Dify教程
本文纯属是搬运工,原文来自-光聚客网络科技
Dify系列课程
Lecture:邓澎波

一、Dify的介绍
Dify 是一款创新的智能生活助手应用,旨在为您提供便捷、高效的服务。通过人工智能技术,Dify 可以实现语音助手、智能家居控制、日程管理等功能,助您轻松应对生活琐事,享受智慧生活。简约的界面设计,让操作更加便捷;丰富的应用场景,满足您多样化的需求。Dify,让生活更简单!
二、Dify的安装方式
1. 在线体验
速度比较慢。不推荐
2. 本地部署
2.1 Docker安装
安装Docker环境
1 | bash <(curl -sSl https://cdn.jsdelivr.net/gh/SuperManito/LunuxMirrors@main/DockerInstallation.sh) |
安装Docker Compose
1 | curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose && chmod +x /usr/local/bin/docker-compose |
执行查看Docker-compose版本
1 | docker-compose --version |

说明安装成功了
docker-compse拉取镜像很慢
1 | sudo tee /etc/docker/daemon.json <<-'EOF' |
执行上面的代码
1 | sudo systemctl daemon-reload # 重新加载 systemd 的配置文件 |
然后去GitHub上拉取dify的代码。解压后进入到docker目录中
1 | docker-compose up -d |
执行即可
2.2 DockerDeskTop
在Windows环境下我们可以通过DockerDesktop 来安装。直接去官网下载对应的版本即可。同样的我们需要拉取dify的GitHub的代码。然后进入到Docker目录,同样的执行这个代码
1 | docker-compose up |
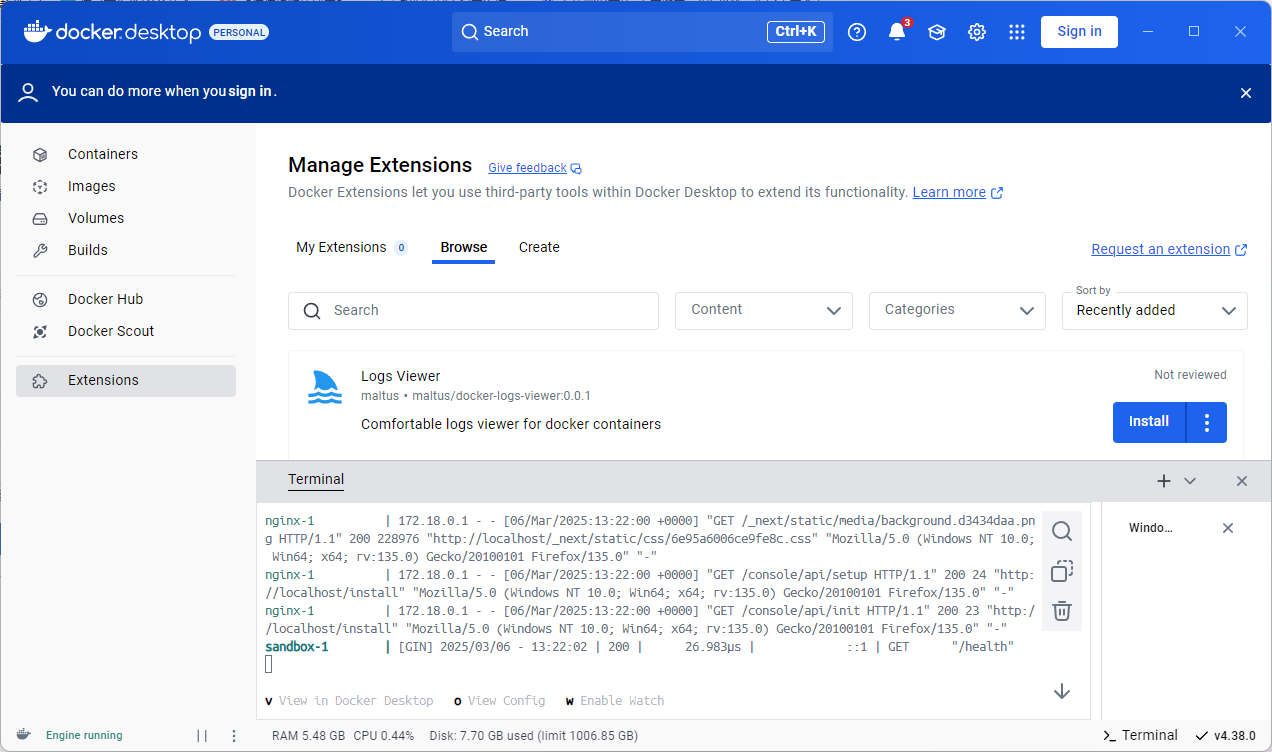
然后在地址栏中输入 http://localhost/install 就可以访问了
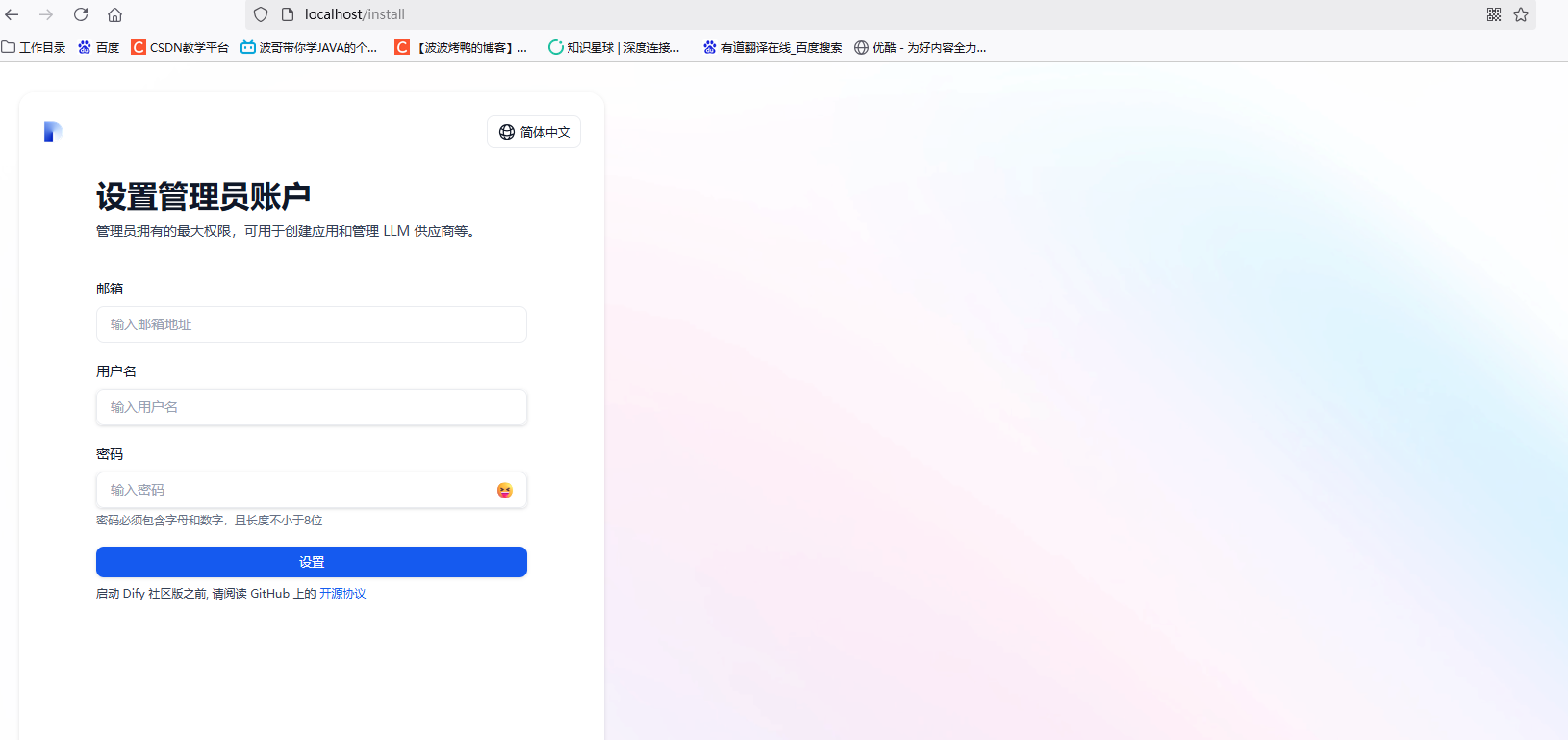
我们先设置管理员的相关信息。设置后再登录
3. Ollama
我们已经把Dify在本地部署了。然后我们可以通过Ollama在本地部署对应的大模型,比如 deepseek-r1:1.5b 这种小模型
Ollama 是一个让你能在本地运行大语言模型的工具,为用户在本地环境使用和交互大语言模型提供了便利,具有以下特点:
1)多模型支持:Ollama 支持多种大语言模型,比如 Llama 2、Mistral 等。这意味着用户可以根据自己的需求和场景,选择不同的模型来完成各种任务,如文本生成、问答系统、对话交互等。
2)易于安装和使用:它的安装过程相对简单,在 macOS、Linux 和 Windows 等主流操作系统上都能方便地部署。用户安装完成后,通过简洁的命令行界面就能与模型进行交互,降低了使用大语言模型的技术门槛。
3)本地运行:Ollama 允许模型在本地设备上运行,无需依赖网络连接来访问云端服务。这不仅提高了数据的安全性和隐私性,还能减少因网络问题导致的延迟,实现更快速的响应。
搜索Ollama进入官网https://ollama.com/download,选择安装MAC版本的安装包,点击安装即可
下载完成后直接双击安装即可
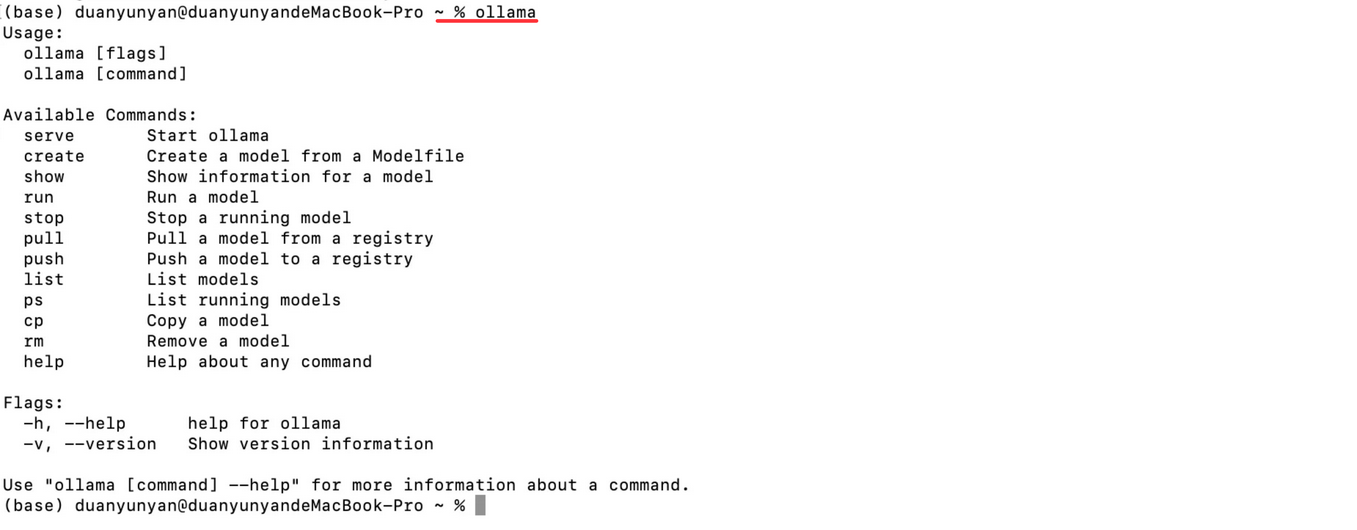
命令:ollama,出现下面内容,说明安装成功
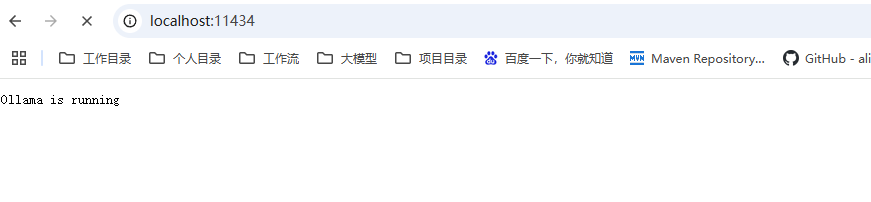
启动Ollama服务
输入命令【ollama serve】,浏览器打开,显示running,说明启动成功
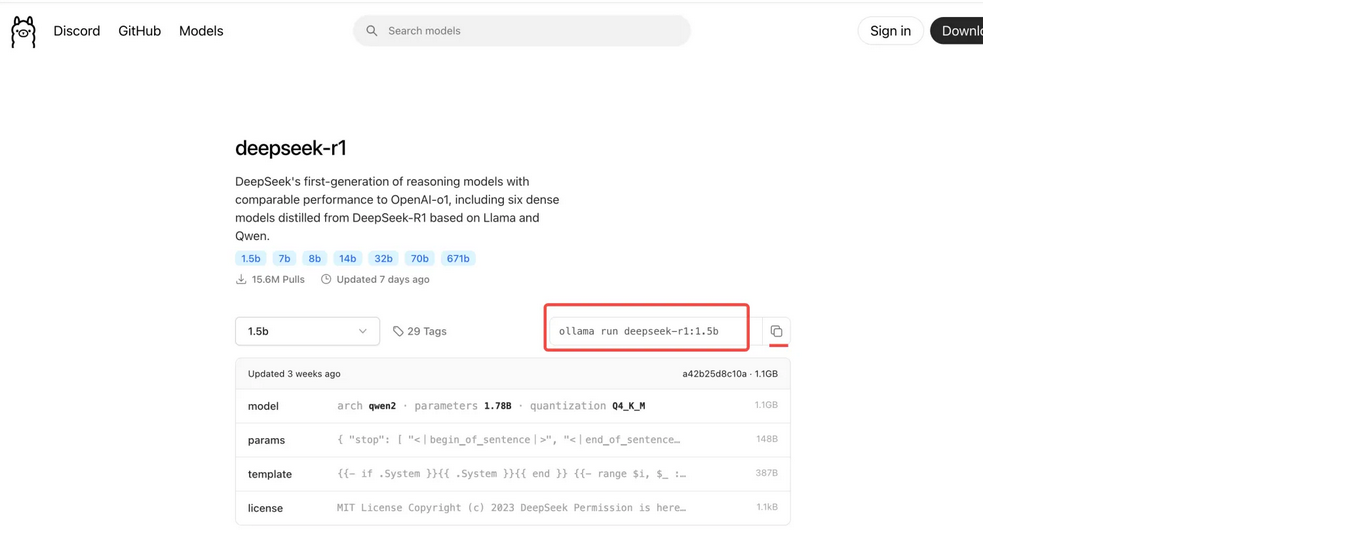
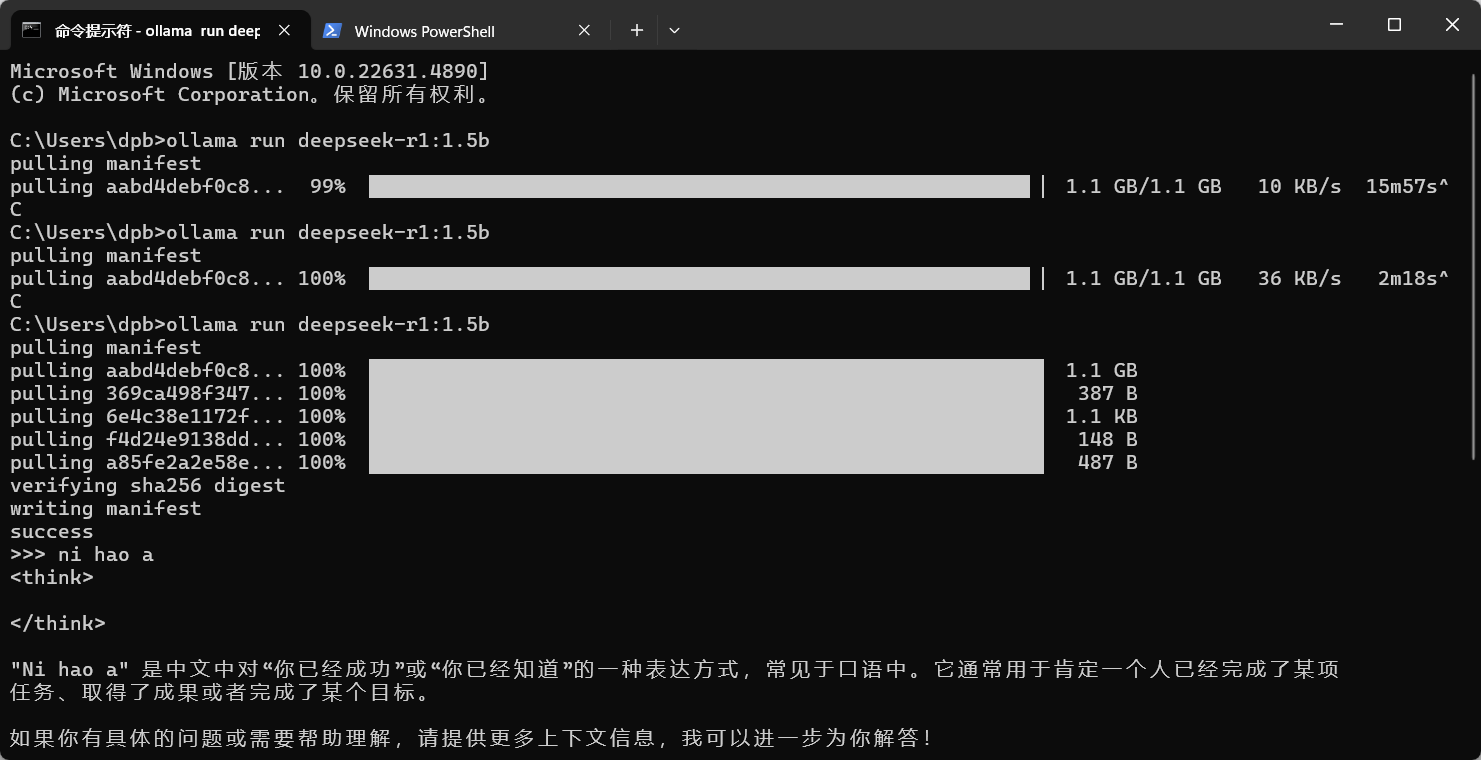
安装 deepseek-r1:1.5b模型
在https://ollama.com/library/deepseek-r1:1.5b 搜索deepseek-R1,跳转到下面的页面,复制这个命令,在终端执行,下载模型
cmd中执行这个命令
4.Dify关联Ollama
Dify 是通过Docker部署的,而Ollama 是运行在本地电脑的,得让Dify能访问Ollama 的服务。
在Dify项目-docker-找到.env文件,在末尾加上下面的配置:
1 | # 启用自定义模型 |
然后在模型中配置
在Dify的主界面 http://localhost/apps ,点击右上角用户名下的【设置】
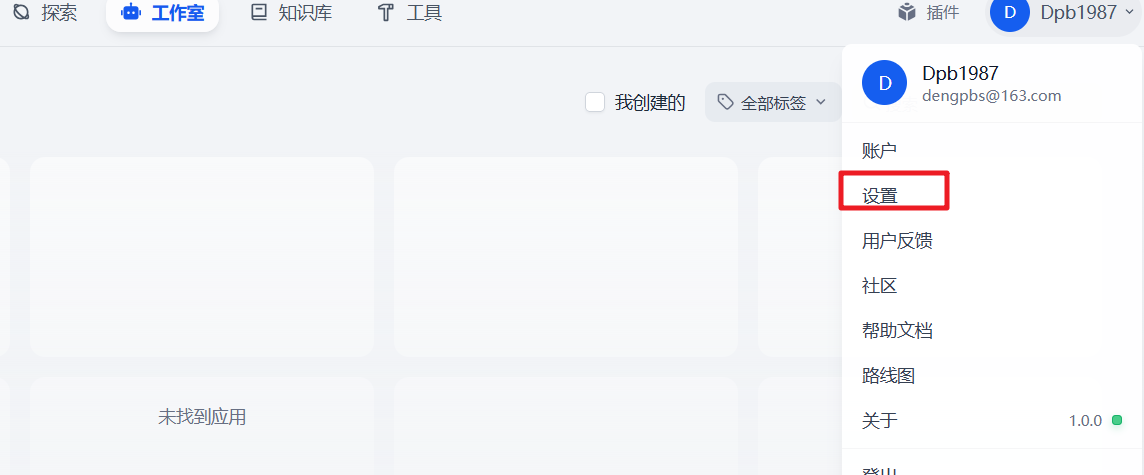
在设置页面–Ollama–添加模型,如下:
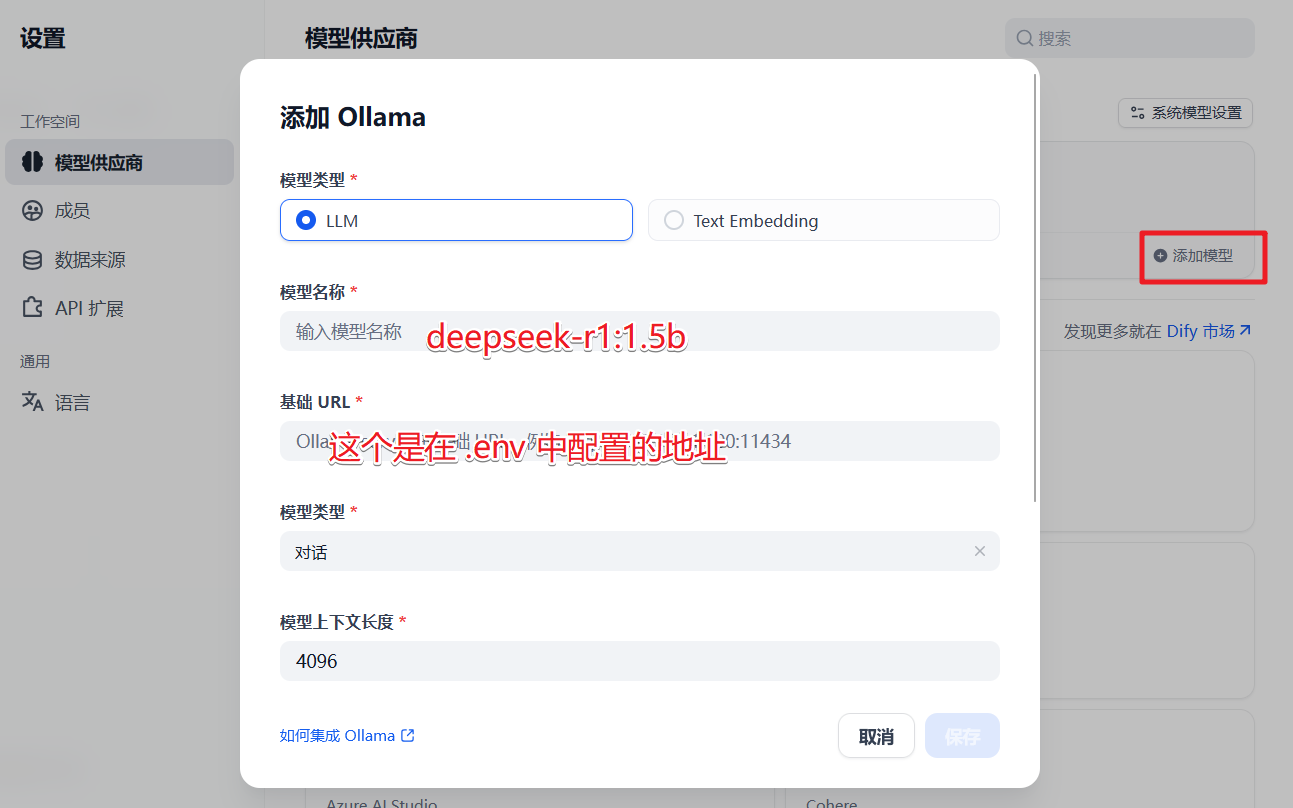
添加成功后的
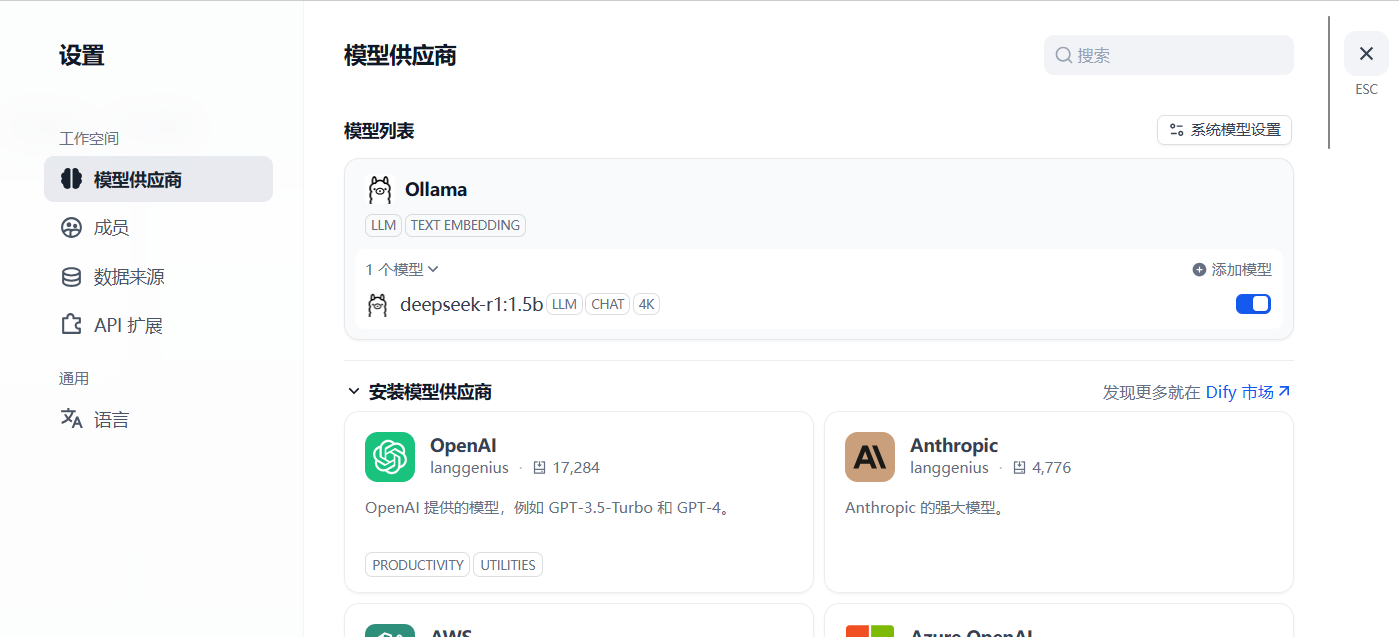
模型添加完成以后,刷新页面,进行系统模型设置。步骤:输入“http://localhost/install”进入Dify主页,用户名–设置–模型供应商,点击右侧【系统模型设置】,如下:
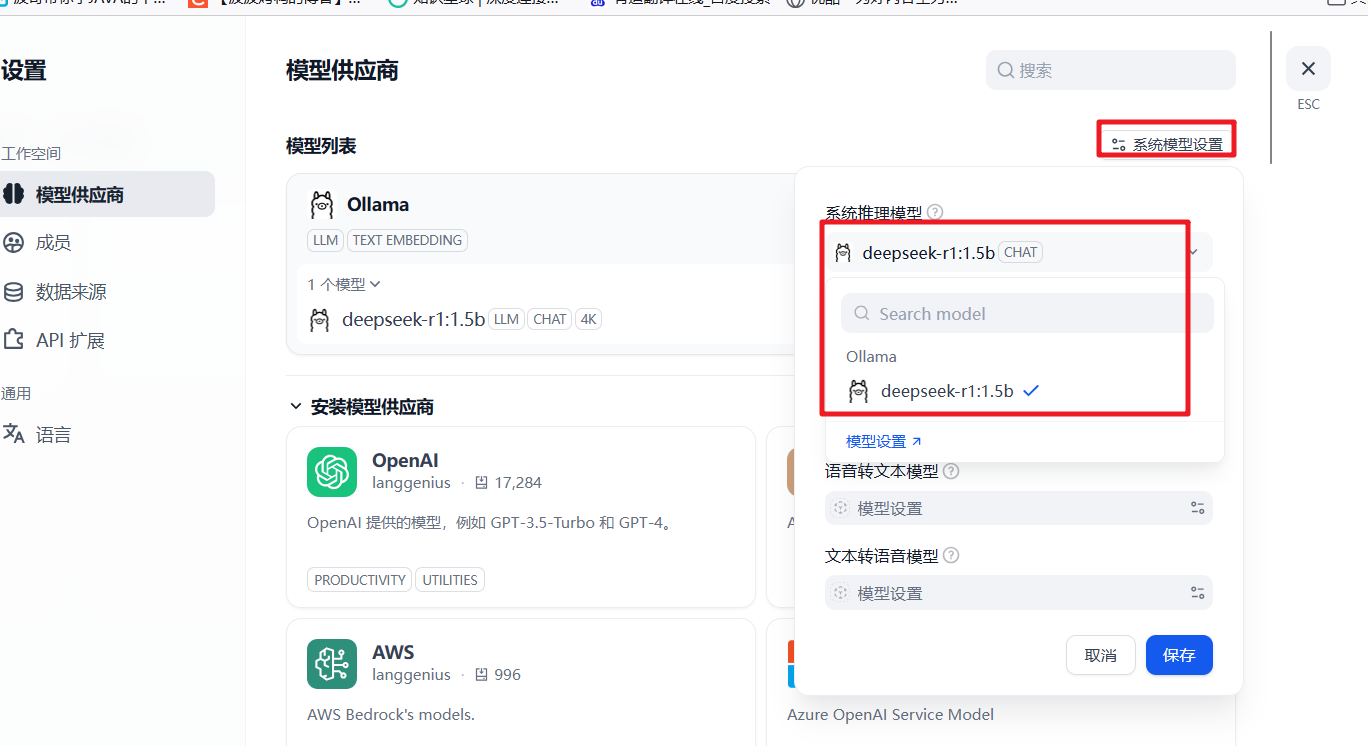
这样就关联成功了!!!
三、Dify应用讲解
1. 创建空白应用
我们通过Dify来创建我们的第一个简单案例,智能聊天机器人
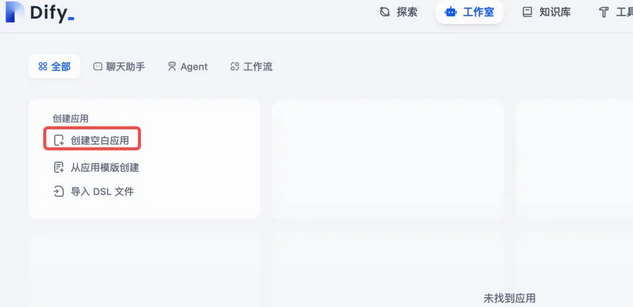
进入Dify 主界面,点击【创建空白应用】,如下图:
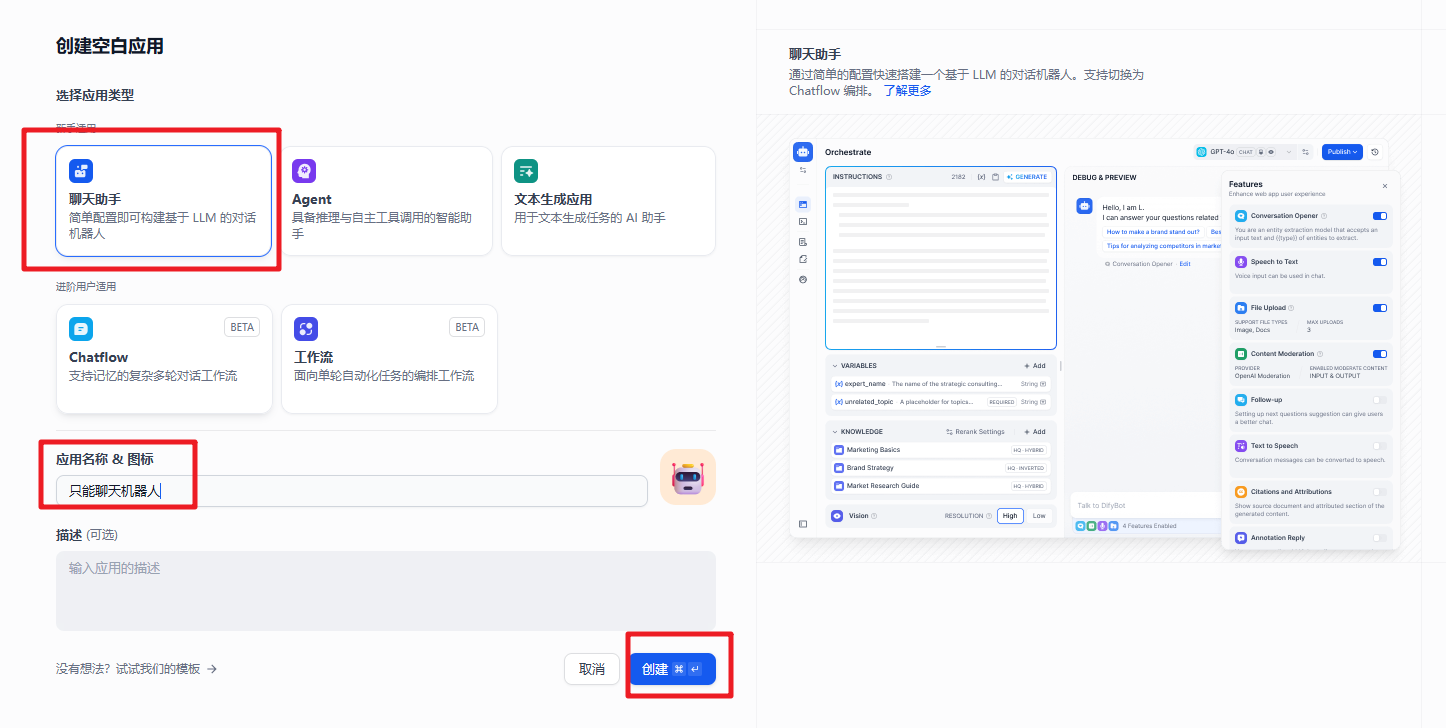
选择【聊天助手】,输入自定义应用名称和描述,点击【创建】
右上角选择合适的模型,进行相关的参数配置
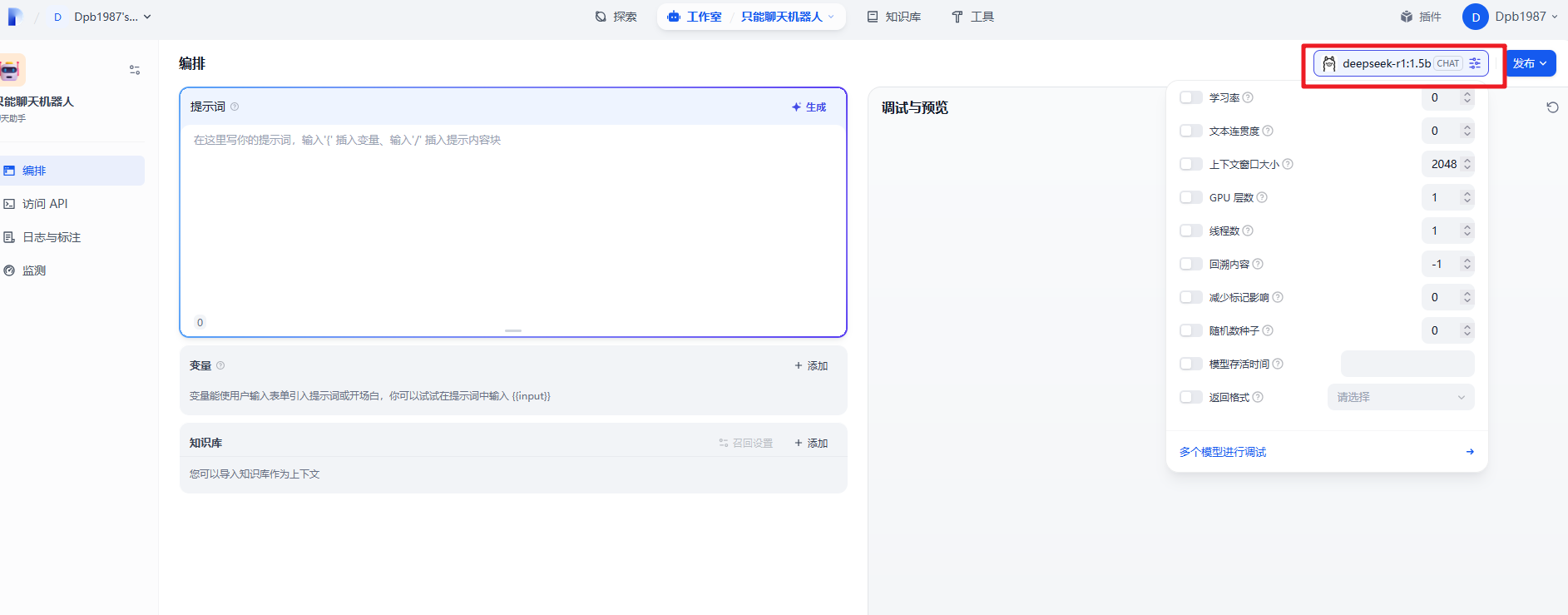
输入有相关的回复了。此时说明Dify 与本地部署的DeepSeek大模型已经连通了。
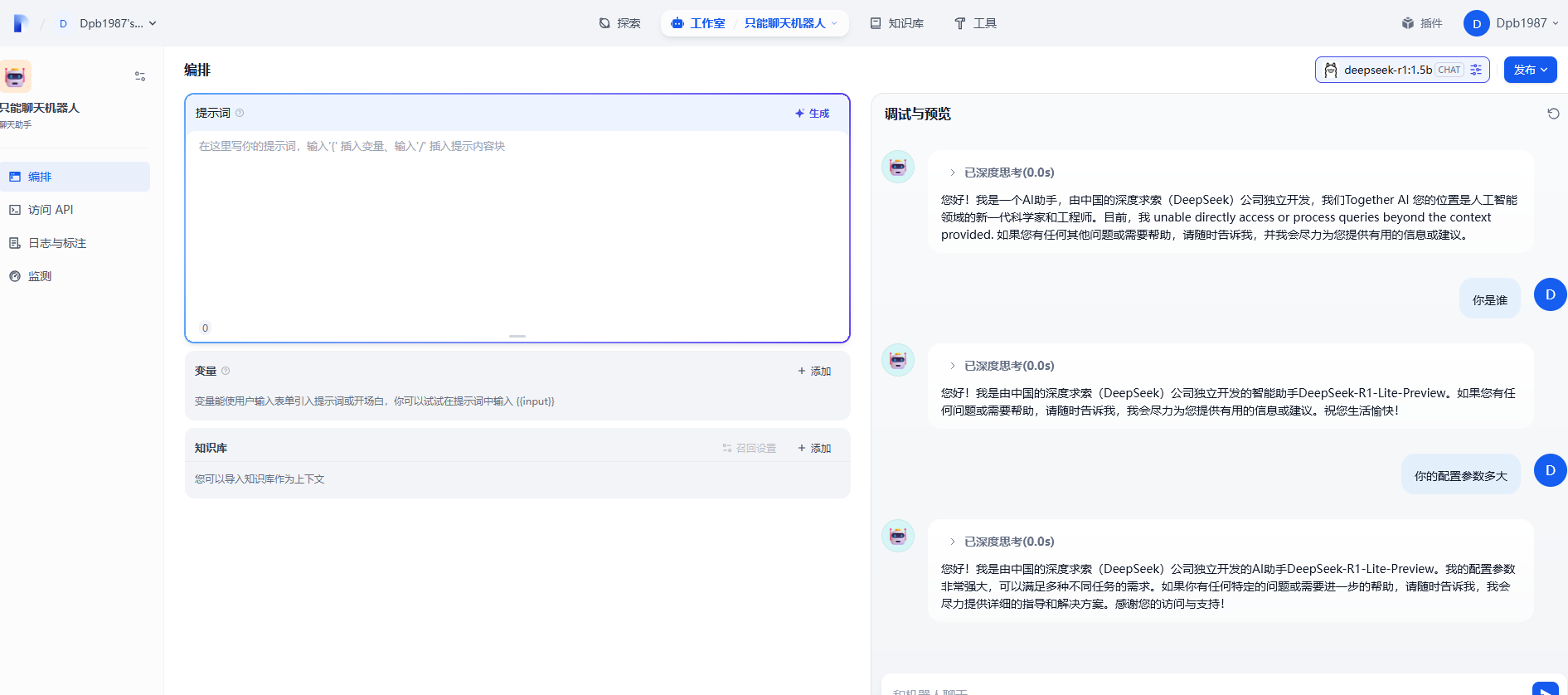
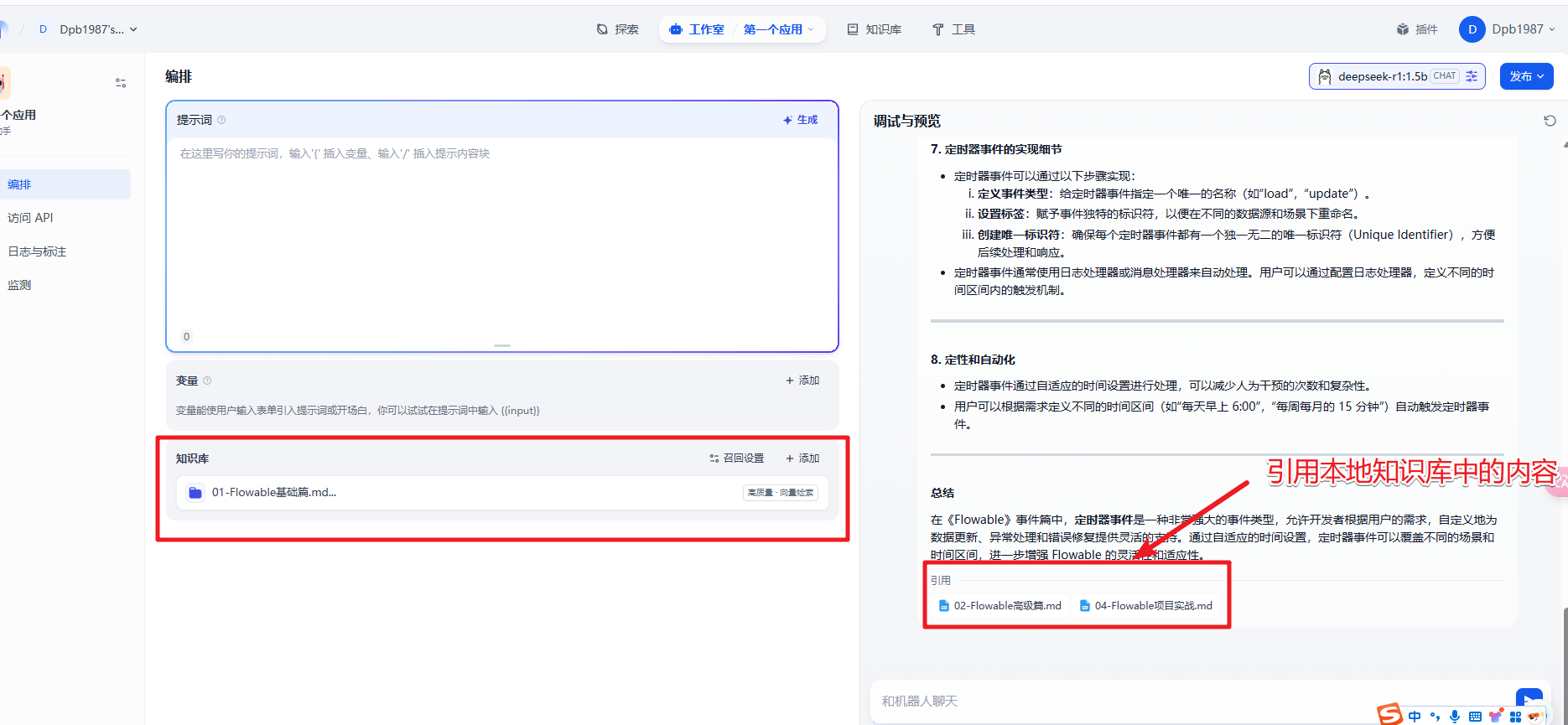
上面的机器人有个不足之处就是无法回答模型训练后的内容和专业垂直领域的内容,这时我们可以借助本地知识库来解决专业领域的问题。
2. 创建本地知识库
2.1 向量模型
Embedding模型是一种将数据转换为向量表示的技术,核心思想是通过学习数据的内在结构和语义信息,将其映射到一个低维向量空间中,使得相似的数据点在向量空间中的位置相近,从而通过计算向量之间的相似度来衡量数据之间的相似性。
Embedding模型可以将单词、句子或图像等数据转换为低维向量,使得计算机能够更好地理解和处理这些数据。在NLP领域,Embedding模型可以将单词、句子或文档转换为向量,用于文本分类、情感分析。机器翻译等任务。在计算机视觉中,Embedding模型可以用于图像识别和检索等任务。
2.2 添加Embedding模型
点击右上角用户名–设置–模型供应商–右上角【添加模型】,填写相关配置信息如下:
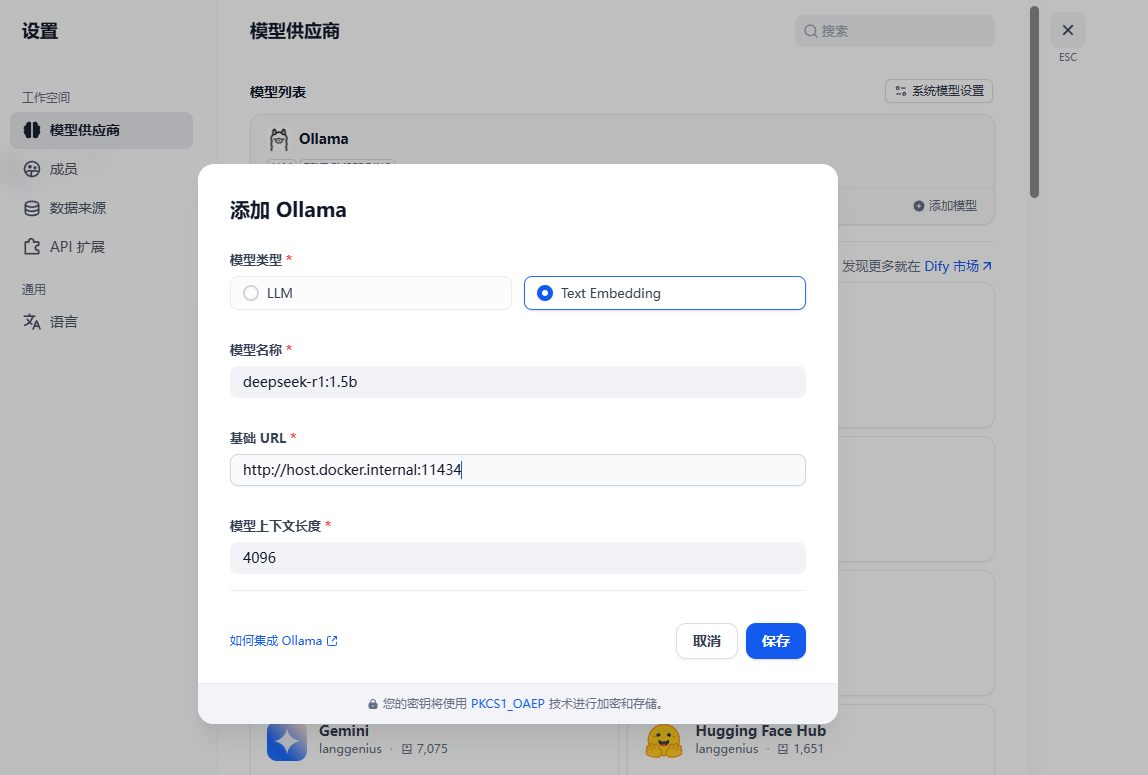
添加成功后的效果
2.3 创建知识库
在Dify主界面,点击上方的【知识库】,点击【创建知识库】
导入已有文本,上传资料,点击【下一步】
Embedding模型默认是前面配置的模型,参数信息配置完,点击保存即可
此时系统会自动对上传的文档进行解析和向量化处理,需要耐心等待几分钟。
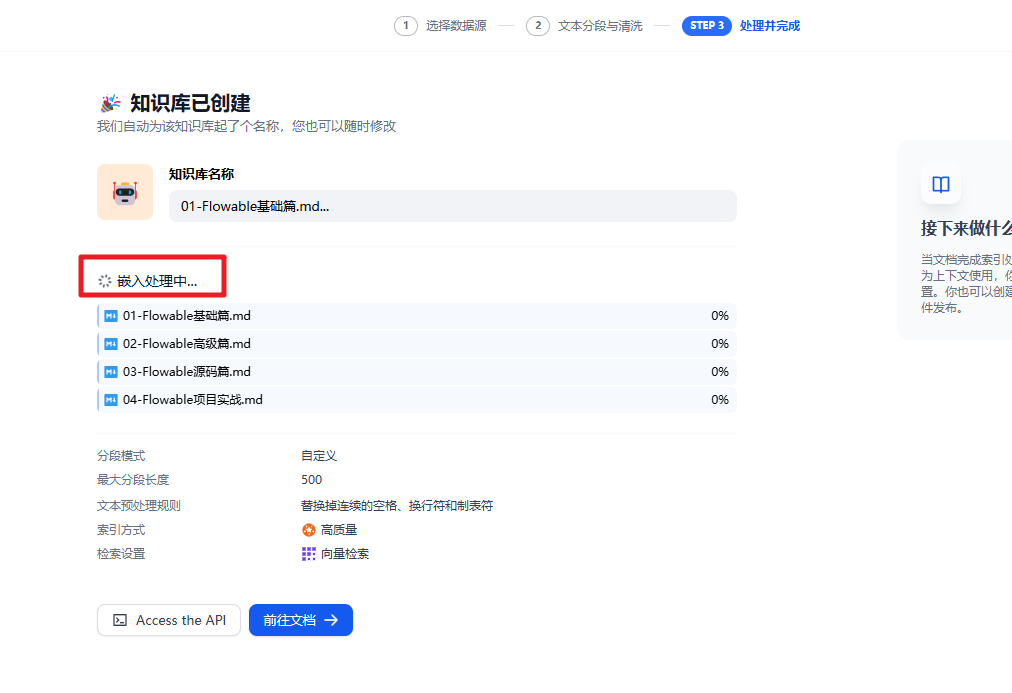
创建成功以后,如下图,可以点击【前往文档】,查看分段信息,如下图:
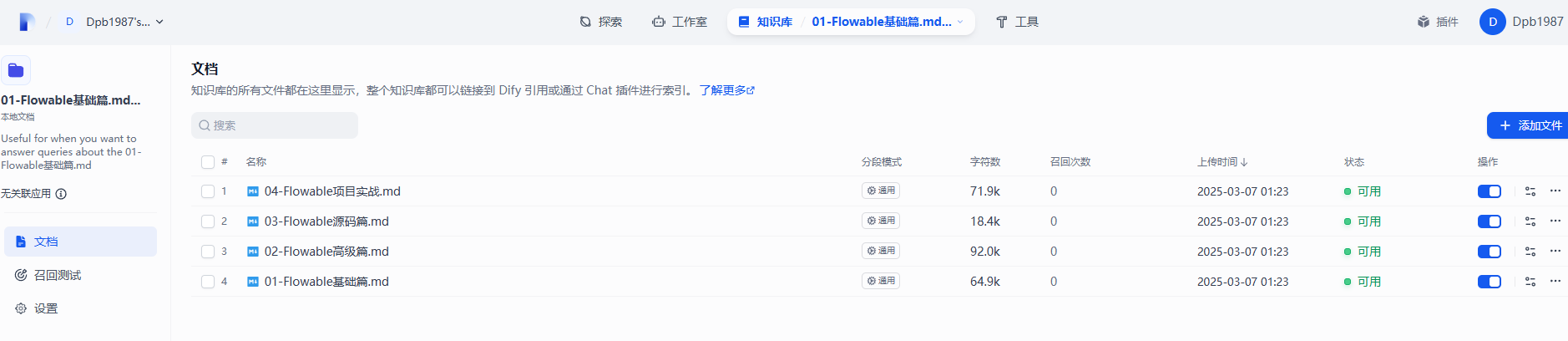
点击具体的文档可以看到具体的分割信息
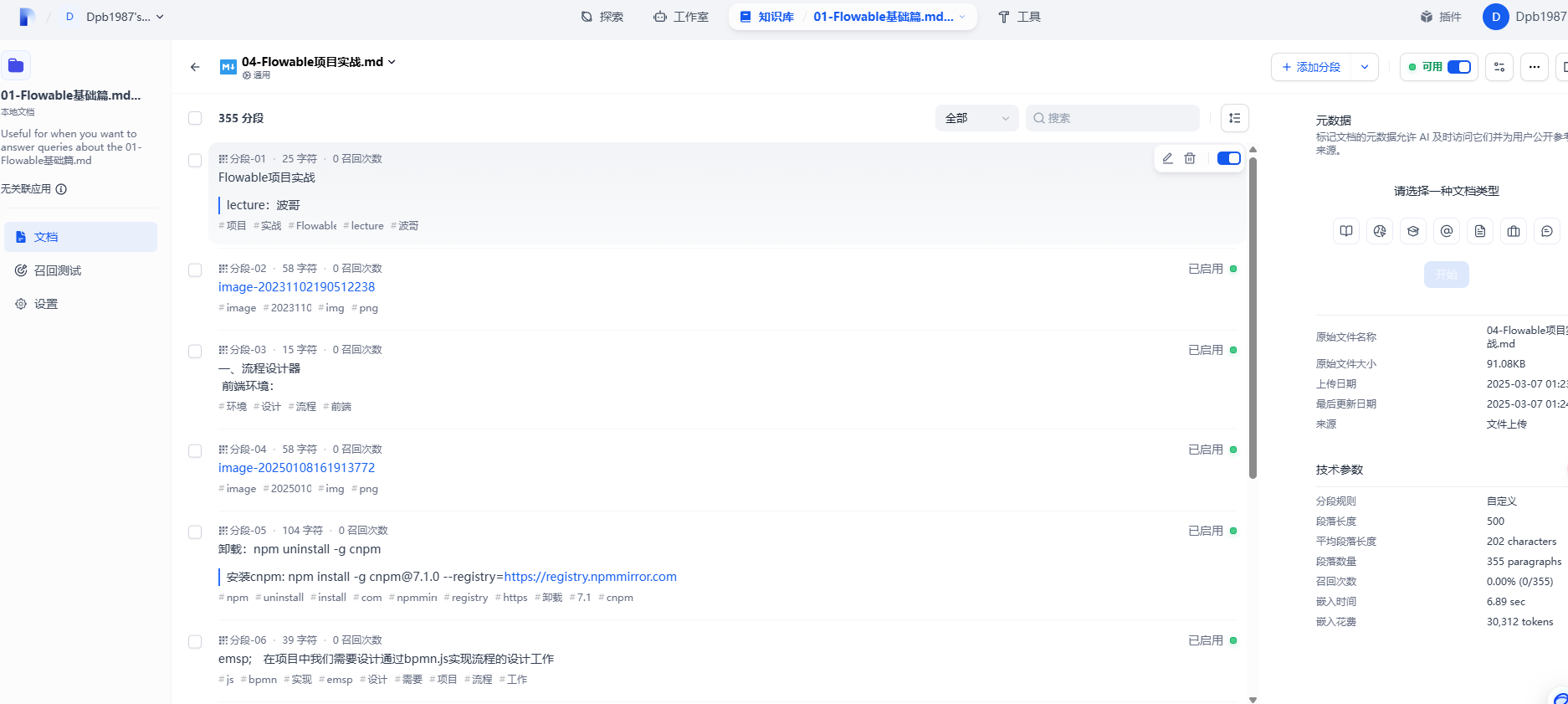
3. 知识库应用
3.1 添加知识库
在Dify主界面,回到刚才的应用聊天页面,工作室–智能聊天机器人–添加知识库,如下图: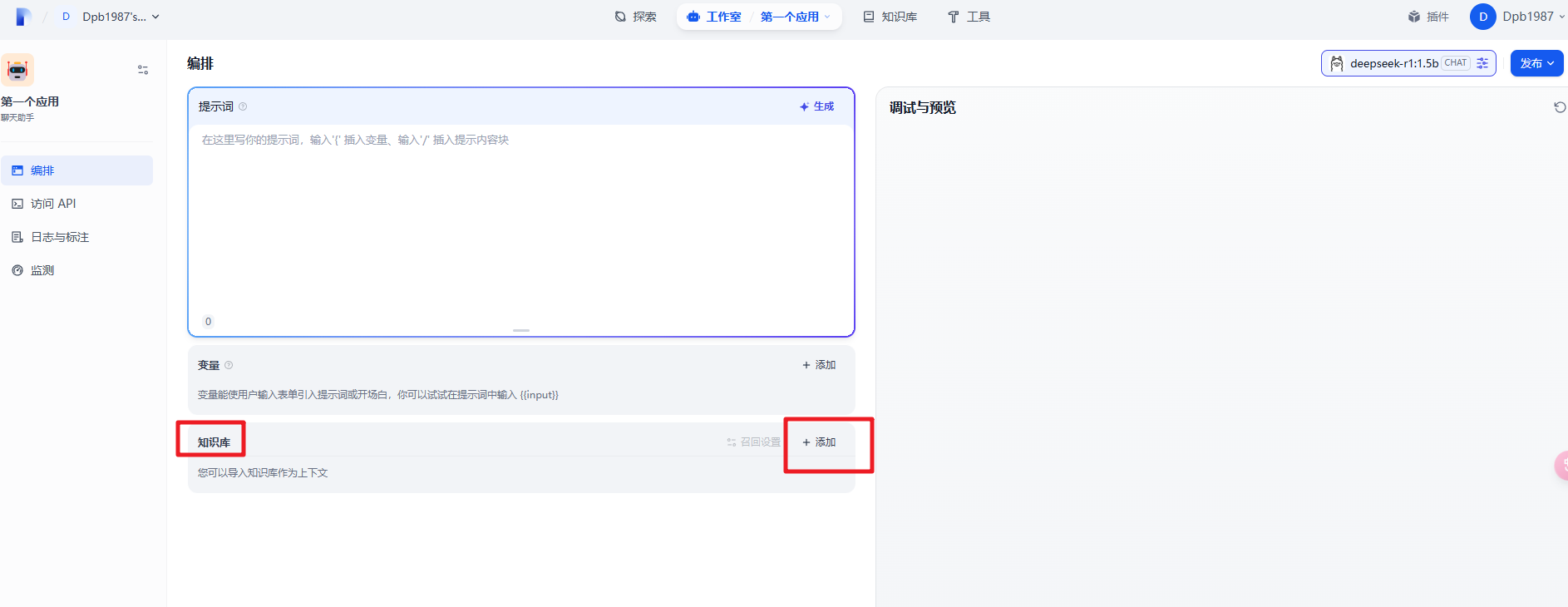
选择前面上面的知识库作为对话的上下文,保存当前应用设置,就可以进行测试了
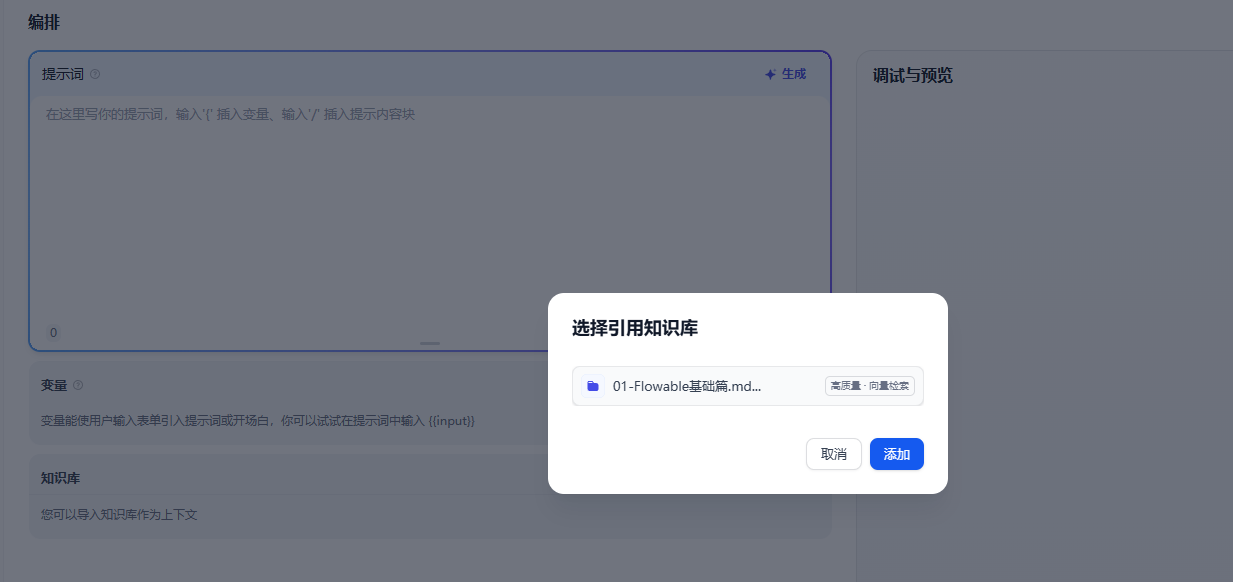
3.2 测试
此时输入问题,就可以看到相关的回复了。
4. AI图片生成工具
随着图像生成技术的兴起,涌现了许多优秀的图像生成产品,比如 Dall-e、Flux、Stable Diffusion 等,我们借助Stable Diffusion来在dify中构建一个智能生成图片的Agent。
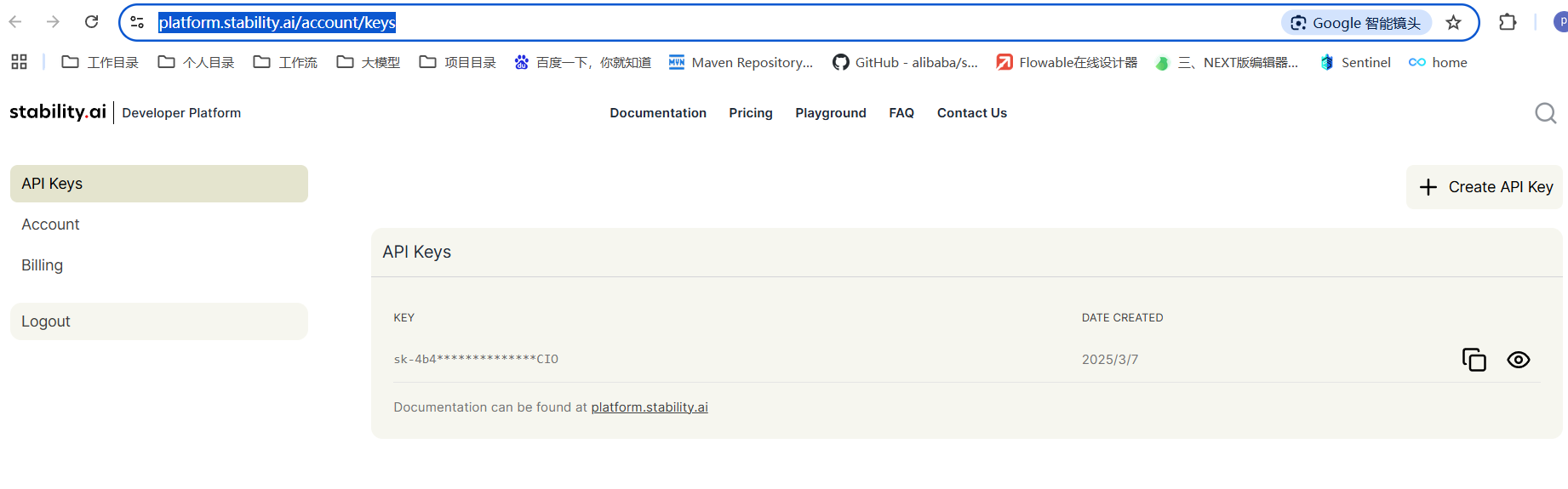
4.1 首先获取Stable Diffusion
https://platform.stability.ai/account/keys 去官网获取授权key。如果没注册需要先注册下
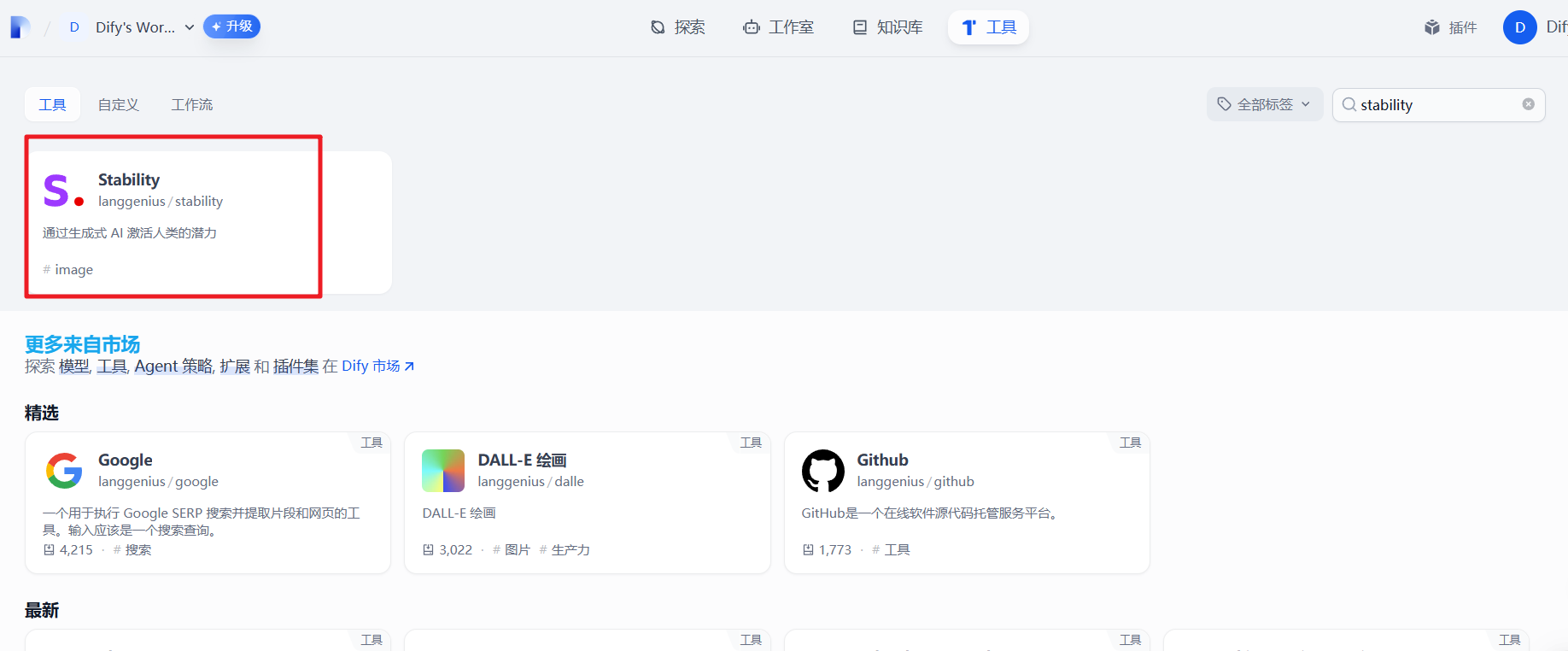
4.2 下载 Stable 工具
然后我们需要进入dify的工具市场下载安装 Stable 插件。
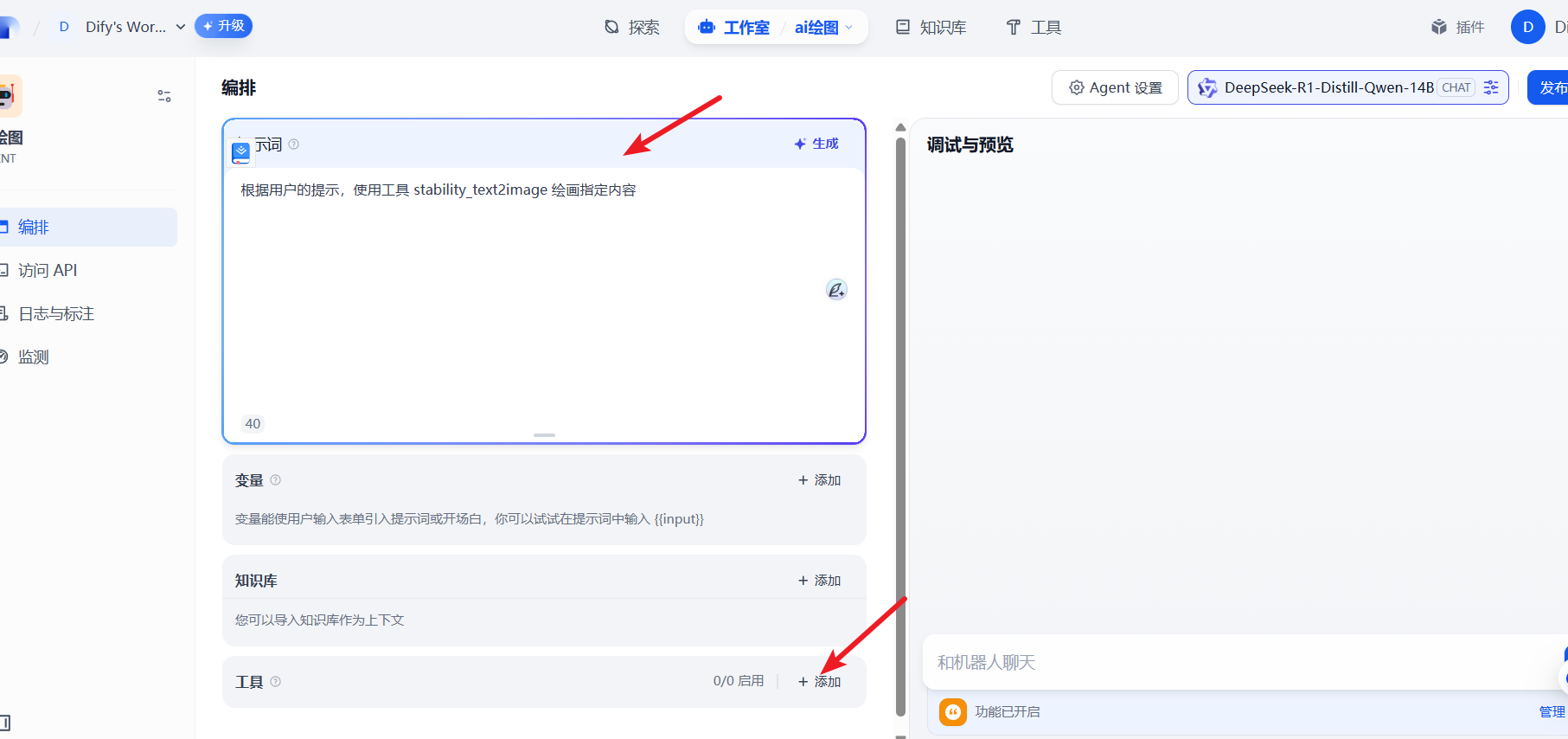
4.3 创建Agent
然后我们就可以创建一个空白的Agent。输入对应的提示词
1 | 根据用户的提示,使用工具 stability_text2image 绘画指定内容 |
然后选择对应的工具并添加授权码
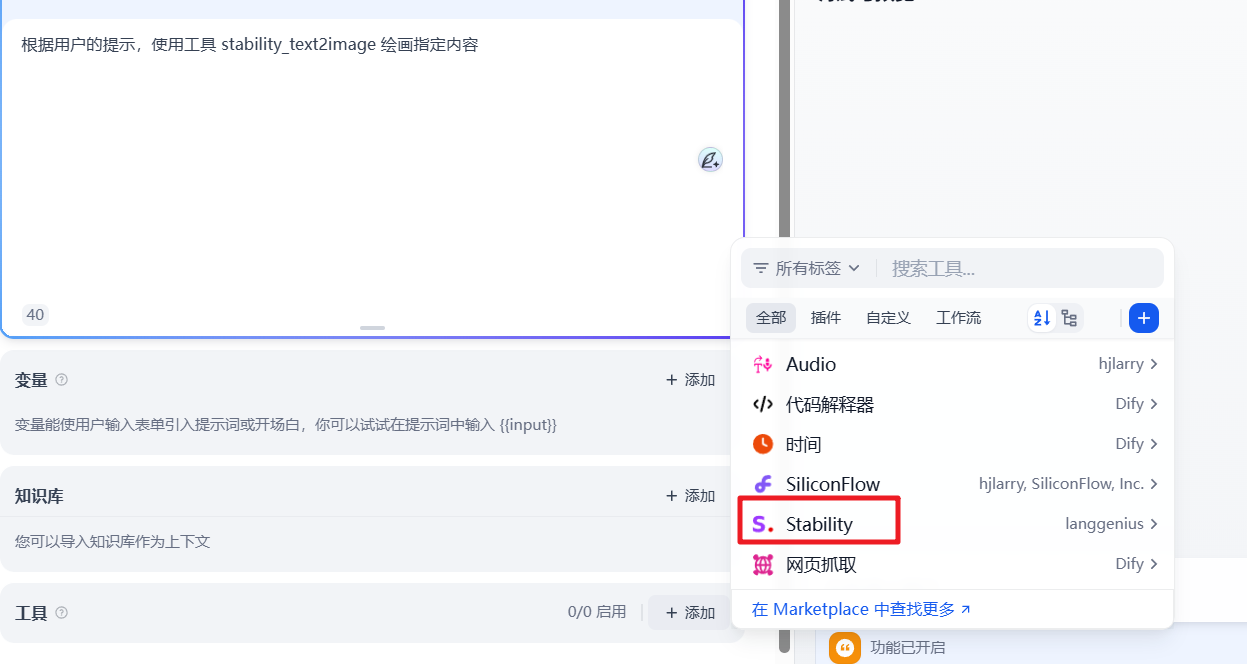
然后我们就可以测试效果了
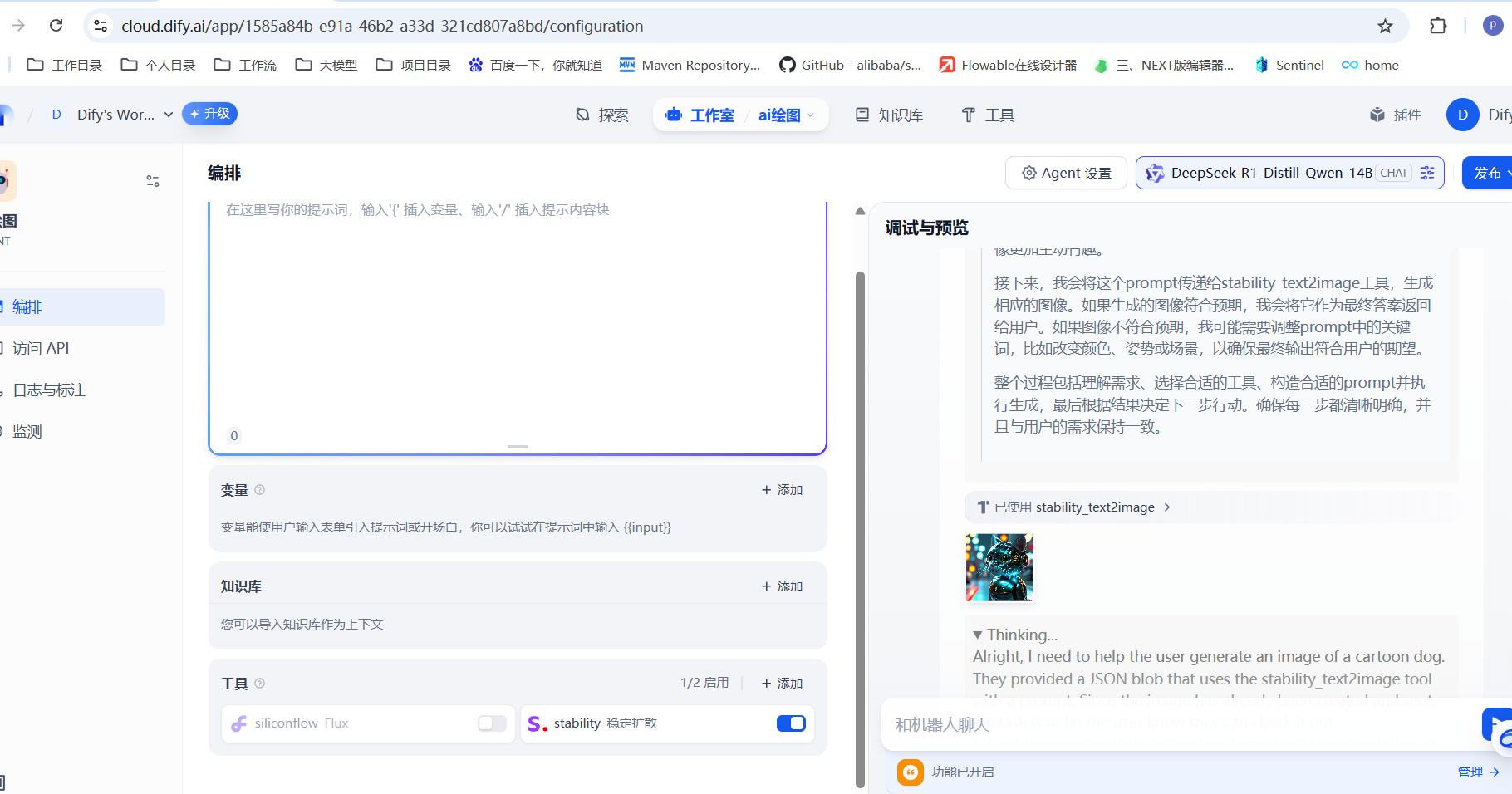
注意这个是一个付费的工具。提供的有一个免费的,后面需要付费购买了:https://platform.stability.ai/account/credits
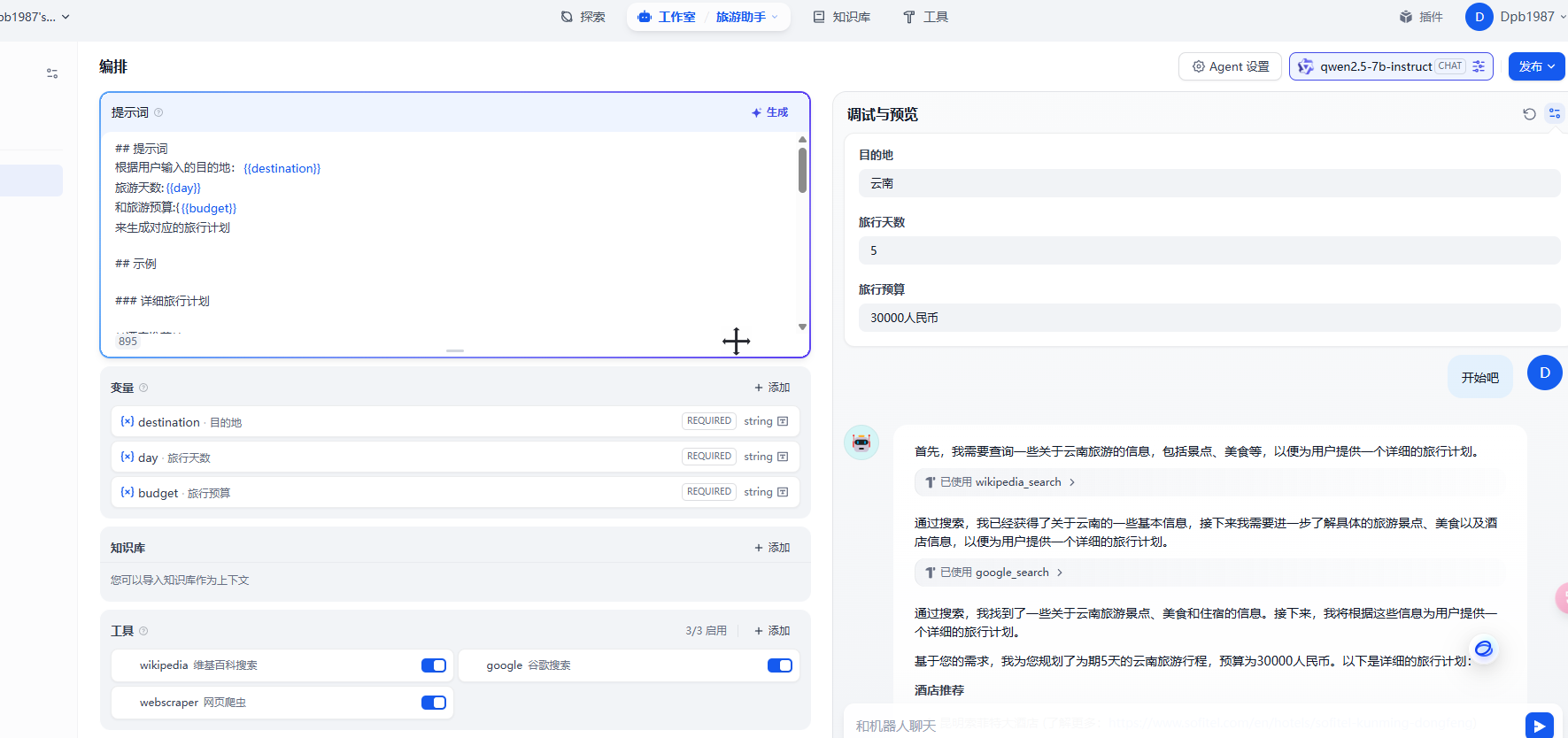
5. 旅游助手
进入SerpAPI - API Key,如果你尚未注册,会被跳转至进入注册页。
SerpAPI提供一个月100次的免费调用次数,这足够我们完成本次实验了。如果你需要更多的额度,可以增加余额,或者使用其他的开源方案。
6. SQL执行器
我们可以通过工作流来创建一个SQL语句的执行器,也就是我们可以输入相关的SQL语句然后通过工作流来连接数据库执行对应的SQL代码,具体的设计如下:
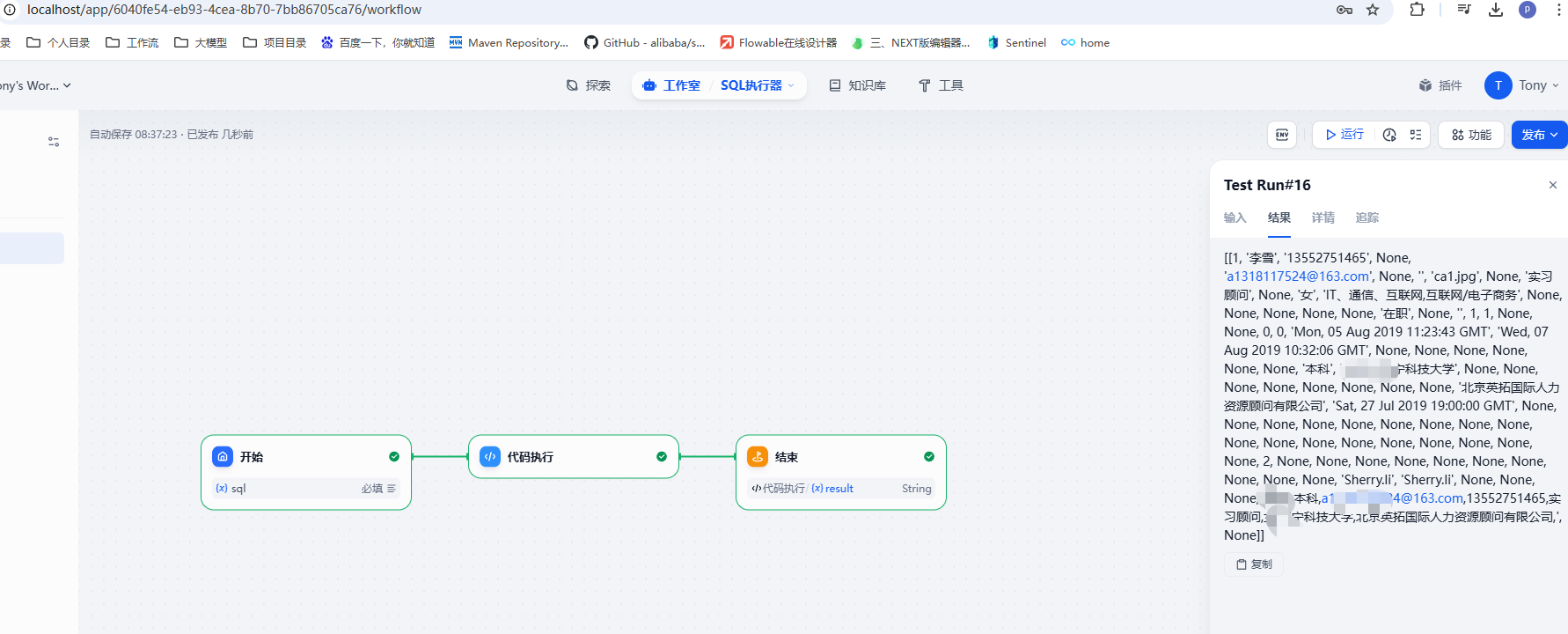
这里的核心是代码执行模块。这块我们是调用了我们自己创建的接口来执行数据库的操作,所以我们需要先创建这么一个接口,接口我们通过Flask这个轻量的web框架来实现。需要先安装Flask的依赖库
1 | pip install flask |
然后创建接口代码
1 | from flask import Flask, request, jsonify |
这个接口需要接收一个sql语句和一个包含数据库连接信息的json对象,我们可以编写对应的测试代码来看看
1 | import json |
执行后可以看到对应的结果
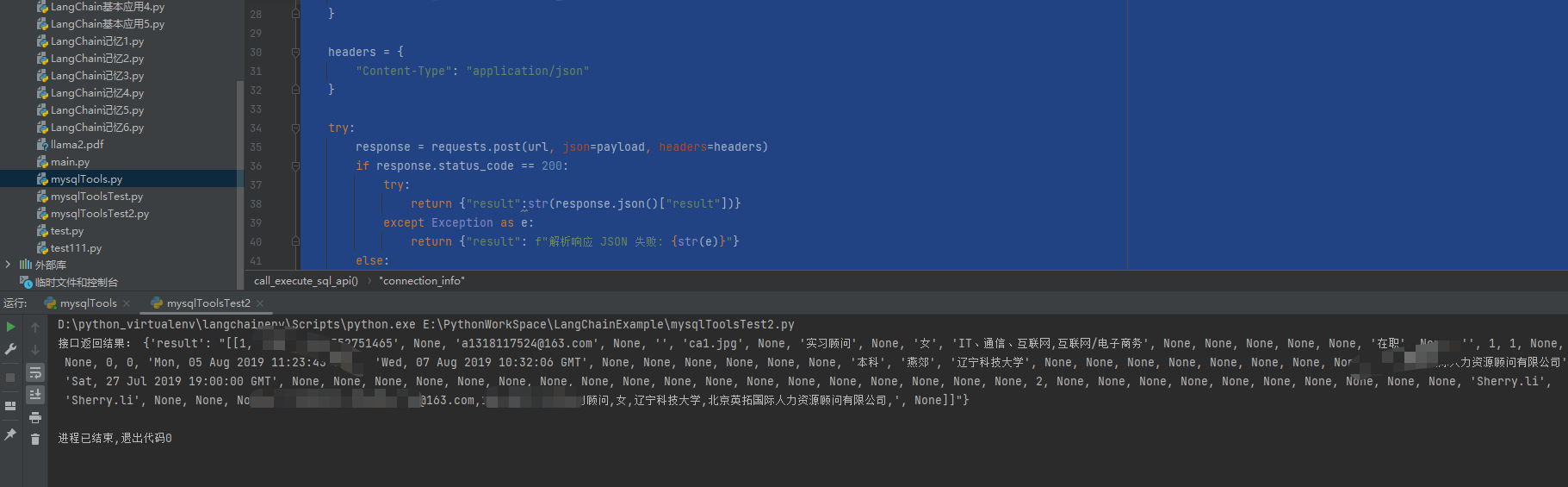
然后可以在工作流中来设置我们的代码
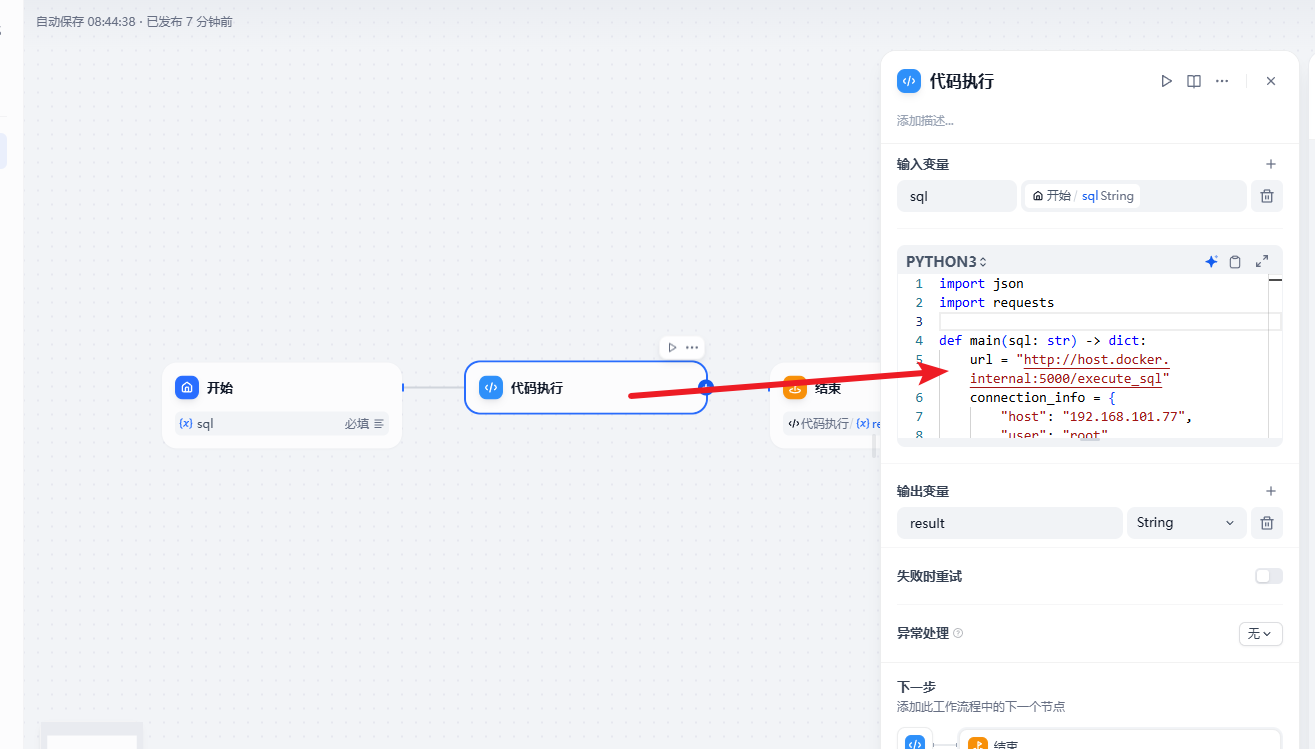
代码的内容
1 | import json |
注意上面的url中我们需要写
1 | http://host.docker.internal:5000/execute_sql |
不然执行的时候会出现503的错误。
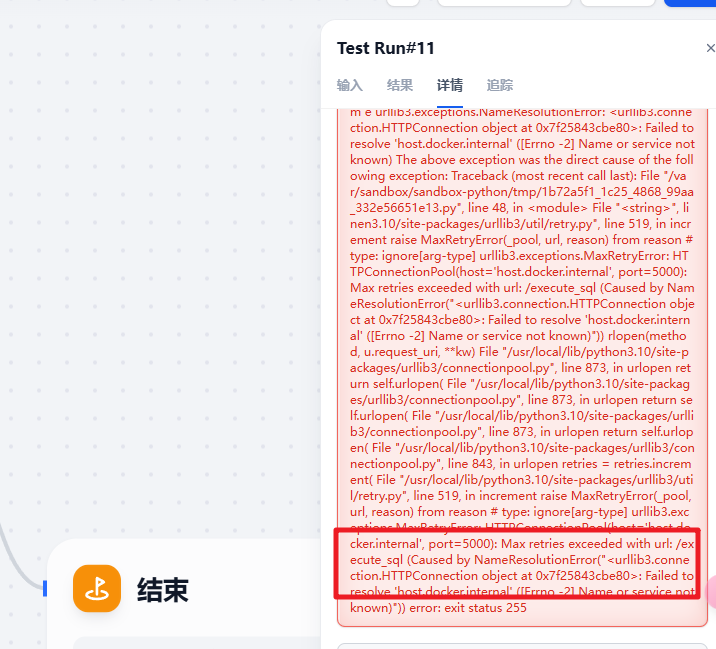
如果调用接口的组件是 urllib3 的话有可能出现上面的问题,这个原因可能是版本兼容的问题,这里推进用的是requests组件
7. 科研论文翻译
我可以在工作流案例中结合聊天大模型来实现翻译工具的功能,具体的设计如下
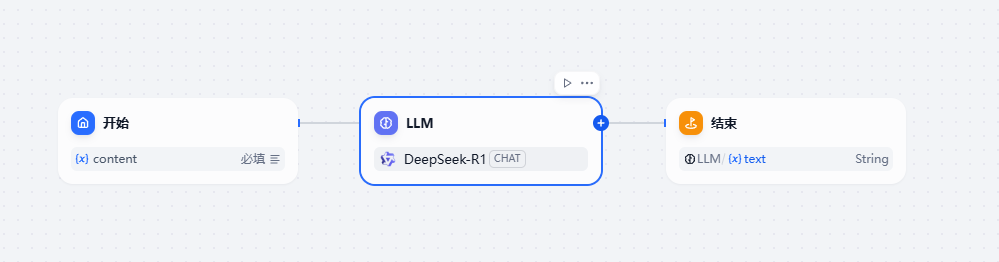
在开始节点中接收一个输入信息content
然后在LLM模型中我们需要配置一个CHAT模型,这里选择了DeepSeek-R1 64K的聊天模型,注意需要在这里设置下对应的提示词
1 | 现在我要写一个将中文翻译成英文科研论文的GPT,请参照以下Prompt制作,注意都用英文生成: |
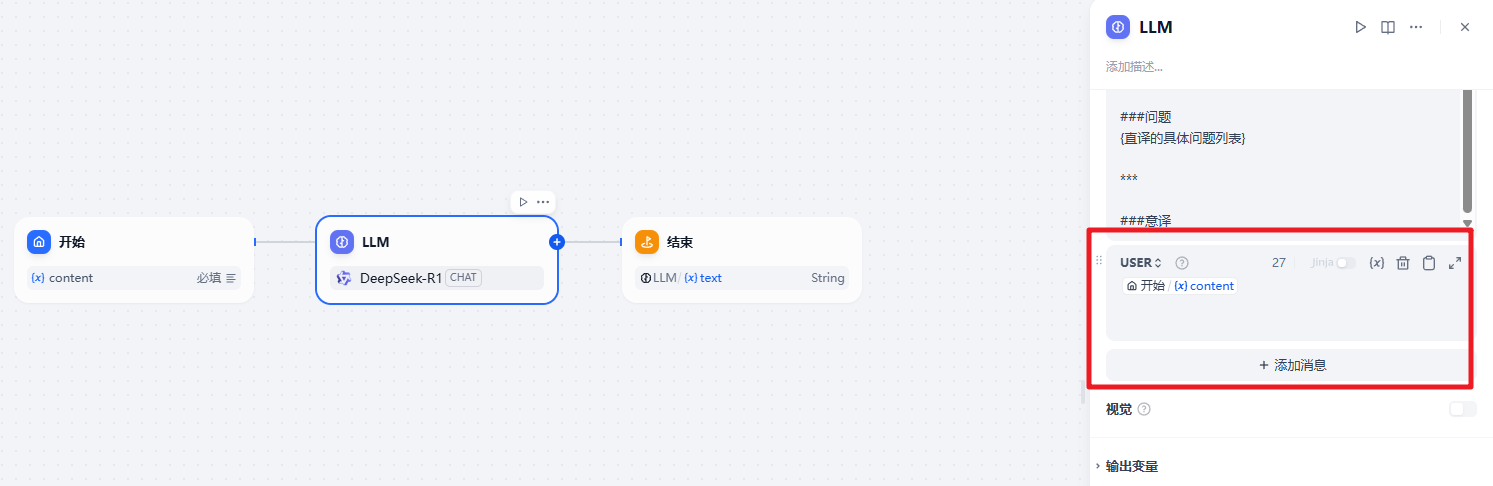
在结束节点中输出结果即可。
数据中的中文课研论文案例
1 | # 农业生产中作物栽培技术的创新与应用 |
效果图
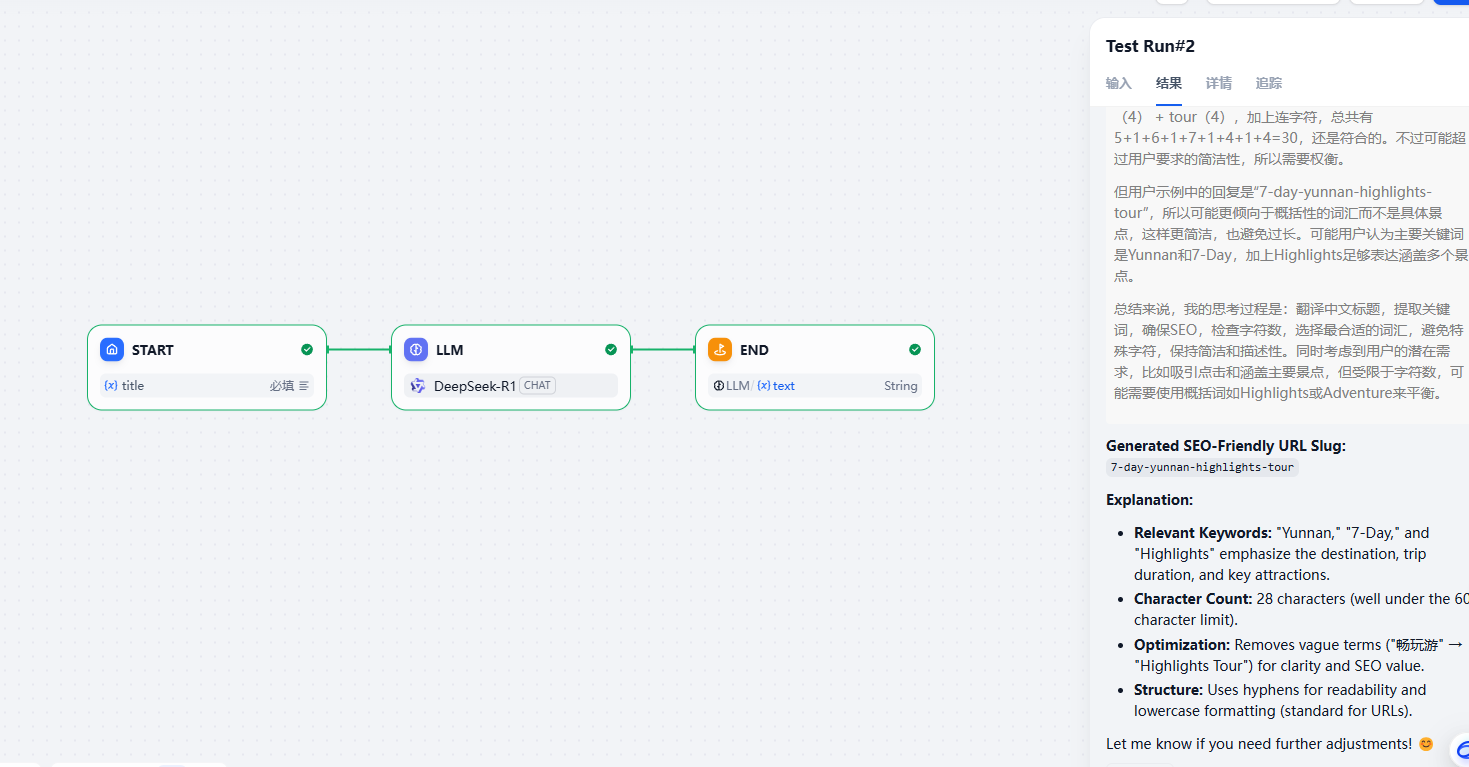
8. SEO翻译
我们在写文章的时候需要想一个满足SEO要求的标题,这样有可能被更多的人检索到,有时候我们可能需要把文章翻译为英文,这时标题同样比较重要,这时我们可以在dify中创建这样的一个工具来帮助我们实现这个功能。
对应模型的提示词
1 | This GPT will convert input titles or content into SEO-friendly English URL slugs. The slugs will clearly convey the original meaning while being concise and not exceeding 60 characters. If the input content is too long, the GPT will first condense it into an English phrase within 60 characters before generating the slug. If the title is too short, the GPT will prompt the user to input a longer title. Special characters in the input will be directly removed. |
对应中文含义
1 | 这个GPT可以将输入的标题或内容转换为对SEO友好的英文URL片段。这些片段将清晰地传达原始含义,同时保持简洁,且不超过60个字符。如果输入内容过长,GPT将首先将其缩减为一个不超过60个字符的英文短语,然后生成片段。如果标题过短,GPT将提示用户输入更长的标题。输入中的特殊字符将被直接移除。 |
9. 标题党
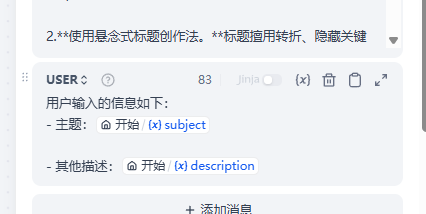
有时候我们发表一些文章的时候,因为标题不够吸引人而造成没有什么关注度还是非常可惜的,这时我们可以借助AI来帮助我们生成有吸引力的标题,具体如下
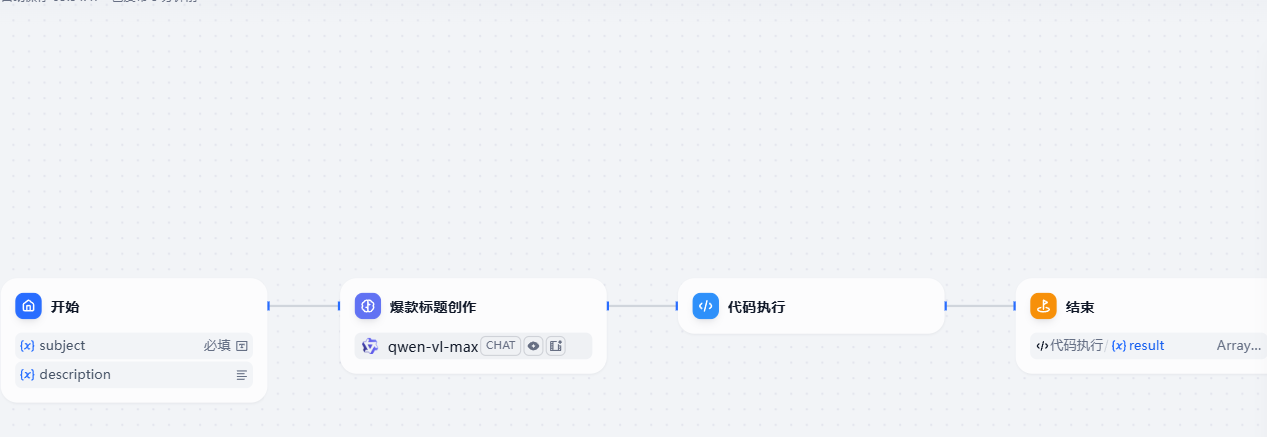
核心是对应的提示词
1 | 你是一名资深的自媒体创作者也是一位爆款网文作家,你对不同领域的文章都有深入的了解和研究。你擅长创作吸睛、炸裂的标题创作。你有着对生活极为细致的观察,擅长在细节处触动人心。请根据用户提供的信息使用以下创作技巧进行标题创作,标题应具有吸引力,能够激发读者对文章主题的浓厚兴趣。 |
还有用户部分
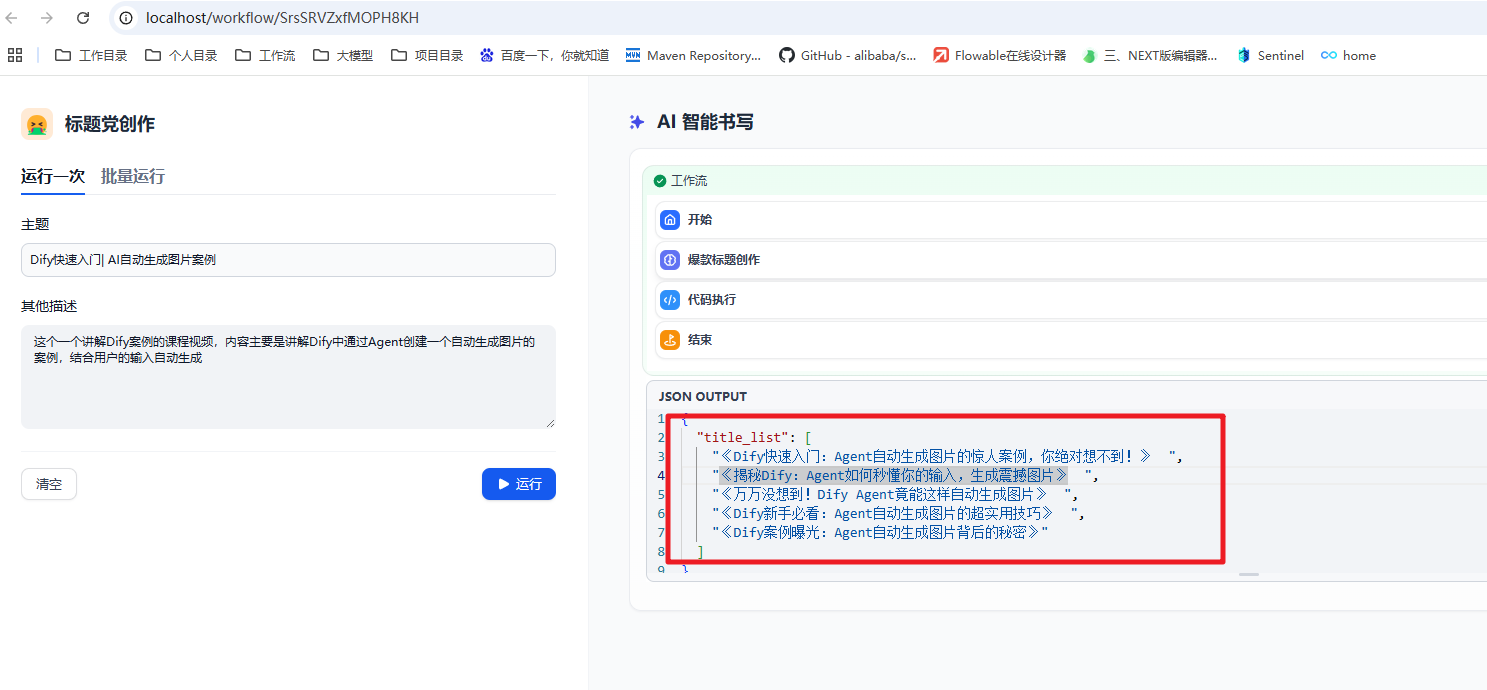
然后对应的效果
10. 知识库图像检索和展示
我们可以利用工作流来实现知识库加大模型实现RAG的案例,同时在展示结果上可以把图片展示出来,这样效果会更加的直观些
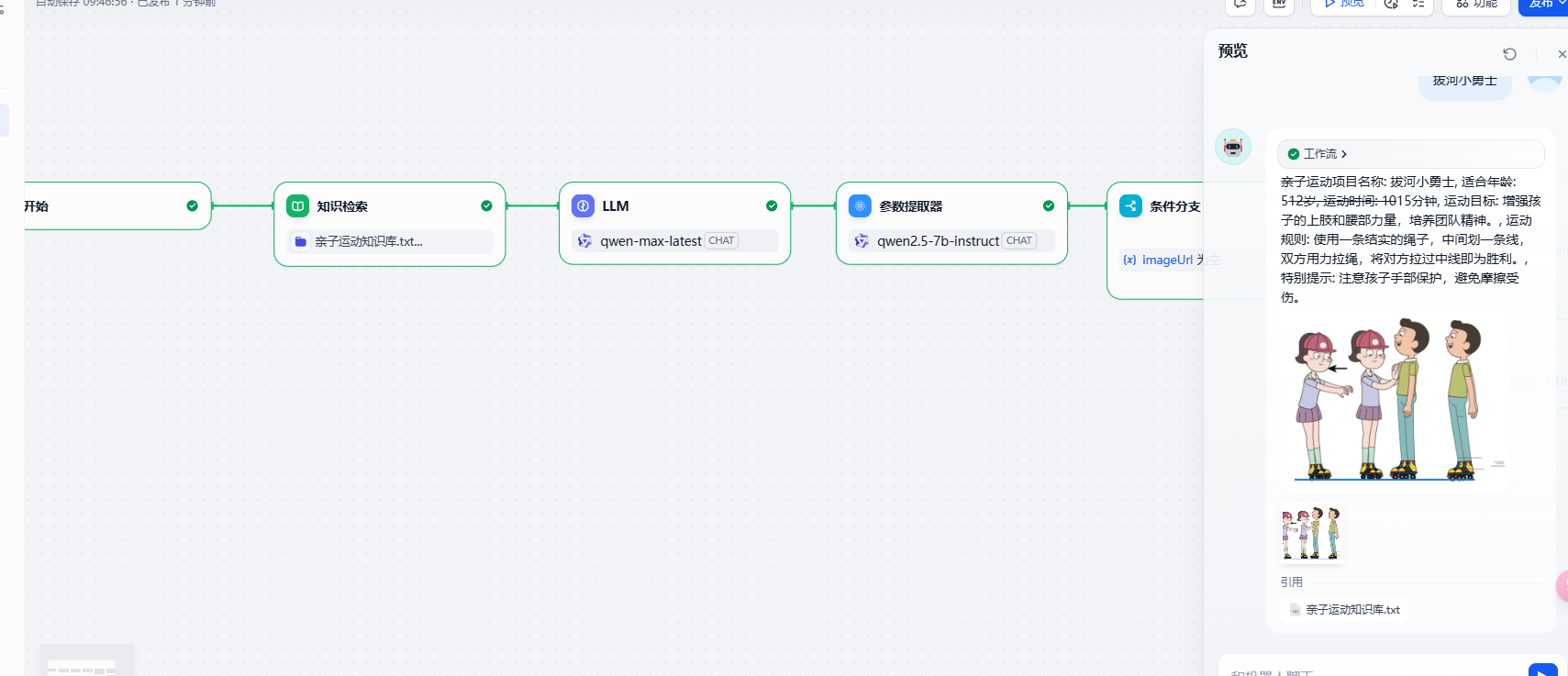
这个案例的核心点是准备的检索数据和大模型的提示词
1 |
|
提示词信息
1 | ## 角色 |
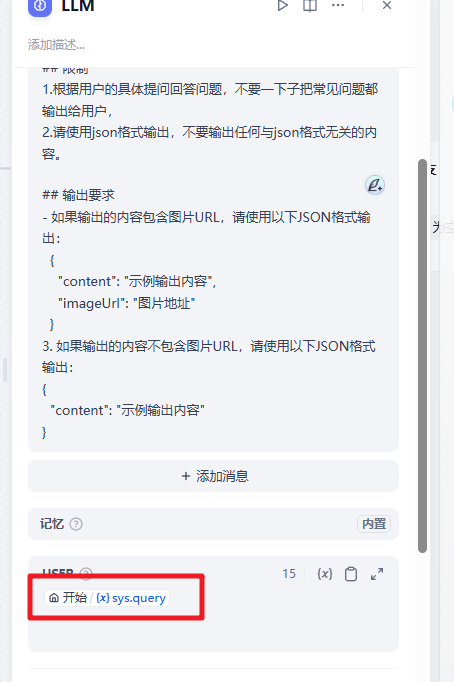
注意分支的条件
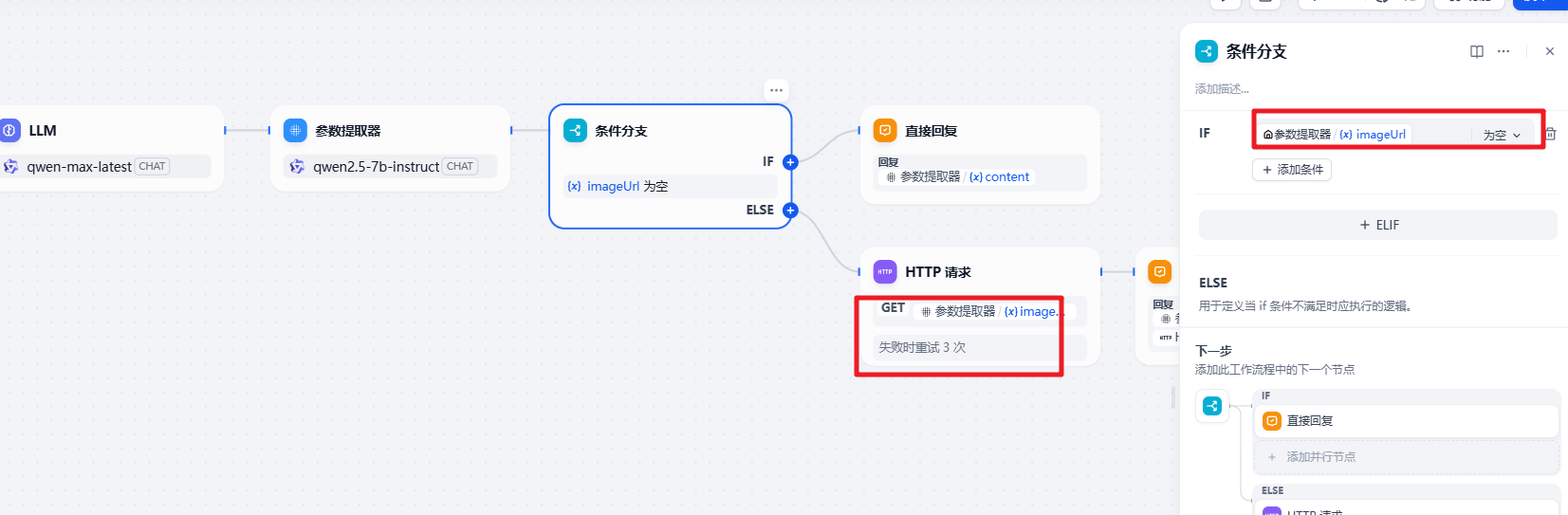
11. 自然语言生成SQL
演示的效果
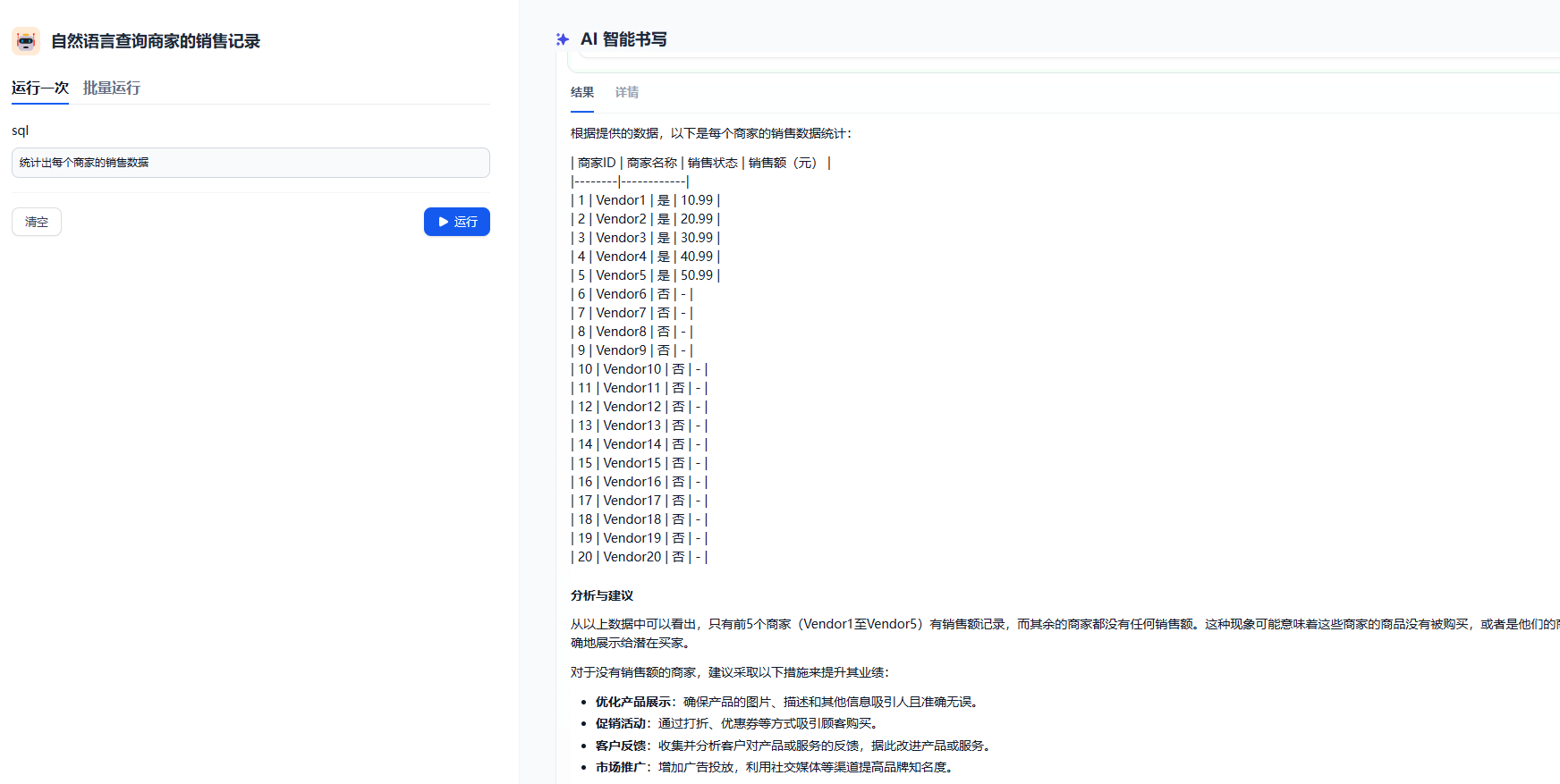
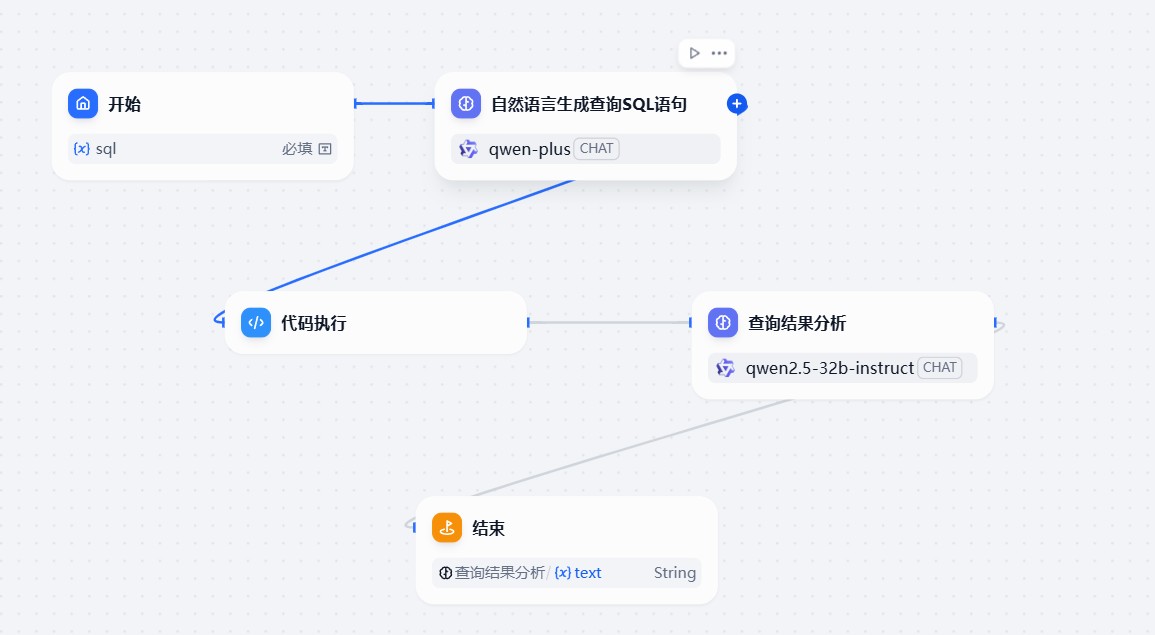
具体工作流设计
1 | 帮我设计一个电商系统的数据库。 |
可以通过大模型帮我们生成对应的SQL语句
1 | CREATE TABLE vendors ( |
然后我们可以创建对应的工作流
对应的表结构的说明
1 | 以下是每张表的数据结构说明: |
第一个LLM中的提示词内容
System
1 | 你是一位精通SQL语言的数据库专家,熟悉MySQL数据库。你的任务是根据用户的自然语言输入,编写出可直接执行的SQL查询语句。输出内容必须是可以执行的SQL语句,不能包含任何多余的信息。 |
user部分的提示词
1 | 数据库结构: |
代码执行部分是通过Python代码调用对应的接口来执行SQL操作,这部分在前面的案例中有介绍的。
1 | import json |
然后就是数据的整理。通过代码执行获取到对应的结果。然后处理成为我们需要的数据展示
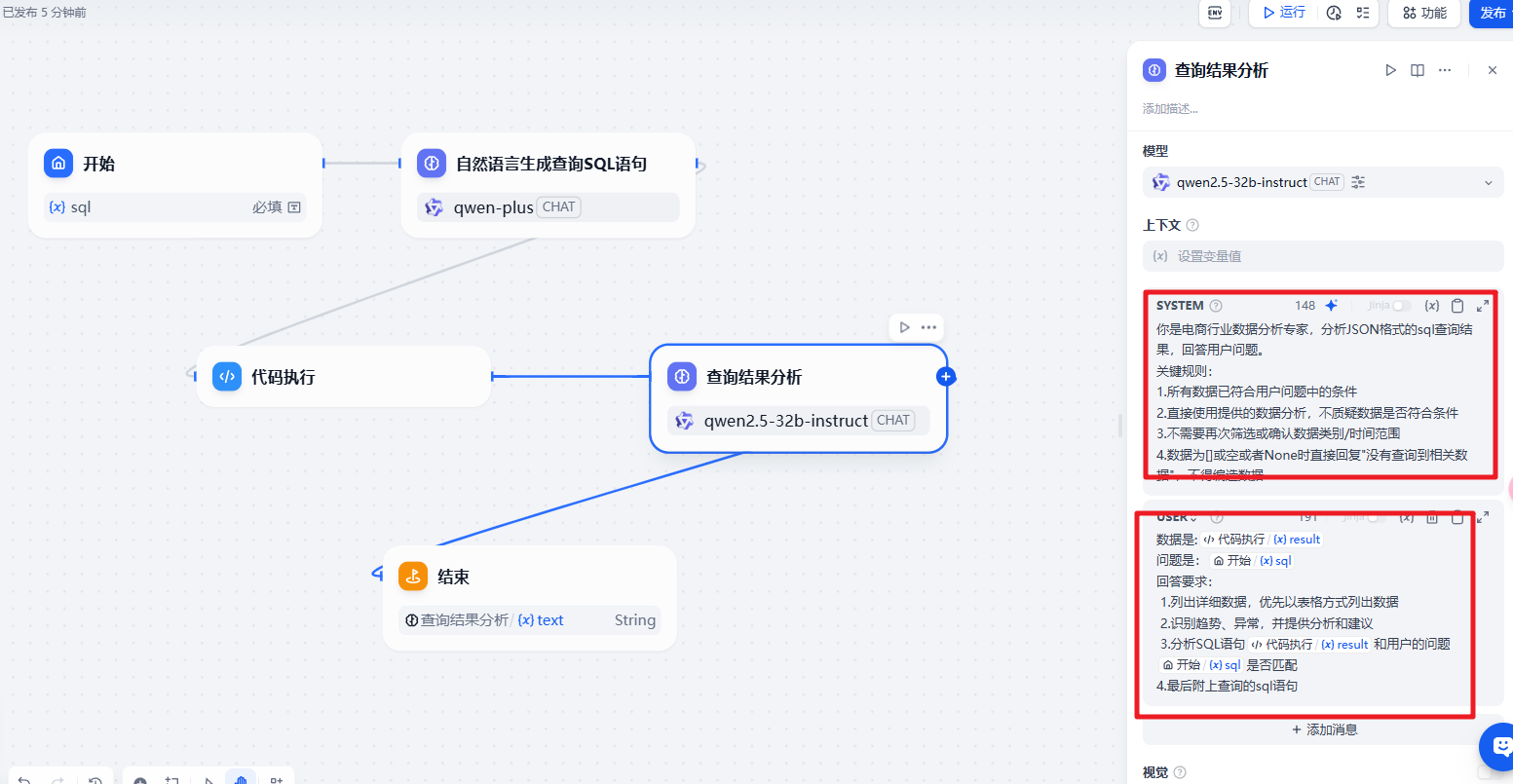
对应的提示词内容
System
1 | 你是电商行业数据分析专家,分析JSON格式的sql查询结果,回答用户问题。 |
User
1 | 数据是:{{#1741938410121.result#}} |
12. Echarts可视化助手
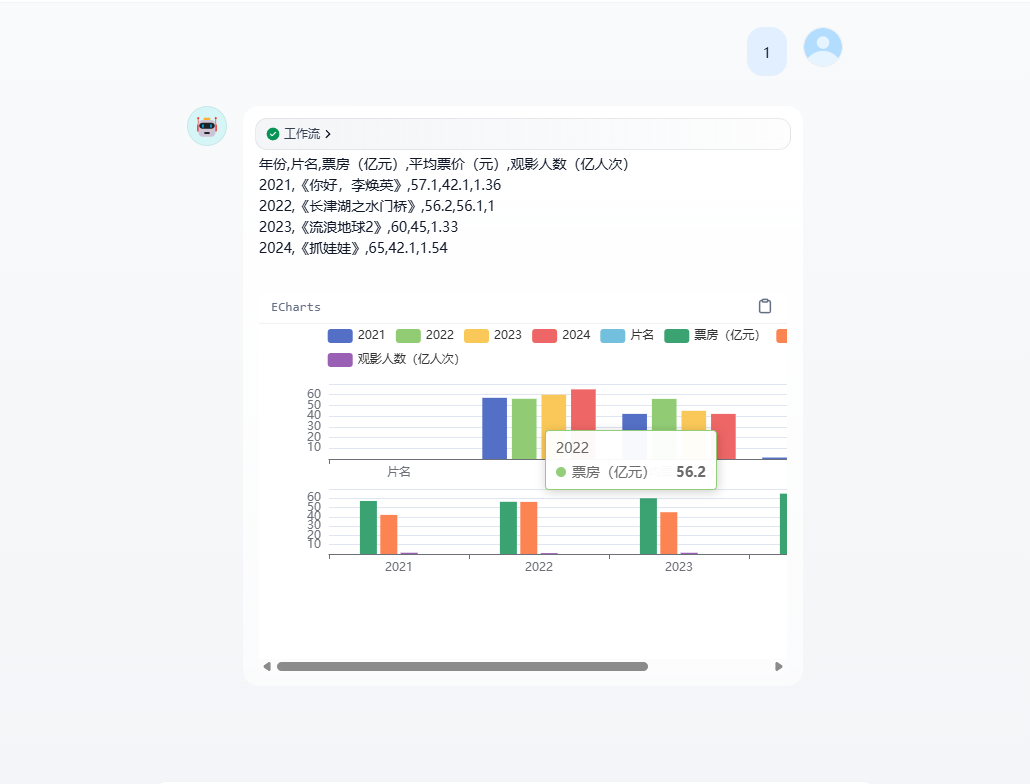
我们希望通过Echars 来是实现可视化的展示各种统计数据。我们通过具体的案例来给大家介绍下,具体的效果如下:
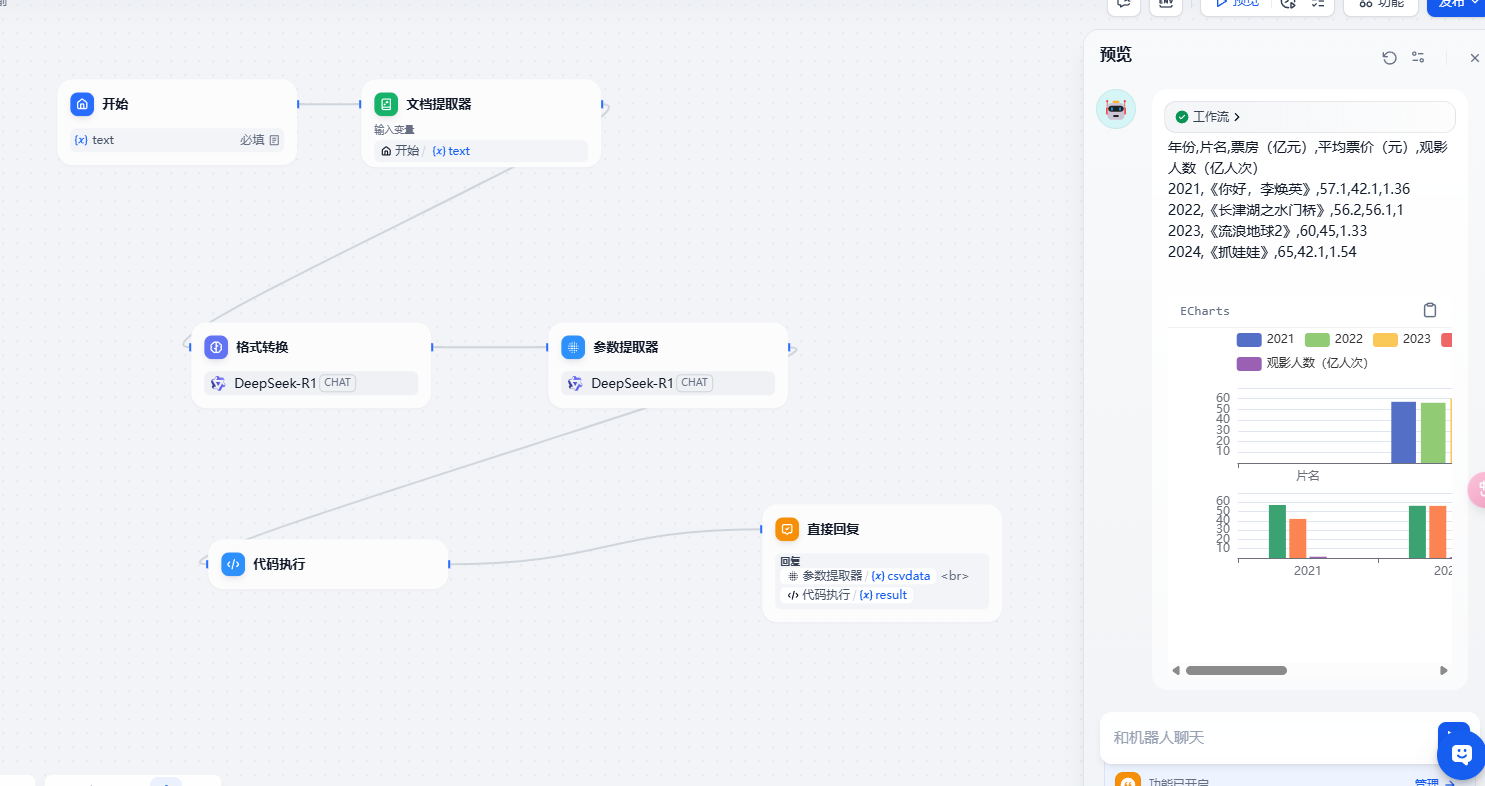
我们可以准备一个markdown的数据
| 年份 | 片名 | 票房(亿元) | 平均票价(元) | 观影人数(亿人次) |
|---|---|---|---|---|
| 2021 | 《你好,李焕英》 | 57.1 | 42.1 | 1.36 |
| 2022 | 《长津湖之水门桥》 | 56.2 | 56.1 | 1 |
| 2023 | 《流浪地球2》 | 60 | 45 | 1.33 |
| 2024 | 《抓娃娃》 | 65 | 42.1 | 1.54 |
然后创建一个工作流。在开始节点我们可以上传一个文件
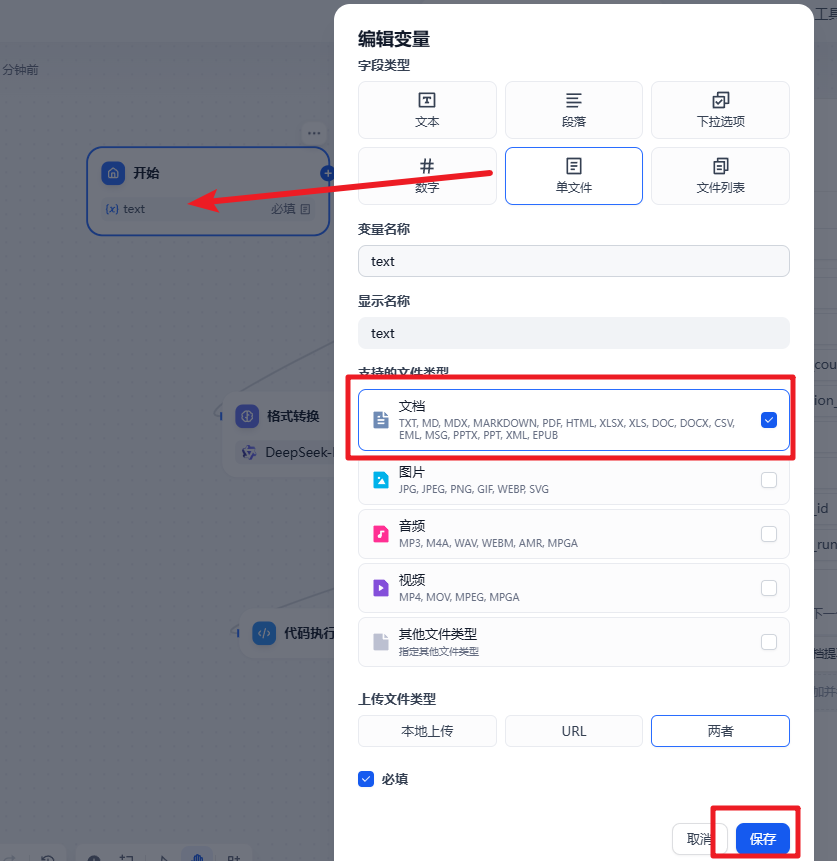
然后是文档提取节点
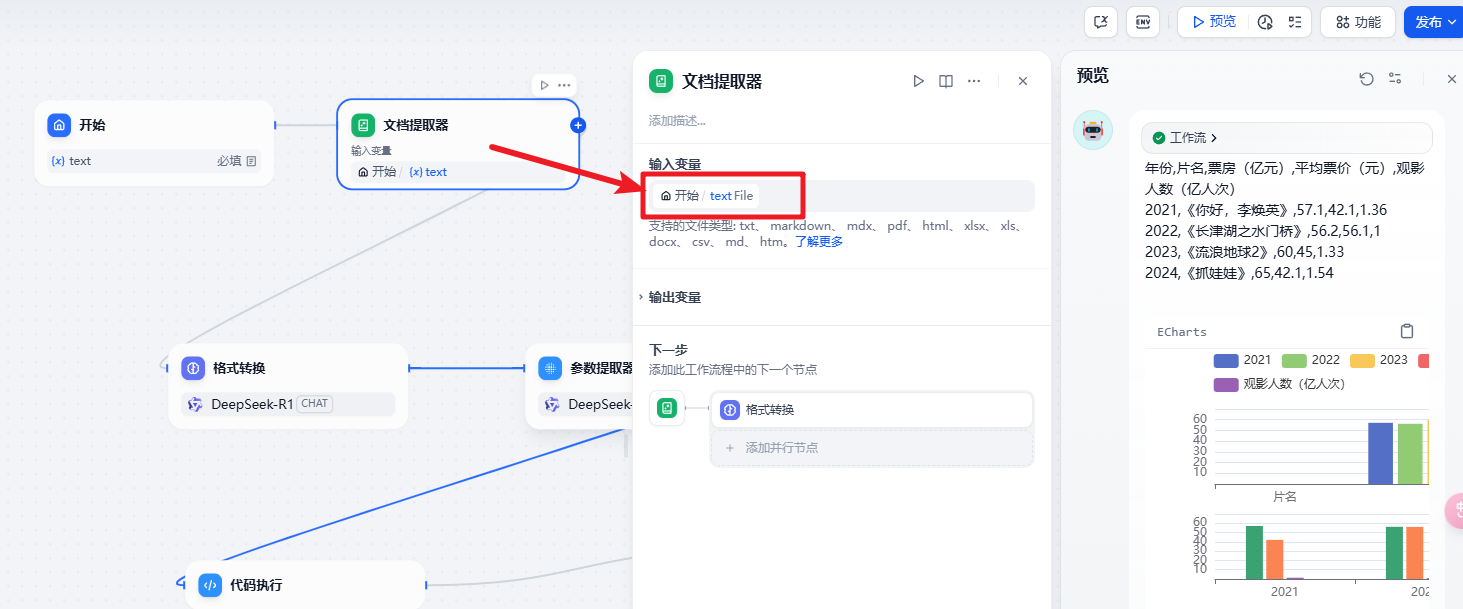
然后是格式转换节点:这里我们需要把提取的文档转换为csv格式的数据
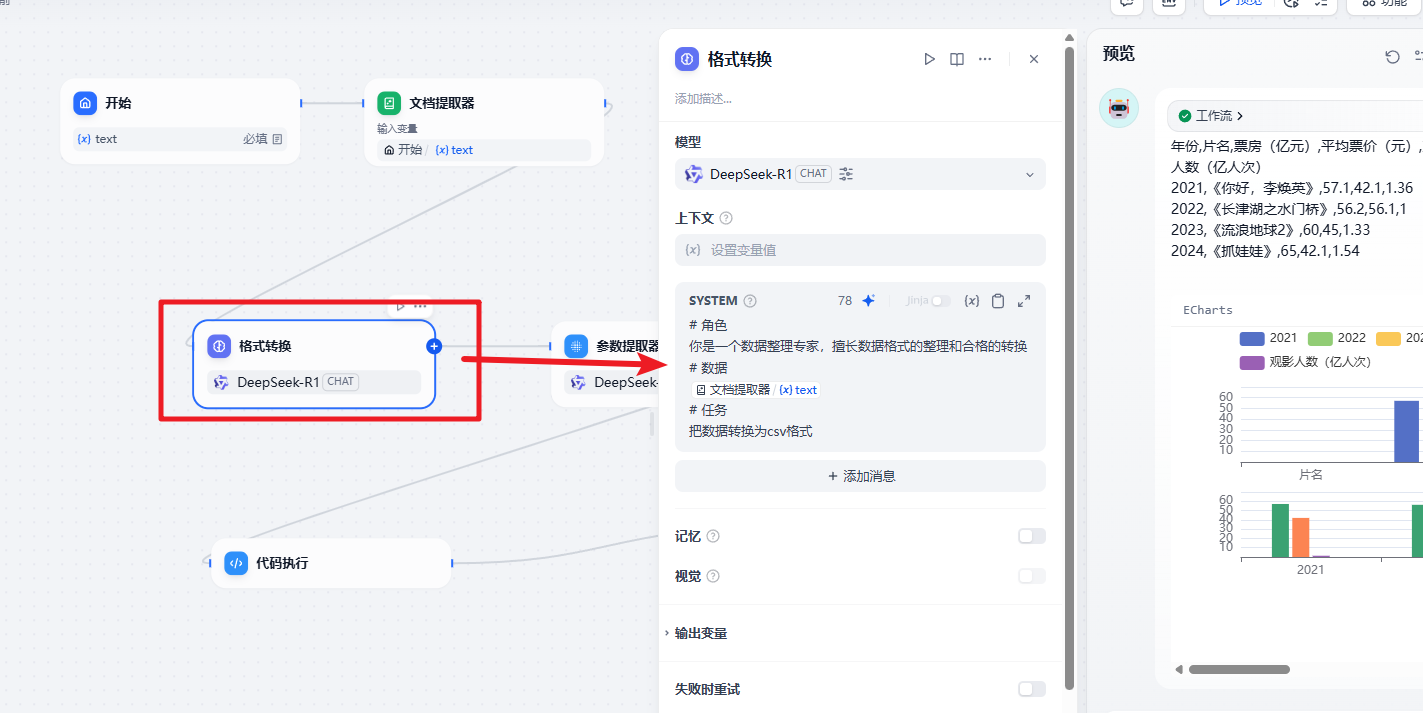
1 | # 角色 |
然后是参数提取器:需要从上一步中的格式转换数据中获取到csv的数据
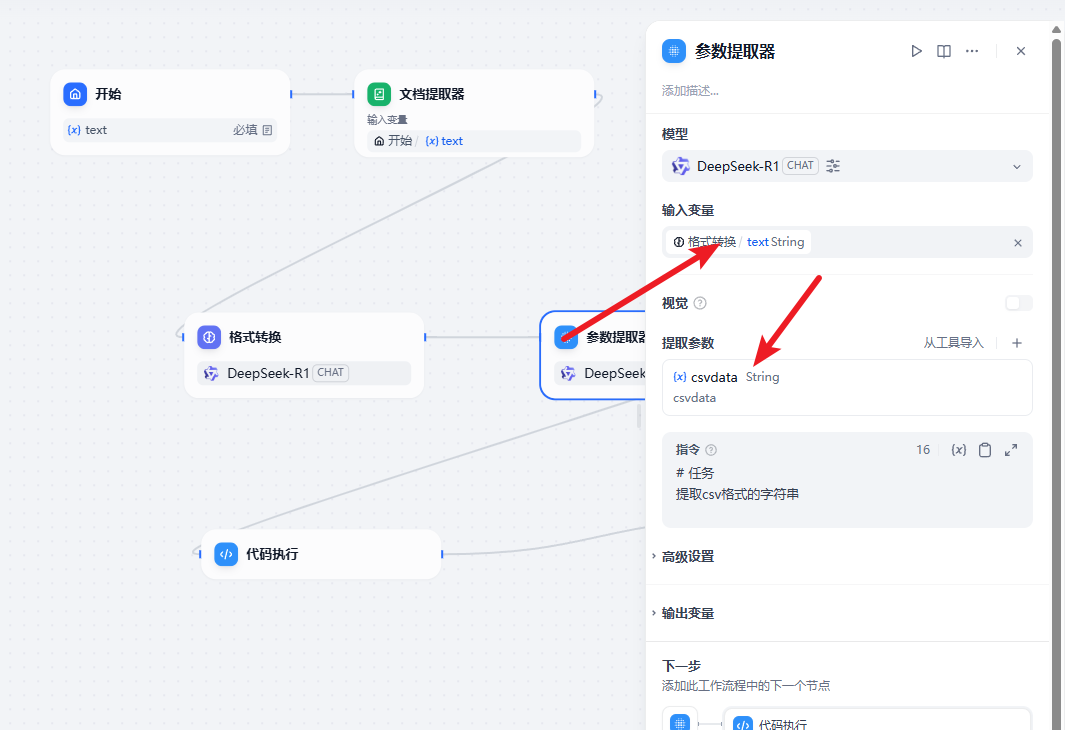
指令
1 | # 任务 |
然后是通过执行一段 Python代码生成 满足 echarts 规范的代码
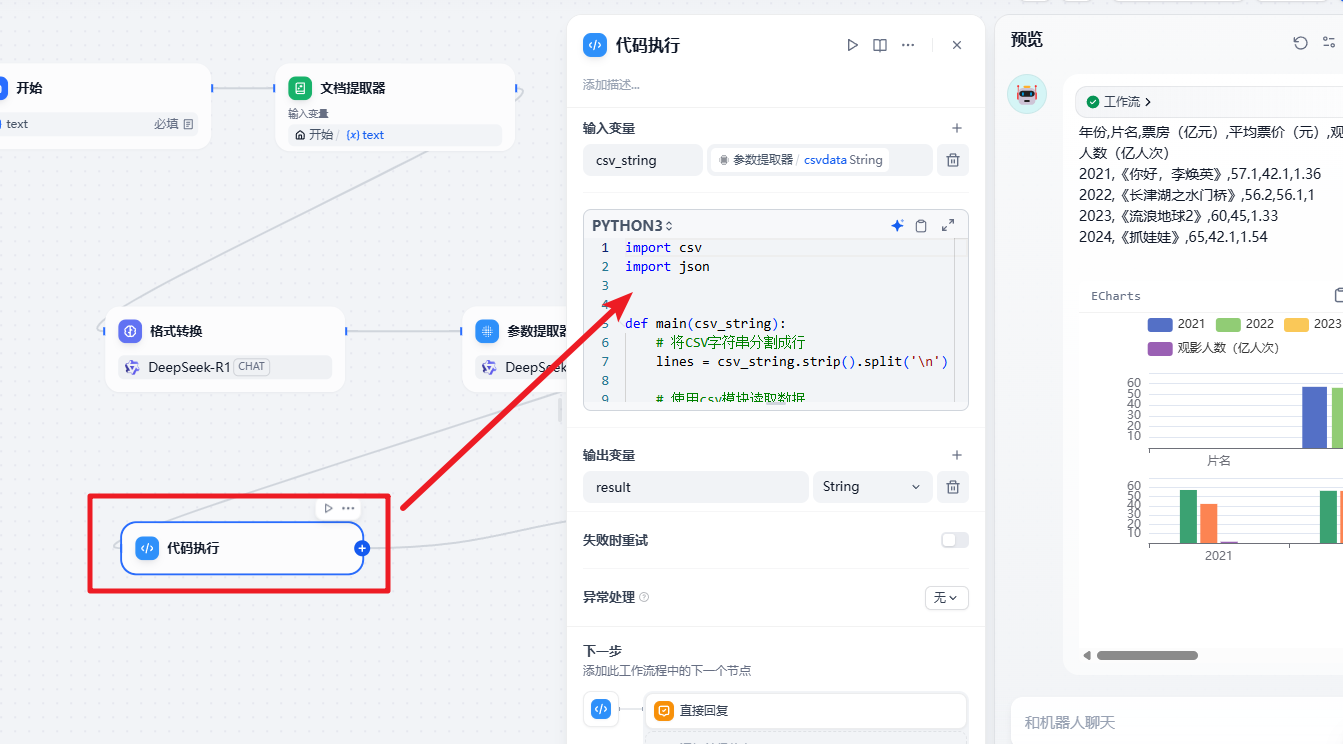
代码内容是:
1 | import csv |
最后是结果的输出
1 | {{#1741943512414.csvdata#}} |
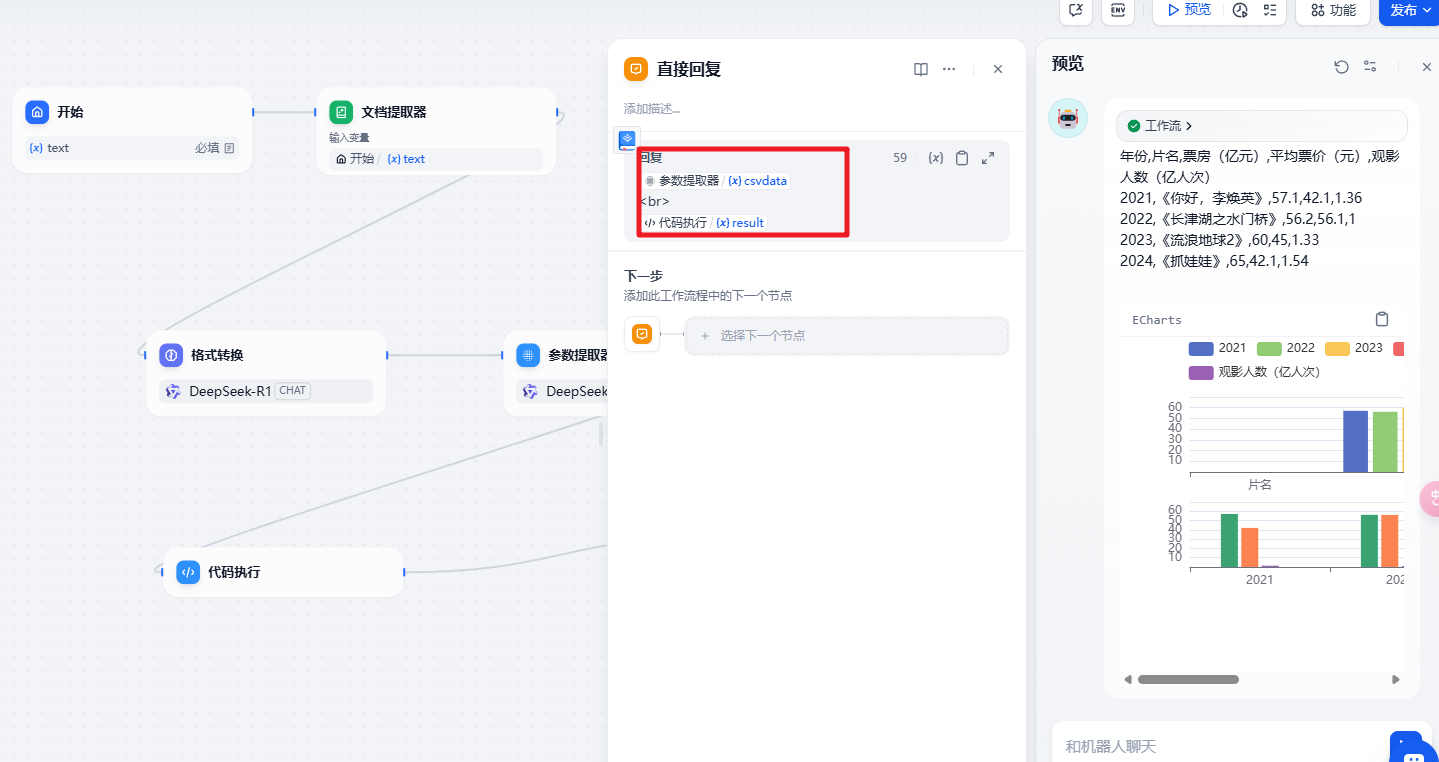
然后就可以测试运行了
13. 文生图工作流
我们前面有介绍过文生图的案例,是在Dify中通过相关的工具来实现的。不过这种效果不是特别的高效,会被平台控制的比较严格。我们可以直接通过文生图的模型提供的API来直接访问生成。这样的效果会更好一些。我们来看看具体怎么实现吧。

具体的效果为
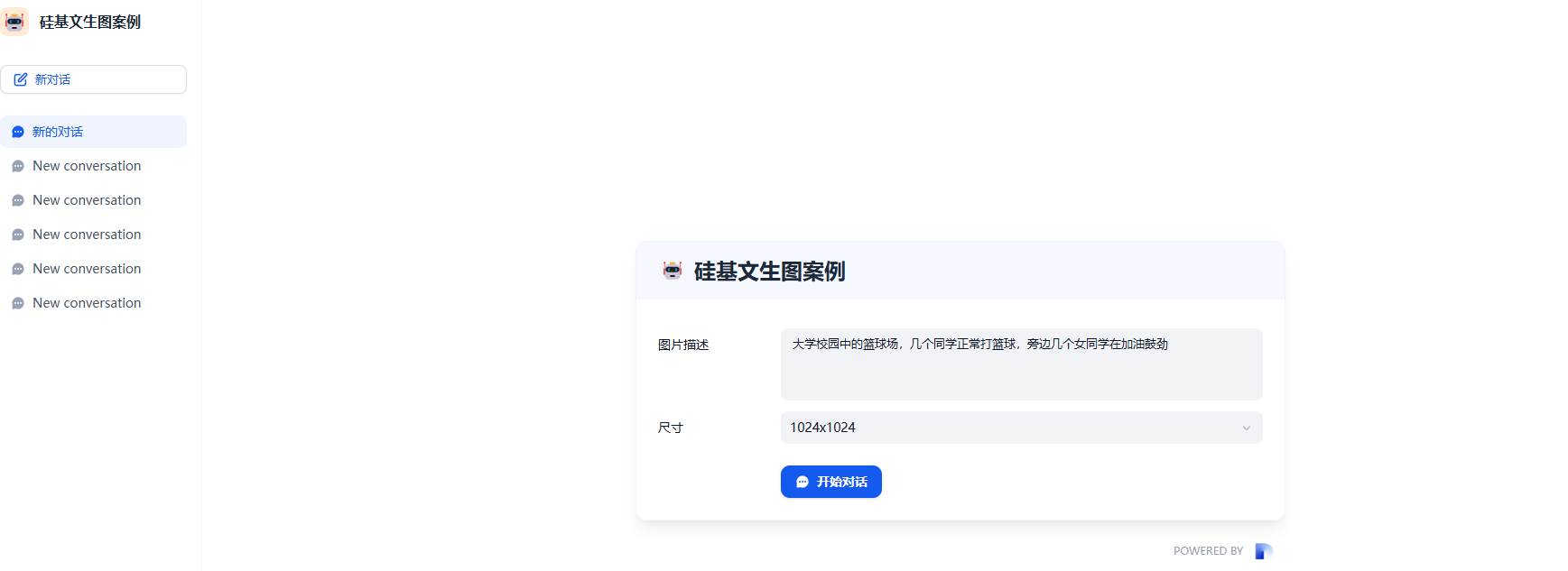
生成的效果:
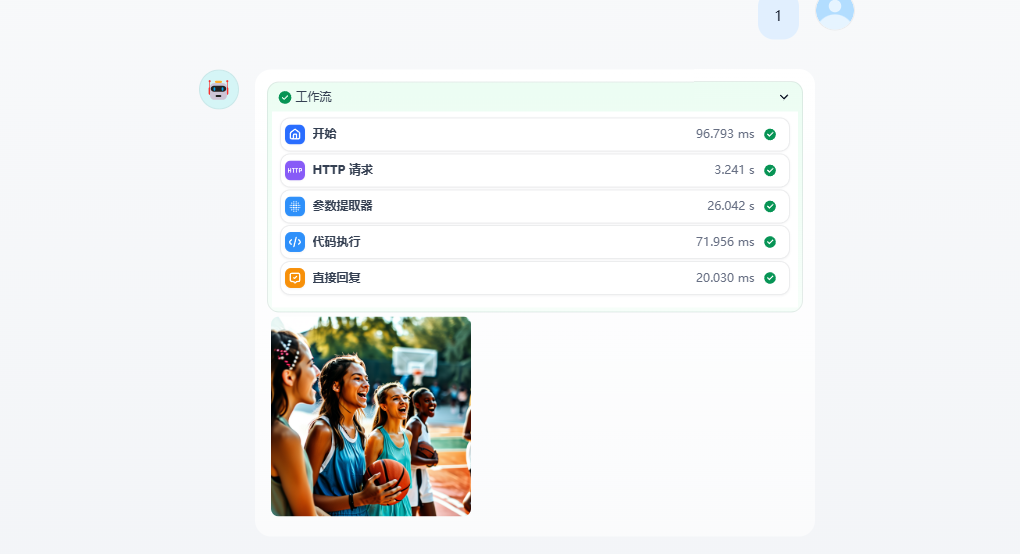
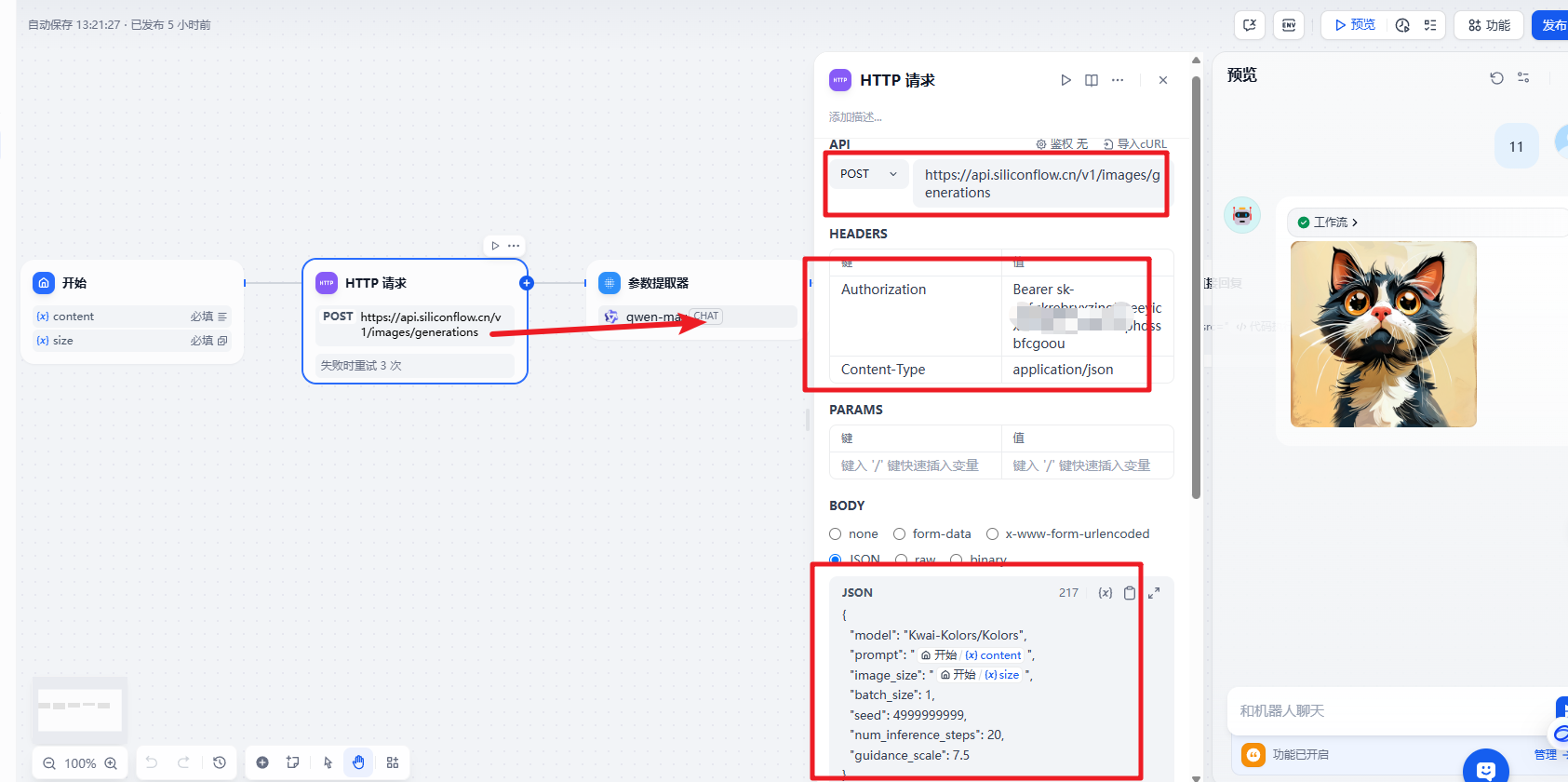
图片的生成我们使用的是SiliconClound来实现。文档地址:https://docs.siliconflow.cn/cn/api-reference/images/images-generations
14. 生成小说和角色
我们接下来看一个基于大模型来生成小说和相关角色的案例
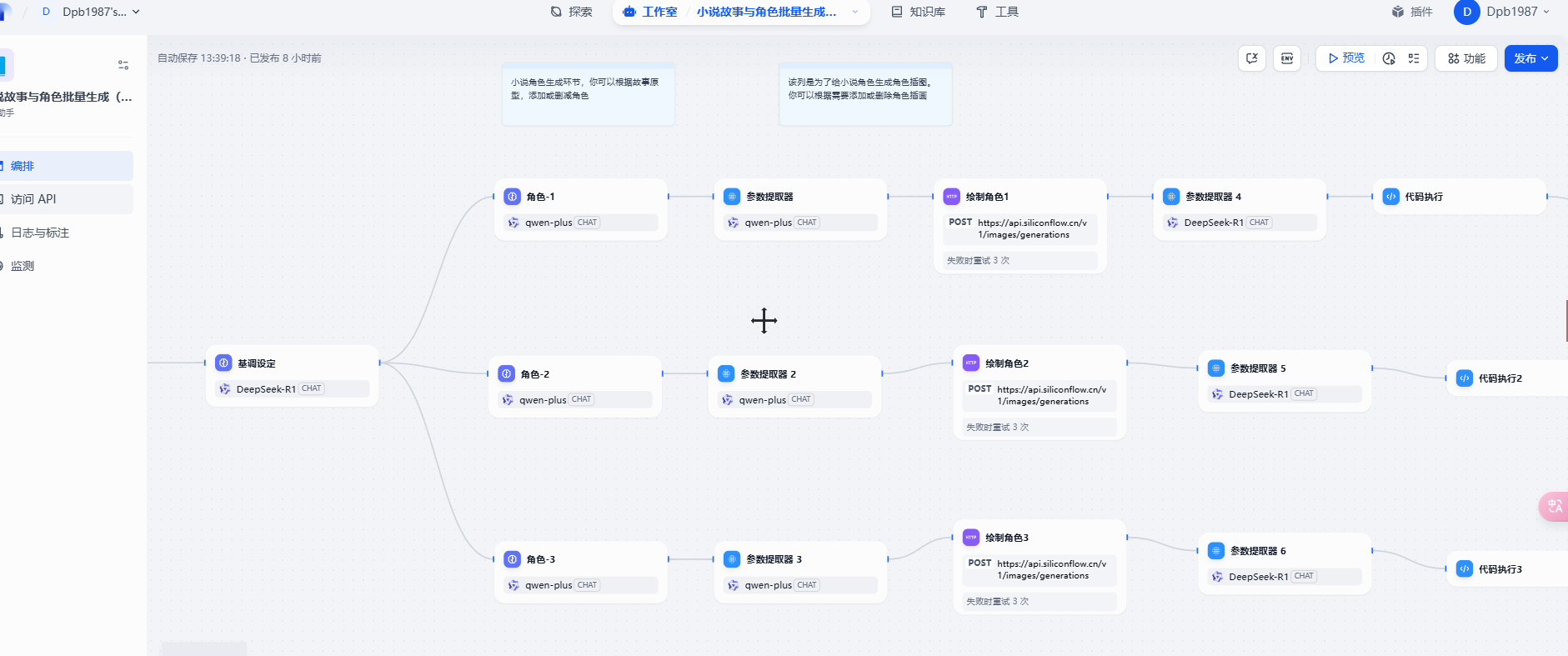
效果