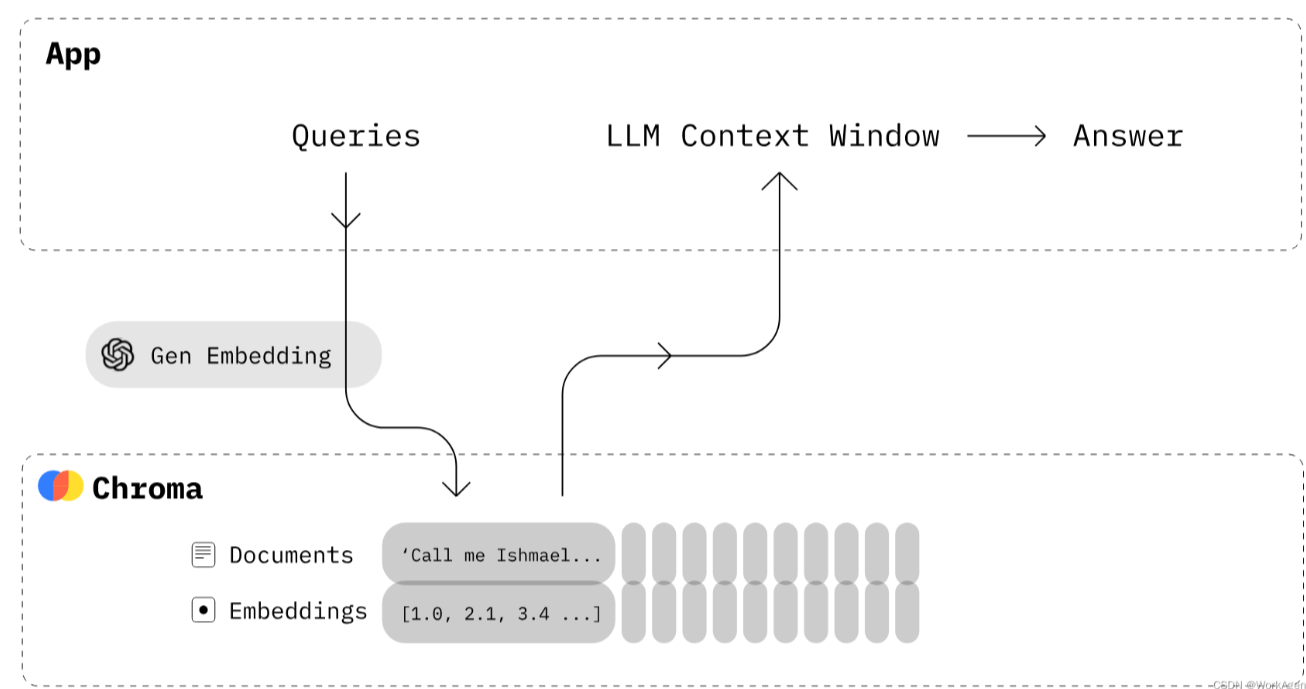
基本介绍 什么是矢量存储? 向量存储是专门为有效地存储和检索向量嵌入而设计的数据库。之所以需要它们,是因为像 SQL 这样的传统数据库没有针对存储和查询大型向量数据进行优化 。
嵌入在高维空间中以数字向量格式表示数据(通常是非结构化数据,如文本)。传统的关系数据库不太适合存储和搜索这些向量表示。
向量存储可以使用相似性算法对相似的向量进行索引和快速搜索 。它允许应用程序在给定目标向量查询的情况下查找相关向量。
在个性化聊天机器人的情况下,用户输入生成式 AI 模型的提示。然后,该模型使用相似性搜索算法在文档集合中搜索相似文本。然后,由此产生的信息用于生成高度个性化和准确的响应。这是通过在向量存储中嵌入和向量索引来实现的。
什么是ChromaDB? ChromaDB是一个开源矢量存储,用于存储和检索矢量嵌入。它的主要用途是保存嵌入和元数据,以便以后由大型语言模型使用。此外,它还可用于文本数据的语义搜索引擎。
Chroma DB主要特点:
支持不同的底层存储选项,例如用于独立的 DuckDB 或用于可扩展性的 ClickHouse。
提供 Python 和 JavaScript/TypeScript 的 SDK。
专注于简单性、速度和支持性分析。
ChromaDB是如何工作的?
首先,必须创建一个类似于关系数据库中的表的集合。默认情况下,Chroma 使用 将文本转换为嵌入,但您可以修改集合以使用其他嵌入模型。all-MiniLM-L6-v2
将具有元数据和唯一 ID 的文本文档添加到新创建的集合中。当您的收藏收到文本时,它会自动将其转换为嵌入。
通过文本或嵌入查询集合以接收相似的文档。您还可以根据元数据筛选出结果。
在下一部分中,我们将使用 Chroma 和 OpenAI API 来创建我们自己的矢量数据库。
ChromaDB 的核心概念
客户端(Client) : 这是你与 ChromaDB 交互的接口。ChromaDB 支持多种部署模式,你可以用本地模式(数据存在本地文件)、客户端-服务器模式(连接远程服务器)或持久化模式(数据存到指定路径)。
集合(Collection) : 集合是存储向量、文档和元数据的逻辑单元。你可以把它想象成关系数据库中的一个“表”,或者一个特定主题的文档库。你的所有相关数据都会放到一个集合里。
文档(Document) : 这是你的原始数据,通常是文本。当你把文档添加到集合时,ChromaDB 会自动(或使用你指定的模型)将其转换为向量。
嵌入(Embedding) : 文档的数字表示。这是语义搜索的基础。
元数据(Metadata) : 附加到文档或向量上的描述性信息。比如,你存储了一篇文章的向量,它的元数据可以是文章的标题、作者、发布日期等。元数据对于过滤和查询结果非常有用。
ID : 每个文档和其对应的向量都必须有一个唯一的 ID。(字符串或 UUID)
使用 安装Chromadb 初始化Chroma客户端 内存模式:
1 2 3 4 import chromadbclient = chromadb.Client() client = chromadb.PersistentClient(path="/path/to/db" )
http客户端:
1 client = chromadb.HttpClient(host="localhost" , port="8000" )
创建/获取集合 (Collection) 集合(collection)是在chroma数据库的作用类似Mysql的表,存储向量数据(包括文档和其他源数据)的地方,下面创建一个集合:
1 2 3 4 5 collection = client.create_collection( name="my_knowledge_base" , embedding_function=embedding_fn, metadata={"hnsw:space" : "cosine" } )
获取现有集合:
1 2 3 4 collection = client.get_collection( name="my_knowledge_base" , embedding_function=embedding_fn )
向集合添加数据 (Add/ Upsert) 方式一:让 ChromaDB 自动生成向量 (推荐,需提供 embedding_function)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from sentence_transformers import SentenceTransformermodel = SentenceTransformer('all-MiniLM-L6-v2' ) def embedding_fn (texts: list [str ] ) -> list [list [float ]]: return model.encode(texts).tolist() collection = client.get_collection(name="my_knowledge_base" , embedding_function=embedding_fn) collection.add( documents=[ "The cat sat on the mat." , "Dogs are great companions." , "The sun rises in the east." ], metadatas=[ {"source" : "sentence1" , "type" : "example" }, {"source" : "sentence2" , "type" : "example" }, {"source" : "sentence3" , "type" : "fact" } ], ids=["id1" , "id2" , "id3" ] )
方式二:自己提供预计算好的向量 (如果不提供 embedding_function 或需要精细控制)
1 2 3 4 5 6 7 8 9 10 11 12 13 precomputed_embeddings = [ [0.1 , 0.2 , ..., 0.5 ], [0.6 , -0.3 , ..., 0.8 ], [-0.2 , 0.4 , ..., 0.1 ] ] collection.add( embeddings=precomputed_embeddings, documents=[...], metadatas=[...], ids=["id1" , "id2" , "id3" ] )
upsert 方法:id 已存在,则更新该条目;如果不存在,则添加新条目。参数与 add 相同。
查询集合 (Query) 这是另一个核心步骤。根据查询文本或向量,找到集合中最相似的条目。
使用查询文本 (ChromaDB 自动用 embedding_function 转为向量):
1 2 3 4 5 6 results = collection.query( query_texts=["Where does the sun rise?" ], n_results=2 , )
使用查询向量 (自己提供):
1 2 3 4 5 6 query_vector = embedding_fn(["Where does the sun rise?" ])[0 ] results = collection.query( query_embeddings=[query_vector], n_results=2 )
理解返回结果 (results): results 是一个字典,包含:
ids: 最相似条目的 ID 列表 (列表的列表,外层列表对应每个查询文本/向量)。
distances: 对应的距离 (越小越相似)。
metadatas: 对应的元数据。
documents: 对应的原始文档文本。
embeddings (如果 include=[‘embeddings’]): 对应的向量。
uris / data (通常不常用)。
1 2 3 print (results["ids" ]) print (results["documents" ]) print (results["distances" ])
管理数据 获取 (Get): 根据 ID 获取条目。
1 2 3 4 5 6 7 8 9 items = collection.get( ids=["id1" , "id2" ], )
更新 (Update): 更新指定 ID 的条目。需要提供要更新的字段 (embeddings, metadatas, documents)。未提供的字段保持不变。
1 2 3 4 5 6 collection.update( ids=["id2" ], metadatas=[{"source" : "updated_sentence2" , "type" : "example" }], documents=["Dogs are truly amazing companions." ] )
删除 (Delete): 删除指定 ID 或满足条件的条目。
1 2 3 4 5 6 7 8 collection.delete(ids=["id1" ]) collection.delete(where={"type" : {"$eq" : "example" }}) collection.delete(where_document={"$contains" : "cat" })
持久化存储 (重要!) 默认的 chromadb.Client() 是纯内存的。重启 Python 程序数据就没了!必须配置持久化。
使用 PersistentClient:
1 2 client = chromadb.PersistentClient(path="/path/to/db" )
下次启动时,使用相同的 path 创建 PersistentClient,然后 get_collection 就能恢复之前的数据。
关键注意事项
务必指定 embedding_function: 除非你有特殊原因需要自己管理向量,否则在创建/获取集合时指定嵌入函数是最高效和不易出错的方式。
务必持久化 (PersistentClient): 除非你明确只需要临时内存数据,否则一定要用 PersistentClient 并指定存储路径,否则辛苦添加的数据会丢失。
提供 documents: 强烈建议在 add 时提供原始文档 (documents)。这样在 query 时,ChromaDB 可以直接返回最相似的文本内容,无需你再根据 ID 去外部查找,非常方便。
善用 metadatas: 元数据是强大的过滤工具。提前规划好你需要哪些元数据字段(如 source, author, date, category),并在添加数据时填充。查询时用 where 参数进行过滤可以显著缩小搜索范围,提高速度和精度。
理解距离 (Distance): query 返回的 distances 值取决于集合创建时配置的 hnsw:space。”l2” 是欧氏距离 (越小越好),”cosine” 是余弦相似度距离 (0 表示完全同向,1 表示正交,2 表示完全反向,通常也是越小表示越相似)。注意看文档确认你使用的空间和距离含义。
嵌入模型的选择至关重要: ChromaDB 只是存储和检索向量。向量的质量完全取决于你使用的嵌入模型。对于文本,像 all-MiniLM-L6-v2 (本地), text-embedding-3-small (OpenAI API) 都是不错的起点。选择适合你任务和数据量的模型。
upsert 是更新数据的好方法: 比先 delete 再 add 更简洁高效。
过滤语法: where 和 where_document 使用类似 MongoDB 的查询语法。查看 ChromaDB 文档学习具体操作符 ($eq, $ne, $gt, $gte, $lt, $lte, $in, $nin, $contains 等)。
性能考量:
数据量很大时,查询速度会变慢。确保 n_results 设置合理。
ChromaDB 在添加数据时会自动构建索引(默认是 HNSW)。大量数据添加后,索引构建可能需要时间。
对于生产级超大向量数据集,可能需要考虑更专业的向量数据库(如 Milvus, Pinecone, Weaviate 等),但 ChromaDB 对于中小规模应用和原型开发非常出色。
完整流程 项目目录结构 1 2 3 4 5 6 7 8 chroma-llm-demo/ ├── main.py ├── .env ├── requirements.txt └── docs/ ├── biology.txt ├── computer.txt └── history.txt
biology.txt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 一、生物的基本特征 所有生物都具备 4 个核心特征,是区分生物与非生物的关键: 新陈代谢:生物与环境持续交换物质和能量的过程,分为 “同化作用”(如植物通过光合作用合成有机物)和 “异化作用”(如动物通过呼吸分解有机物释放能量),一旦停止,生命即终止。 繁殖能力:生物能产生后代延续物种,分无性繁殖(如细菌分裂、酵母菌出芽,后代遗传物质与亲代一致)和有性繁殖(如人类、开花植物,后代结合父母双方遗传物质,具有多样性)。 应激性:生物能对外界刺激作出反应,如含羞草受触碰闭合叶片(物理刺激)、植物向光生长(向光性,对光照刺激的适应)。 遗传与变异:遗传保证物种稳定性(如狗生狗、猫生猫),变异推动物种进化(如长颈鹿祖先因脖子长度差异,长脖子个体更易获取高处树叶,逐渐演化成现物种)。 二、生物的核心分类 根据细胞结构,生物可分为两大类,这是生物学分类的基础框架: 原核生物:无成形细胞核(遗传物质裸露在细胞质中),结构简单,如细菌(大肠杆菌、乳酸菌)、蓝藻(能进行光合作用的单细胞生物,是最早产生氧气的生物之一)。 真核生物:有成形细胞核(遗传物质被核膜包裹),结构更复杂,包含所有多细胞生物及部分单细胞生物,如动物(人类、昆虫)、植物(树木、花草)、真菌(蘑菇、酵母菌)。 三、生态系统的基本组成 生态系统是生物与环境的统一整体,核心成分包括 3 类: 生产者:主要是绿色植物,通过光合作用将太阳能转化为化学能,为整个生态系统提供能量基础。 消费者:依赖生产者获取能量,如草食动物(兔子)、肉食动物(狐狸)。 分解者:主要是细菌、真菌,将动植物遗体分解为无机物(如二氧化碳、无机盐),回归环境供生产者再利用,完成物质循环。
computer.txt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 一、计算机基础构成 计算机核心由 “硬件 + 软件” 组成,二者协同实现功能: 硬件系统:物理设备,核心部件包括: CPU(中央处理器):相当于 “大脑”,负责运算与指令控制; 内存(RAM):临时存储数据,断电后数据丢失,影响运行速度; 存储设备(硬盘 / SSD):长期保存数据,如文档、软件等。 软件系统:驱动硬件的程序,分两类: 系统软件(如 Windows、macOS):管理硬件,为其他软件提供运行环境; 应用软件(如 Office、微信):满足特定需求,如办公、通讯。 二、关键发展节点 计算机发展历经四次 “革命”,推动技术飞跃: 1946 年:首台电子计算机 ENIAC:诞生于美国,用电子管组成,体积庞大(占地 167 平方米),标志计算机时代开启; 1950 年代:晶体管替代电子管:计算机体积缩小、功耗降低,进入 “第二代计算机”; 1969 年:互联网雏形 ARPANET:美国军方研发,后演变为全球互联网,打破信息传播边界; 2007 年:智能手机普及:整合计算机功能(如运算、联网),推动 “移动计算” 时代到来。 三、核心应用领域 计算机已渗透多场景,改变生产生活: 办公自动化:通过 Office、钉钉等软件,实现文档处理、远程协作,提升工作效率; 人工智能(AI):依托计算机算力,实现图像识别(如人脸识别)、语音助手(如 Siri)、自动驾驶等智能功能; 工业互联网:计算机与工业设备结合,实现生产线自动化控制、设备故障预警,推动 “智能制造” 升级。
history.txt 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 一、人类早期文明摇篮(公元前 3500 年 - 公元前 500 年) 四大文明古国奠定人类文明基石,均发源于大河流域: 古埃及(尼罗河):发明象形文字,建造金字塔(法老陵墓,体现天文与工程智慧),创立太阳历(按尼罗河泛滥周期制定,为公历雏形)。 古巴比伦(两河流域):颁布《汉谟拉比法典》(迄今已知世界最早成文法典,强调 “以眼还眼” 的司法原则),发明楔形文字。 古印度(印度河 - 恒河):创立种姓制度(分婆罗门、刹帝利等四级,影响社会结构千年),诞生佛教(释迦牟尼创立,主张 “众生平等”)。 中国(黄河 - 长江):夏商周三代确立分封制与宗法制,青铜文明鼎盛(如司母戊鼎),甲骨文成为最早成熟文字。 二、中古时期的文明交融(公元 5 世纪 - 15 世纪) 东西方文明通过交流互鉴发展: 东方:中国唐朝国力强盛,长安成为国际都会,玄奘西行取经(促进佛教中国化),鉴真东渡日本(传播唐文化,推动日本大化改新);阿拉伯帝国崛起,成为东西方桥梁(翻译希腊典籍、传播中国造纸术与印度数字)。 西方:欧洲处于中世纪,基督教主导社会,庄园经济为基础;12 世纪后城市兴起(如威尼斯、佛罗伦萨),为日后文艺复兴埋下伏笔。 三、近代历史的转折节点(15 世纪 - 20 世纪初) 关键事件推动世界格局巨变: 新航路开辟(15 世纪末):哥伦布发现美洲、达・伽马抵达印度,打破世界孤立状态,开启全球殖民时代。 工业革命(18 世纪 60 年代起):英国率先以蒸汽机为核心,从手工生产转向机器生产,推动生产力飞跃,催生工业资产阶级与无产阶级。 辛亥革命(1911 年):中国近代史上首次完全意义上的资产阶级革命,推翻清朝统治,结束两千多年君主专制,传播民主共和理念。
requirements.txt .env 1 2 3 # 下面的api_key去硅基流动官网申请 SILICONFLOW_API_KEY='sk-XXXXXXpdeijbbauaaawhgjexgwxarqpymzgocwvtXXXXXXXXX' BASE_URL='https://api.siliconflow.cn/v1'
main.py文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 import os import requests import json import chromadb from chromadb import PersistentClient PERSIST_DIR = "chroma_db" client = PersistentClient(path=PERSIST_DIR) collection = client.get_or_create_collection(name="documents" ) import dotenv dotenv.load_dotenv() SILICONFLOW_API_KEY = os.getenv('SILICONFLOW_API_KEY' ) EMBEDDING_MODEL = "BAAI/bge-large-zh-v1.5" SILICONFLOW_EMBED_URL = "https://api.siliconflow.cn/v1/embeddings" PERSIST_DIR = "chroma_db" client = PersistentClient(path=PERSIST_DIR) collection = client.get_or_create_collection(name="documents" ) def get_embedding_siliconflow (text: str , model: str = EMBEDDING_MODEL ): """ 调用硅基流动 API 生成一个 embedding 向量。 返回一个 list[float]。 """ headers = { "Authorization" : f"Bearer {SILICONFLOW_API_KEY} " , "Content-Type" : "application/json" } data = { "model" : model, "input" : text } resp = requests.post(SILICONFLOW_EMBED_URL, headers=headers, json=data) if resp.status_code != 200 : raise RuntimeError(f"Embedding 请求失败,状态码: {resp.status_code} , 内容: {resp.text} " ) resp_json = resp.json() embedding_vec = resp_json["data" ][0 ]["embedding" ] return embedding_vec def load_documents (doc_paths ): docs = [] for path in doc_paths: with open (path, "r" , encoding="utf-8" ) as f: text = f.read() source = os.path.basename(path) docs.append({"id" : path, "text" : text, "source" : source}) return docs def index_documents (documents, chunk_size=500 , overlap=50 ): for doc in documents: text = doc["text" ] chunks = [] i = 0 while i < len (text): chunk = text[i:i + chunk_size] chunks.append(chunk) i += chunk_size - overlap for idx, chunk in enumerate (chunks): embedding_vec = get_embedding_siliconflow(chunk) collection.add( documents=[chunk], metadatas=[{"source" : doc["source" ]}], ids=[f"{doc['id' ]} _chunk_{idx} " ], embeddings=[embedding_vec] ) def query_and_answer (question: str , top_k: int = 3 ): q_emb = get_embedding_siliconflow(question) results = collection.query( query_embeddings=[q_emb], n_results=top_k ) docs = results['documents' ][0 ] sources = [md["source" ] for md in results['metadatas' ][0 ]] prompt = "根据以下内容回答问题:\n\n" for d in docs: prompt += d + "\n\n" prompt += f"问题:{question} \n答案:" from openai import OpenAI client = OpenAI( api_key=os.getenv('SILICONFLOW_API_KEY' ), base_url=os.getenv('BASE_URL' ) ) resp = client.chat.completions.create( model="deepseek-ai/DeepSeek-V3" , messages=[ {"role" : "system" , "content" : "你是一个知识问答助手" }, {"role" : "user" , "content" : prompt} ], temperature=0 ) answer = resp.choices[0 ].message.content return answer docs = load_documents(["docs/biology.txt" , "docs/computer.txt" , "docs/history.txt" ]) index_documents(docs) question = "请描述计算机是如何通过硬件与软件协同工作的。" answer = query_and_answer(question) print ("问题:" , question) print ("答案:" , answer)
运行结果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 问题: 请描述计算机是如何通过硬件与软件协同工作的。 答案: 计算机通过硬件与软件协同工作,实现高效的数据处理和任务执行。具体协同过程如下: 1. **硬件提供基础支持** - **CPU**作为核心运算部件,执行软件指令(如数学计算、逻辑判断); - **内存**临时存储运行中的程序和数据,供CPU快速调用; - **存储设备**(如硬盘)长期保存系统软件、应用软件及用户文件; - 输入/输出设备(如键盘、显示器)实现人机交互。 2. **软件驱动硬件功能** - **系统软件**(如Windows)直接管理硬件资源: - 分配CPU任务、调度内存空间、控制外设操作; - 为应用软件提供运行环境(如调用打印机驱动)。 - **应用软件**(如Office)通过系统软件间接使用硬件: - 用户编辑文档时,软件将操作转化为CPU可执行的指令; - 数据经内存暂存后,由用户选择保存至硬盘。 3. **协同示例** 当运行视频会议软件(如钉钉): - 软件调用CPU处理视频编码、内存缓存实时数据; - 系统软件协调摄像头(输入)和扬声器(输出)硬件; - 网络模块通过网卡硬件传输数据,完成远程协作。 这种“硬件执行底层操作+软件调度资源与应用逻辑”的协作模式,使计算机能灵活适应从办公到人工智能的多样化需求。 进程已结束,退出代码为 0