuerySQLMode
编写配置文件
(1)修改配置文件base_province.json
(2)配置文件内容如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/gmall"
],
"querySql": [
"select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=3"
]
}
],
"password": "000000",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "name",
"type": "string"
},
{
"name": "region_id",
"type": "string"
},
{
"name": "area_code",
"type": "string"
},
{
"name": "iso_code",
"type": "string"
},
{
"name": "iso_3166_2",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "\t",
"fileName": "base_province",
"fileType": "text",
"path": "/base_province",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}配置文件说明
(1)Reader参数说明
提交任务
(1)创建目标路径1
hadoop fs -rm -r -f /base_province/*
(2)进入DataX根目录
(3)执行如下命令1
2python bin/datax.py job/base_province.json
查看结果
(1)DataX打印日志
(2)查看HDFS文件1
hadoop fs -cat /base_province/* | zcat
DataX传参
通常情况下,离线数据同步任务需要每日定时重复执行,故HDFS上的目标路径通常会包含一层日期,以对每日同步的数据加以区分,也就是说每日同步数据的目标路径不是固定不变的,因此DataX配置文件中HDFS Writer的path参数的值应该是动态的。为实现这一效果,就需要使用DataX传参的功能。
DataX传参的用法如下,在JSON配置文件中使用${param}引用参数,在提交任务时使用-p”-Dparam=value”传入参数值,具体示例如下。
编写配置文件
(1)修改配置文件base_province.json
(2)配置文件内容如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://hadoop102:3306/gmall"
],
"querySql": [
"select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=3"
]
}
],
"password": "000000",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "name",
"type": "string"
},
{
"name": "region_id",
"type": "string"
},
{
"name": "area_code",
"type": "string"
},
{
"name": "iso_code",
"type": "string"
},
{
"name": "iso_3166_2",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop102:8020",
"fieldDelimiter": "\t",
"fileName": "base_province",
"fileType": "text",
"path": "/base_province/${dt}",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}提交任务
(1)创建目标路径1
hadoop fs -mkdir /base_province/2020-06-14
(2)进入DataX根目录
(3)执行如下命令1
python bin/datax.py -p"-Ddt=2020-06-14" job/base_province.json
查看结果
1
hadoop fs -ls /base_province
同步HDFS数据到MySQL案例
案例要求:同步HDFS上的/base_province目录下的数据到MySQL gmall 数据库下的test_province表。
需求分析:要实现该功能,需选用HDFSReader和MySQLWriter。
编写配置文件
(1)创建配置文件test_province.json
(2)配置文件内容如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"defaultFS": "hdfs://hadoop102:8020",
"path": "/base_province",
"column": [
"*"
],
"fileType": "text",
"compress": "gzip",
"encoding": "UTF-8",
"nullFormat": "\\N",
"fieldDelimiter": "\t",
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "root",
"password": "000000",
"connection": [
{
"table": [
"test_province"
],
"jdbcUrl": "jdbc:mysql://hadoop102:3306/gmall?useUnicode=true&characterEncoding=utf-8"
}
],
"column": [
"id",
"name",
"region_id",
"area_code",
"iso_code",
"iso_3166_2"
],
"writeMode": "replace"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}配置文件说明
(1)Reader参数说明
(2)Writer参数说明
- 提交任务
(1)在MySQL中创建gmall.test_province表(2)进入DataX根目录1
2
3
4
5
6
7
8
9
10DROP TABLE IF EXISTS `test_province`;
CREATE TABLE `test_province` (
`id` bigint(20) NOT NULL,
`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`region_id` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`area_code` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`iso_code` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`iso_3166_2` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
(3)执行如下命令1
python bin/datax.py job/test_province.json
- 查看结果
(1)DataX打印日志
(2)查看MySQL目标表数据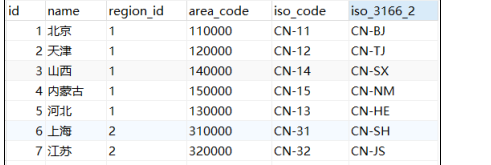
DataX优化
速度控制
DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在数据库可以承受的范围内达到最佳的同步速度。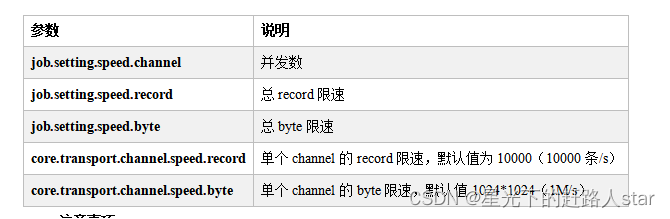
注意事项:
1.若配置了总record限速,则必须配置单个channel的record限速
2.若配置了总byte限速,则必须配置单个channe的byte限速
3.若配置了总record限速和总byte限速,channel并发数参数就会失效。因为配置了总record限速和总byte限速之后,实际channel并发数是通过计算得到的:
计算公式为:
min(总byte限速/单个channel的byte限速,总record限速/单个channel的record限速)
内存调整
当提升DataX Job内Channel并发数时,内存的占用会显著增加,因为DataX作为数据交换通道,在内存中会缓存较多的数据。例如Channel中会有一个Buffer,作为临时的数据交换的缓冲区,而在部分Reader和Writer的中,也会存在一些Buffer,为了防止OOM等错误,需调大JVM的堆内存。
建议将内存设置为4G或者8G,这个也可以根据实际情况来调整。
调整JVM xms xmx参数的两种方式:一种是直接更改datax.py脚本;另一种是在启动的时候,加上对应的参数,如下:
python datax/bin/datax.py –jvm=“-Xms8G -Xmx8G” /path/to/your/job.json




