
LangChain使用之Retrieval
Retrieval模块的设计意义
大模型的幻觉问题
拥有记忆后,确实扩展了AI工程的应用场景。
但是在专有领域,LLM无法学习到所有的专业知识细节,因此在 面向专业领域知识的提问时,无法给出 可靠准确的回答,甚至会“胡言乱语”,这种现象称之为 LLM的“幻觉”。
大模型生成内容的不可控,尤其是在金融和医疗领域等领域,一次金额评估的错误,一次医疗诊断的失误,哪怕只出现一次都是致命的。但,对于非专业人士来说可能难以辨识。目前还没有能够百分之百解决这种情况的方案。
当前大家普遍达成共识的一个方案:
首先,为大模型提供一定的上下文信息,让其输出会变得更稳定。
其次,利用本章的RAG,将检索出来的 文档和提示词输送给大模型,生成更可靠的答案。
RAG的优缺点
RAG的优点
- 相比提示词工程,RAG有 更丰富的上下文和数据样本,可以不需要用户提供过多的背景描述,就能生 成比较符合用户预期的答案。
- 相比于模型微调,RAG可以提升问答内容的 时效性和 可靠性
- 在一定程度上保护了业务数据的 隐私性。
RAG的缺点
- 由于每次问答都涉及外部系统数据检索,因此RAG的 响应时延相对较高。
- 引用的外部知识数据会 消耗大量的模型Token 资源。
Retrieval流程
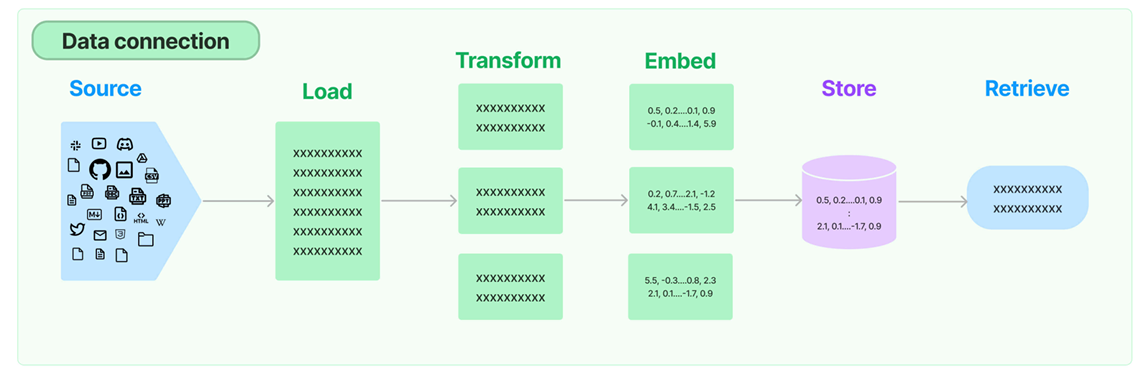
环节1:Source(数据源)
指的是RAG架构中所外挂的知识库。这里有三点说明:
- 原始数据源类型多样:如:视频、图片、文本、代码、文档等
- 形式的多样性:
- 可以是上百个.csv文件,可以是上千个.json文件,也可以是上万个.pdf文件
- 可以是某一个业务流程外放的API,可以是某个网站的实时数据等
环节2:Load(加载)
文档加载器(Document Loaders)负责将来自不同数据源的非结构化文本,加载到 内存成为(Document)对象 。
文档对象包含 文档内容和相关元数据信息 ,例如TXT、CSV、HTML、JSON、Markdown、PDF,甚至 YouTube 视频转录等。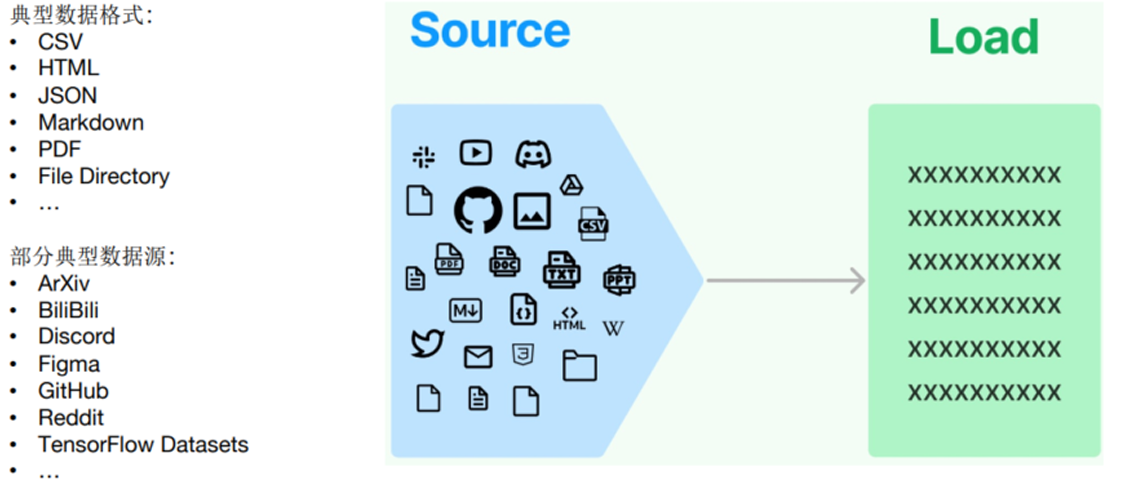
文档加载器还支持“ 延迟加载”模式,以缓解处理大文件时的内存压力。
文档加载器的编程接口使用起来非常简单,以下给出加载TXT格式文档的例子。
1 | from langchain.document_loadersimport TextLoader |
环节3:Transform(转换)
文档转换器(Document Transformers) 负责对加载的文档进行转换和处理,以便更好地适应下游任务的 需求。
文档转换器提供了一致的接口(工具)来操作文档,主要包括以下几类:
- 文本拆分器(Text Splitters) :将长文本拆分成语义上相关的小块,以适应语言模型的上下文窗口限 制。
- 冗余过滤器(Redundancy Filters) :识别并过滤重复的文档。
- 元数据提取器(Metadata Extractors) :从文档中提取标题、语调等结构化元数据。
- 多语言转换器(Multi-lingual Transformers) :实现文档的机器翻译。
- 对话转换器(Conversational Transformers) :将非结构化对话转换为问答格式的文档。
总的来说,文档转换器是 LangChain 处理管道中非常重要的一个组件,它丰富了框架对文档的表示和 操作能力。
环节3.1:Text Splitting(文档拆分)
- 向量化并存入数据库中。 拆分/分块的必要性:前一个环节加载后的文档对象可以直接传入文档拆分器进行拆分,而文档切块 后才能
- 文档拆分器的多样性:LangChain提供了丰富的文档拆分器,不仅能够切分普通文本,还能切分 Markdown、JSON、HTML、代码等特殊格式的文本。
- 拆分/分块的挑战性:实际拆分操作中需要处理许多细节问题, 需要采用不同的分块策略。
- 可以按照 数据类型进行切片处理,比如针对 不同类型的文本、 不同的使用场景都 文本类数据,可以直接按照字符、段落进行切 片;代 码类数据则需要进一步细分以保证代码的功能性;
- 可以直接根据 token 进行切片处理
在构建RAG应用程序的整个流程中,拆分/分块是最具挑战性的环节之一,它显著影响检索效果。目前 还没有通用的方法可以明确指出哪一种分块策略最为有效。不同的使用场景和数据类型都会影响分块策 略的选择。
环节4:Embed(嵌入)
文档嵌入模型(Text Embedding Models)负责将 文本转换为 向量表示,即模型赋予了文本计算机可 理解的数值表示,使文本可用于向量空间中的各种运算,大大拓展了文本分析的可能性,是自然语言处 理领域非常重要的技术。
举例:
- 实现原理:通过 特定算法(如Word2Vec)将语义信息编码为固定维度的向量,具体算法细节需后 续深入。
- 关键特性:相似的词在向量空间中距离相近,例如”猫”和”犬”的向量夹角小于”猫”和”汽车”。
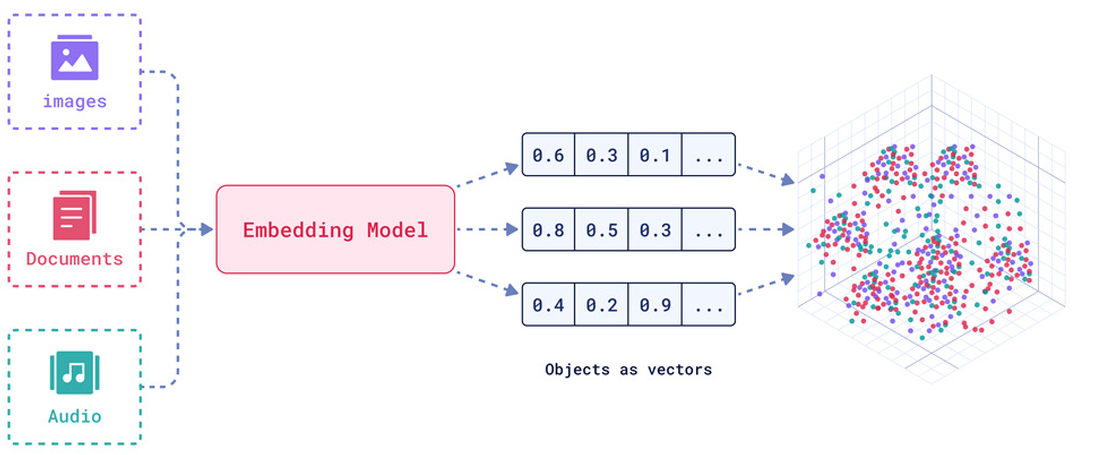
文本嵌入为 LangChain 中的问答、检索、推荐等功能提供了重要支持。具体为:
- 语义匹配:通过计算两个文本的向量余弦相似度,判断它们在语义上的相似程度,实现语义匹配。
- 文本检索:通过计算不同文本之间的向量相似度,可以实现语义搜索,找到向量空间中最相似的文 本。
- 信息推荐:根据用户的历史记录或兴趣嵌入生成用户向量,计算不同信息的向量与用户向量的相似 度,推荐相似的信息。
- 知识挖掘:可以通过聚类、降维等手段分析文本向量的分布,发现文本之间的潜在关联,挖掘知 识。
- 自然语言处理:将词语、句子等表示为稠密向量,为神经网络等下游任务提供输入。
环节5:Store(存储)
LangChain 还支持把文本嵌入存储到向量存储或临时缓存,以避免需要重新计算它们。这里就出现了数 据库,支持这些嵌入的高效 存储和搜索的需求。
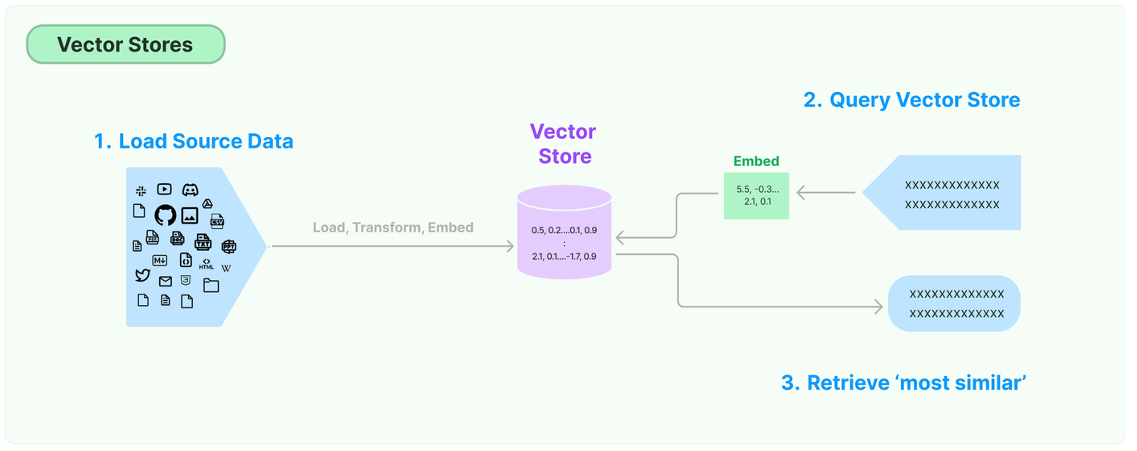
环节6:Retrieve(检索)
检索器(Retrievers)是一种用于 响应非结构化查询的接口,它可以返回符合查询要求的文档。
LangChain 提供了一些常用的检索器,如 向量检索器、 文档检索器、 网站研究检索器等。
通过配置不同的检索器,LangChain 可以灵活地平衡检索的精度、召回率与效率。检索结果将为后续的 问答生成提供信息支持,以产生更加准确和完整的回答。
文档加载器 Document Loaders
LangChain的设计:对于Source中多种不同的数据源,我们可以用一种统一的形式读取、调用。
加载txt
1 | from langchain_community.document_loaders import TextLoader, PyPDFLoader |
结果:
1 | [Document(metadata={'source': './asset/load/01-langchain-utf-8.txt'}, page_content='LangChain 是一个用于构建基于大语言模型(LLM)应用的开发框架,旨在帮助开发者更高效地集成、管理和增强大语言模型的能力,构建端到端的应用程序。它提供了一套模块化工具和接口,支持从简单的文本生成到复杂的多步骤推理任务')] |
Documment对象中有两个重要的属性:
- page_content:真正的文档内容
- metadata:文档内容的原数据
1 | # 显示Document对象的元数据 |
结果:
加载pdf
举例1:
LangChain加载PDF文件使用的是pypdf,先安装
1 | pip install pypdf |
1 | # 1.导入相关的依赖 PyPDFLoader() |
结果:
1 | [Document(metadata={'producer': 'Microsoft® Word 2019', 'creator': 'Microsoft® Word 2019', 'creationdate': '2025-06-20T17:18:19+08:00', 'moddate': '2025-06-20T17:18:19+08:00', 'source': './asset/load/02-load.pdf', 'total_pages': 1, 'page': 0, 'page_label': '1'}, page_content='"他的车,他的命! 他忽然想起来,一年,二年,至少有三四年;一滴汗,两滴汗,不\n知道多少万滴汗,才挣出那辆车。从风里雨里的咬牙,从饭里茶里的自苦,才赚出那辆车。\n那辆车是他的一切挣扎与困苦的总结果与报酬,像身经百战的武士的一颗徽章。……他老想\n着远远的一辆车,可以使他自由,独立,像自己的手脚的那么一辆车。" \n \n"他吃,他喝,他嫖,他赌,他懒,他狡猾, 因为他没了心,他的心被人家摘了去。他\n只剩下那个高大的肉架子,等着溃烂,预备着到乱死岗子去。……体面的、要强的、好梦想\n的、利己的、个人的、健壮的、伟大的祥子,不知陪着人家送了多少回殡;不知道何时何地\n会埋起他自己来, 埋起这堕落的、 自私的、 不幸的、 社会病胎里的产儿, 个人主义的末路鬼!\n"')] |
同样的:
1 | type (pages[0]) #langchain_core.documents.base.Document |
举例2:
1 | from langchain_community.document_loaders.pdf import PyPDFLoader |
1 | 8 |
举例3:使用load_and_split()
1 | # 1.导入相关的依赖 PyPDFLoader() |
同样,对于 PyPDFLoader ,依然是使用 .page_content 和 .metadata 去访问数据,也就是说,每一个 文档加载器虽然代码逻辑不同,应用需求不同,但使用方式是相同的。
加载CSV
举例1:加载csv所有列
1 | from langchain_community.document_loaders import CSVLoader |
结果:
1 | 4 |
举例2:加载指定列
使用 source_column 参数指定文件加载的列,保存在source变量中。
1 | from langchain_community.document_loaders import CSVLoader |
结果:
1 | [Document(metadata={source: John Doe, row: 0}, page_content=id: 1\ntitle: Introduction to Python\ncontent: Python is a popular programming language.\nauthor: John Doe), Document(metadata={source: Jane Smith, row: 1}, page_content=id: 2\ntitle: Data Science Basics\ncontent: Data science involves statistics and machine learning.\nauthor: Jane Smith), Document(metadata={source: Mike Johnson, row: 2}, page_content=id: 3\ntitle: Web Development\ncontent: HTML, CSS and JavaScript are core web technologies.\nauthor: Mike Johnson), Document(metadata={source: Sarah Williams, row: 3}, page_content=id: 4\ntitle: Artificial Intelligence\ncontent: AI is transforming many industries.\nauthor: Sarah Williams)] |
加载JSON
LangChain提供的JSON格式的文档加载器是JSONLoader。在实际应用场景中,JSON格式的数据占有 很大比例,而且JSON的形式也是多样的。我们需要特别关注。
JSONLoader 使用指定的 jq结构来解析 JSON 文件。jq是一个轻量级的命令行 JSON 处理器 ,可以对 JSON 格式的数据进行各种复杂的处理,包括数据过滤、映射、减少和转换,是处理 JSON 数据的首选 工具之一。
1 | pip install jq |
举例1:使用JSONLoader文档加载器加载
1 | from langchain_community.document_loaders import JSONLoader |
1 | [Document(metadata={'source': 'E:\\myjupyte\\尚硅谷LangChain\\chapter07-RAG\\asset\\load\\04-load.json', 'seq_num': 1}, page_content='{"messages": [{"sender": "Alice", "content": "Hello, how are you today?", "timestamp": "2023-05-15T10:00:00"}, {"sender": "Bob", "content": "I\'m doing well, thanks for asking!", "timestamp": "2023-05-15T10:02:00"}, {"sender": "Alice", "content": "Would you like to meet for lunch?", "timestamp": "2023-05-15T10:05:00"}, {"sender": "Bob", "content": "Sure, that sounds great!", "timestamp": "2023-05-15T10:07:00"}], "conversation_id": "conv_12345", "participants": ["Alice", "Bob"]}')] |
举例2:加载json文件中messages[]中的所有的content字段
1 | from langchain_community.document_loaders import JSONLoader |
结果:
1 | Hello, how are you today? |
举例3:提取04-response.json文件中嵌套在 data.items[].content 的文本
1 | from langchain_community.document_loaders import JSONLoader |
结果:
1 | This article explains how to parse API responses... |
举例4:提取04-response.json文件中嵌套在 data.items[] 里的 title、content 和 其文本
1 | # 1.导入相关依赖 |
结果:
1 | Understanding JSONLoader |
加载HTML(了解)
1 | pip install unstructured |
举例:
1 | # 1.导入相关的依赖 |
结果:
1 | 16 |
加载Markdown(了解)
1 | pip install markdown |
举例1:使用MarkDownLoader加载md文件
1 | # 1.导入相关的依赖 |
结果:
1 | 1 |
举例2:精细分割文档,保留结构信息
将Markdown文档按语义元素(标题、段落、列表、表格等)拆分成多个独立的小文档(Element对 象),而不是返回单个大文档。通过指定mode=”elements”轻松保持这种分离。
每个分割后的元素会包含元数据。
1 | # 1.导入相关的依赖 |
结果:
1 | 19 |
加载File Directory(了解)
除了上述的单个文件加载,我们也可以批量加载一个文件夹内的所有文件。
1 | pip install unstructured |
举例:
1 | # 1.导入相关的依赖 |
结果:
1 | 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 227.64it/s] |
文档拆分器 Text Splitters
为什么要拆分/分块/切分
当拿到统一的一个Document对象后,接下来需要切分成Chunks。如果不切分,而是考虑作为一个整体 的Document对象,会存在两点问题:
- 假设提问的Query的答案出现在某一个Document对象中,那么将检索到的整个Document对象 直接放入Prompt中并不是最优的选择,因为其中一定会包含非常多无关的信息,而无效信息越 多,对大模型后续的推理影响越大。
- 任何一个大模型都存在最大输入的Token限制,如果一个Document非常大,比如一个几百兆的 PDF,那么大模型肯定无法容纳如此多的信息。
基于此,一个有效的解决方案就是将完整的Document对象进行分块处理(Chunking)。无论是在存储 还是检索过程中,都将以这些块(chunks) 为基本单位,这样有效地避免内容不相关性问题和超出最大输 入限制的问题。
Chunking拆分的策略
方法1:根据句子切分:这种方法按照自然句子边界进行切分,以保持语义完整性。
方法2:按照固定字符数来切分:这种策略根据特定的字符数量来划分文本,但可能会在不适当的位置 切断句子。
方法3:按固定字符数来切分,结合重叠窗口(overlapping windows):此方法与按字符数切分相 似,但通过重叠窗口技术避免切分关键内容,确保信息连贯性。
方法4:递归字符切分方法:通过递归字符方式动态确定切分点,这种方法可以根据文档的复杂性和内 容密度来调整块的大小。
方法5:根据语义内容切分:这种 高级策略依据文本的语义内容来划分块,旨在保持相关信息的集中和 完整,适用于需要高度语义保持的应用场景。
[!tip]
第2种⽅法(按照字符数切分)和第3种⽅法(按固定字符数切分结合重叠窗口)主要基于字符进⾏ ⽂本的切分,而不考虑⽂章的实际内容和语义。这种⽅式虽简单,但可能会导致 主题或语义上的断 裂 。相对而⾔,第4种递归⽅法更加灵活和⾼效,它结合了固定⻓度切分和语义分析。通常是 首选策 略 ,因为它能够更好地确保每个段落包含⼀个完整的主题。
而第5种⽅法,基于语义的分割虽然能精确地切分出完整的主题段落,但这种⽅法效率较低。它需 要运⾏复杂的分段算法(segmentation algorithm), 处理速度较慢 ,并且 段落长度可能极不均 匀 (有的主题段落可能很⻓,而有的则较短)。因此,尽管它在某些需要⾼精度语义保持的场景 下有其应⽤价值,但并 不适合所有情况 。
这些方法各有优势和局限,选择适当的分块策略取决于具体的应用需求和预期的检索效果。接下来我们 依次尝试用常规手段应该如何实现上述几种方法的文本切分
具体实现
LangChain提供了许多不同类型的文档切分器
官网地址:https://python.langchain.com/api_reference/text_splitters/index.html
使用细节:
① TextSplitter作为各种具体的文档拆分器的父类
② 内部定义了一些常用的属性:
chunk_size: 返回块的最大尺寸,单位是字符数。默认值为4000(由长度函数测量)
chunk_overlap: 相邻两个块之间的字符重叠数,避免信息在边界处被切断而丢失。默认值为200,通常会设置为chunk_size的10% - 20%。
length_function: 用于测量给定块字符数的函数。默认赋值为len函数。len函数在Python中按Unicode字符计数,所以一个汉字、一个英文字母、一个符号都算一个字符。
keep_separator: 是否在块中保留分隔符,默认值为False
add_start_index: 如果为 True,则在元数据中包含块的起始索引。默认值为False
strip_whitespace: 如果为 True,则从每个文档的开始和结束处去除空白字符。默认值为True
② 内部定义的常用的方法:
情况1:按照字符串进行拆分:
split_text(xxx) : 传入的参数类型:字符串 ; 返回值的类型:List[str]
create_documents(xxx) : 传入的参数类型:List[str] ; 返回值的类型:List[Document]。底层调用了split_text(xxx)
情况2:按照Document对象进行拆分:
split_documents(xxx) : 传入的参数类型:List[Document] ; 返回值的类型:List[Document]。底层调用了create_documents(xxx)
2、Document对象 与 Str 是什么关系?
文档切分器可以按照字符进行切分,也可以按照Document进行切分。其中,Str 可以理解为是Document对象的page_content属性。
CharacterTextSplitter:Split by character
参数情况说明:
- chunk_size :每个切块的最大token数量,默认值为4000。
- chunk_overlap :相邻两个切块之间的最大重叠token数量,默认值为200。
- separator :分割使用的分隔符,默认值为”\n\n”。
- length_function :用于计算切块长度的方法。默认赋值为父类TextSplitter的len函数。
举例1:字符串文本的分割
1 | # 1.导入相关依赖 |
结果:
1 | 块 1:长度:50 |
说明:若必须禁用分隔符(如处理无空格文本),需容忍实际块长略小于 chunk_size (尤其对中文)
举例2:指定分割符
1 | # 1.导入相关依赖 |
结果:
1 | Created a chunk of size 33, which is longer than the specified 30 |
注意:无重叠。
separator优先原则:当设置了 separator (如”。”),分割器会首先尝试在分隔符处分割,然后再考 虑 chunk_size。这是为了避免在句子中间硬性切断。这种设计是为了:
- 优先保持语义完整性(不切断句子)
- 避免产生无意义的碎片(如半个单词/不完整句子)
- 如果 chunk_size 比片段小,无法拆分片段,导致 overlap失效。
- chunk_overlap仅在合并后的片段之间生效(如果 chunk_size 足够大)。如果没有合并的片 段,则 overlap失效。见举例3。
举例3:指定分割符
注意:有重叠。此时,文本“这是第二段内容。”的token正好就是8。
1 | # 1.导入相关依赖 |
结果:
1 | 块 1:长度:15 |
RecursiveCharacterTextSplitter:最常用
文档切分器中较常用的是 RecursiveCharacterTextSplitter (递归字符文本切分器) ,遇特定字符时进行分割。默认情况下,它尝试进行切割的字符包括[“\n\n”, “\n”, “ “, “”] 。
具体为:根据第一个字符进行切块,但如果任何切块太大,则会继续移动到下一个字符继续切块,以此 类推。
此外,还可以考虑添加,。等分割字符。
特点:
- 保留上下文:优先在自然语言边界(如段落、句子结尾)处分割, 减少信息碎片化。
- 智能分段:通过递归尝试多种分隔符,将文本分割为大小接近chunk_size的片段。
- 灵活适配:适用于多种文本类型(代码、Markdown、普通文本等),是LangChain中最通用的 文本拆分器。
此外,还可以指定的参数包括:
- chunk_size:同TextSplitter(父类) 。
- chunk_overlap:同TextSplitter(父类) 。
- length_function:同TextSplitter(父类) 。
- add_start_index:同TextSplitter(父类) 。
举例1:使用split_text()方法演示
1 | # 1.导入相关依赖 |
结果:
1 | LangChain框 |
举例2:使用create_documents()方法演示,传入字符串列表,返回Document对象列表
1 | # 1.导入相关依赖 |
结果:
1 | page_content='LangChain框' metadata={'start_index': 0} |
逐步分割过程
第一阶段:顶级分割(按\n\n)
- 首次分割:
1
2
3text.split( "\n\n" ) →
[ "LangChain框架特性" ,
"多模型集成(GPT/Claude)\n记忆管理功能\n链式调用设计。文档分析场景示例:需要处理 PDF/Word等格式。" ]
- 第一部分长度:13字符 > 10 → 需要继续分割
- 第二部分长度:79字符 > 10 → 需要继续分割
第二阶段:递归分割第一部分 “LangChain框架特性”
- 尝试 \n :无匹配
- 尝试(空格):
- 检查字符串: “LangChain框架特性” (无空格)
- 回退到””(字符级分割):
1
2list ( "LangChain框架特性" ) →
[ 'L' , 'a' , 'n' , 'g' , 'C' , 'h' , 'a' , 'i' , 'n' , '框' , '架' , '特' , '性' ]- 前10字符: “LangChain框”
- 剩余部分: “架特性”
第三阶段:递归分割第二部分(长段落)
- 按 \n 分割:
1
2
3
4
5"多模型集成(GPT/Claude)\n记忆管理功能\n链式调用设计。文档..." .split( "\n" ) →
[ "多模型集成(GPT/Claude)" , # 17字符
"记忆管理功能" , # 6字符
"链式调用设计。文档分析场景示例:需要处理PDF/Word等格式。" # 36字符
]
- 第1块:17字符 > 10 → 继续分割
- 第2块:6字符 ≤ 10 → 直接保留
- 第3块:36字符 > 10 → 继续分割
- 分割 “多模型集成(GPT/Claude)” :
- 尝试:无空格
- 回退到””:
- 前10字符: “多模型集成(GPT”
- 剩余7字符: “/Claude)”
- 分割 “链式调用设计。文档分析场景示例:需要处理PDF/Word等格式。”:
- 尝试:无空格
- 回退到””:
- 按10字符分段:
1
2
3
4
5
6
7"链式调用设计。文档分析场景示例:需要处理PDF/Word等格式。" →
[
"链式调用设计。文档" ,
"分析场景示例:需要处" ,
"理PDF/Word等" ,
"格式。"
]
- 按10字符分段:
举例3:使用create_documents()方法演示,将本地文件内容加载成字符串,进行拆分
1 | # 1.导入相关依赖 |
结果:
1 | <class 'str'> |
举例4:使用split_documents()方法演示,利用PDFLoader加载文档,对文档的内容用递归切割器切割
1 | # 1.导入相关依赖 |
结果:
1 | "他的车,他的命! 他忽然想起来,一年,二年,至少有三四年;一滴汗,两滴汗,不 |
举例5:自定义分隔符
有些书写系统没有单词边界,例如中文、日文和泰文。使用默认分隔符列表[“\n\n”, “\n”, “ “, “”]分割文 本可能导致单词错误的分割。为了保持单词在一起,你可以自定义分割字符,覆盖分隔符列表以包含额 外的标点符号。
1 | text_splitter = RecursiveCharacterTextSplitter( chunk_size=200, chunk_overlap=20, # 增加重叠字符 |
TokenTextSplitter/CharacterTextSplitter:Split by tokens
当我们将文本拆分为块时,除了字符以外,还可以: 按Token的数量分割 (而非字符或单词数),将长 文本切分成多个小块。
什么是Token?
- 对模型而言,Token是文本的最小处理单位。例如:
- 英文: “hello” → 1个Token,
- 中文: “ChatGPT” → 2个Token( “Chat” + “GPT” )。 “人工智能” → 可能拆分为2-3个Token(取决于分词器)。
为什么按Token分割?
- 语言模型对输入长度的限制是基于Token数(如GPT-4的8k/32k Token上限),直接按字符或单 词分割可能导致实际Token数超限。(确保每个文本块不超过模型的Token上限)
- 大语言模型(LLM)通常是以token的数量作为其计量(或收费)的依据,所以采用token分割也有助于 我们在使用时更方便的控制成本。
TokenTextSplitter 使用说明:
- 核心依据:Token数量 + 自然边界。(TokenTextSplitter 严格按照 token 数量进行分割,但同时 会优先在自然边界(如句尾)处切断,以尽量保证语义的完整性。)
- 优点:与LLM的Token计数逻辑一致,能尽量保持语义完整
- 缺点:对非英语或特定领域文本,Token化效果可能不佳
- 典型场景:需要精确控制Token数输入LLM的场景
举例1:使用TokenTextSplitter
1 | # 1.导入相关依赖 |
结果:
1 | 原始文本被分割成了 3 个块: |
为什么会出现这样的分割?
1、第一块 (29字符) :内容是一个完整的句子,以句号结尾。TokenTextSplitter识别到这是一个自然的 语义边界,即使这里的 token 数量可能尚未达到 33,它也选择在此处切割,以保证第一块语义的完整 性。
2、第二块 (32字符) :内容包含了另一个完整句子 “人工智能是指…一门科学。”以及下一句的开头 20世纪50” 。分割器在处理完第一个句子的 token 后,可能 token 数量已经接近 “自 chunk_size ,于是 在下一个自然边界(这里是句号)之后继续读取了少量 token(“自20世纪50”),直到非常接近 33 token 的限制。
注意:“50” 之后被切断,是因为编码器很可能将“50”识别为一个独立的 token,而“年代”是另 一个 token。为了保证 token 的完整性,它不会在“50”字符中间切断。
3、第三块 (19字符) :是第二块中断内容的剩余部分,形成了一个较短的块。这是因为剩余内容本身的 token 数量就较少。
特别注意:字符长度不等于 Token 数量。
举例2:使用CharacterTextSplitter
1 | # 1.导入相关依赖 |
结果:
1 | 分割后的块数: 4 |
SemanticChunker:语义分块
SemanticChunking(语义分块)是 LangChain 中一种更高级的文本分割方法,它超越了传统的基于字 符或固定大小的分块方式,而是根据文本的语义结构进行智能分块,使每个分块保持语义完整性,从而 提高检索增强生成(RAG)等应用的效果。
语义分割 vs 传统分割
| 特性 | 语义分割(SemanticChunker) | 传统字符分割(RecursiveCharacter) |
|---|---|---|
| 分割依据 | 嵌入向量相似度 | 固定字符/换行符 |
| 语义完整性 | ✅ 保持主题连贯 | ❌ 可能切断句子逻辑 |
| 计算成本 | ❌ 高(需嵌入模型) | ✅ 低 |
| 适用场景 | 需要高语义一致性的任务 | 简单文本预处理 |
举例:
1 | from langchain_experimental.text_splitter import SemanticChunker |
结果:
1 | 4 |
关于参数的说明:
- breakpoint_threshold_type (断点阈值类型)
- 作用:定义文本语义边界的检测算法,决定何时分割文本块。
- 可选值及原理:
| 类型 | 原理说明 | 适用场景 |
|---|---|---|
| percentile | 计算相邻句子嵌入向量的余弦距离,取距离分 布的第N百分位值作为阈值,高于此值则分割 | 常规文本(如文 章、报告) |
| standard_deviation | 以均值 + N倍标准差为阈值,识别语义突变 点 | 语义变化剧烈的 文档(如技术手 册) |
| interquartile | 用四分位距(IQR) 定义异常值边界,超过则 分割 | 长文档(如书 籍) |
| gradient | 基于嵌入向量变化的梯度检测分割点(需自定 义实现) | 实验性需求 |
- breakpoint_threshold_amount (断点阈值量)
- 作用:控制分割的粒度敏感度,值越小分割越细(块越多),值越大分割越粗(块越少)。 取值范围与示例:
- percentile 模式:0.0~100.0,用户代码设 65.0 表示仅当余弦距离 > 所有距离中最低的 65.0%值时分割 。默认值是:95.0,兼顾语义完整性与检索效率。值过小(比如0.1),会产 生大量小文本块,过度分割可能导致上下文断裂。
- standard_deviation 模式:浮点数(如 1.5 表示均值+1.5倍标准差)。
- interquartile 模式:倍数(如1.5 是IQR标准值)。
其它拆分器
类型1:HTMLHeaderTextSplitter:Split by HTML header
HTMLHeaderTextSplitter是一种专门用于处理HTML文档的文本分割方法,它根据HTML的标题标签(如<h1>,<h2>等) 将文档划分为逻辑分块,同时保留标题的层级结构信息。
举例:
1 | # 1.导入相关依赖 |
说明:
- 标题下文本内容所属标题的层级信息保存在元数据中。
- 每个分块会自动继承父级标题的上下文,避免信息割裂。
类型2:CodeTextSplitter:Split code
CodeTextSplitter是一个 专为代码文件设计的文本分割器(Text Splitter),支持代码的语言包括[‘cpp’, ‘go’, ‘java’, ‘js’, ‘php’, ‘proto’, ‘python’, ‘rst’, ‘ruby’, ‘rust’, ‘scala’, ‘swift’, ‘markdown’, ‘latex’, ‘html’, ‘sol’]。它能够根据编程语言的语法结构(如函数、类、代码块等)智能地拆分代码,保持代码逻辑的完 整性。
与递归文本分割器(如RecursiveCharacterTextSplitter)不同,CodeTextSplitter 针对代码的特性进 行了优化, 避免在函数或类的中间截断。
举例1:支持的语言
1 | pip install langchain-text-splitters |
1 | from langchain.text_splitter ' |
1 | [cpp, go, java, kotlin, js, ts, php, proto, python, rst, ruby, rust, scala, swift, markdown, latex, html, sol, csharp, cobol, c, lua, perl, haskell, elixir, powershell] |
举例2:
1 | # 1.导入相关依赖 |
结果:
1 | [Document(metadata={}, page_content='def hello_world():\n print("Hello, World!")'), |
类型3:MarkdownTextSplitter:md数据类型
因为Markdown格式有特定的语法,一般整体内容由 h1、h2、h3 等多级标题组织,所以 MarkdownHeaderTextSplitter的切分策略就是根据 标题来分割文本内容。
1 | from langchain.text_splitter import MarkdownTextSplitter |
结果:
1 |
|
文档嵌入模型 Text Embedding Models
嵌入模型概述
Text Embedding Models:文档嵌入模型,提供将文本编码为向量的能力,即文档向量化 ,文档写入和用户 查询匹配前都会先执行文档嵌入编码,即向量化。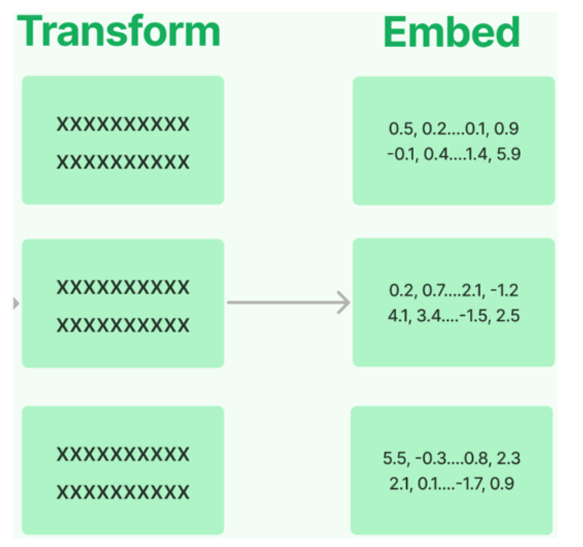
LangChain中针对向量化模型的封装提供了两种接口,一种针对文档的向量化(embed_documents),一 种针对句子的向量化embed_query。
句子的向量化(embed_query)
1 | from langchain_openai import OpenAIEmbeddings |
结果:
1 | 1024 |
文档的向量化(embed_documents)
文档的向量化,接收的参数是字符串数组。
举例1
1 | from langchain_openai import OpenAIEmbeddings |
结果:
1 | Hi there!:[-0.005018789321184158, -0.02362913265824318, -0.015080382116138935] |
举例2
1 | from dotenv import load_dotenv |
结果:
1 | 4 |
向量存储(Vector Stores)
理解向量存储
将文本向量化之后,下一步就是进行向量的存储。这部分包含两块:
- 向量的存储:将非结构化数据向量化后,完成存储
- 向量的查询:查询时,嵌入非结构化查询并检索与嵌入查询“最相似”的嵌入向量。即具有相似性 检索能力
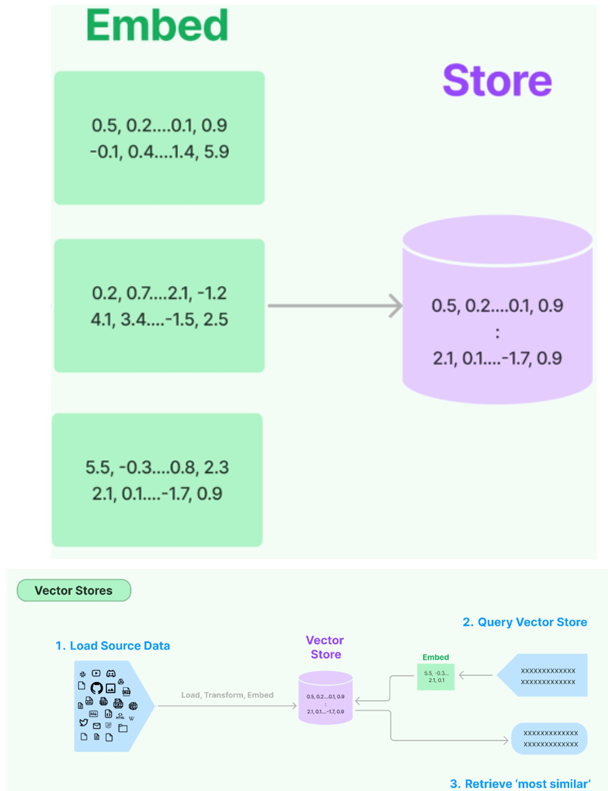
常用的向量数据库
LangChain提供了超过 50种 不同向量存储(Vector Stores)的集成,从开源的 本地向量存储到 云托管的私有向量存储,允许你选择最适合需求的向量存储。
LangChain支持的向量存储参考 VectorStore 接口和实现。
典型的介绍如下:
| 向量数据库 | 描述 |
|---|---|
| Chroma | 开源、免费的嵌入式数据库 |
| FAISS | Meta出品,开源、免费,Facebook AI相似性搜索服务。(Facebook AI Similarity Search,Facebook AI 相似性搜索库) /fæs/ |
| Milvus | 用于存储、索引和管理由深度神经网络和其他ML模型产生的大量嵌入向量的数据库 |
| Pinecone | 具有广泛功能的向量数据库 |
| Redis | 基于Redis的检索器 |
代码实现
使用向量数据库组件时需要同时传入包含文本块的Document类对象以及文本向量化组件,向量数据库组 件会自动完成将文本向量化的工作,并写入数据库中。
数据的存储
举例1:从TXT文档中加载数据,向量化后存储到Chroma数据库
安装模块:
1 | pip install chromadb |
1 | from langchain_chroma import Chroma |
思考:此时数据存储在哪里呢?
注意:Chroma主要有两种存储模式:内存模式和持久化模式。当使用persist_directory参数时,数据 会保存到指定目录;如果没有指定,则默认使用内存存储。
1 | db1 = Chroma.from_documents( |
2、需要明确,在向量数据库中,不仅存储了数据(或文档)的向量,而且还存储了数据(或文档)本身。
演示一下:检索的需求
1 | query = "人工智能的核心技术有哪些呢?" |
结果:
1 | 5. 人工智能的挑战与机遇 |
举例2:操作csv文档,并向量化
1 | from langchain.text_splitter import CharacterTextSplitter |
数据的检索
举例:一个包含构建Chroma向量数据库以及向量检索的代码
前置代码:
1 | # 1.导入相关依赖 |
① 相似性检索(similarity_search)
1 | # 5. 检索示例(返回前3个最相关结果) |
结果:
1 | 查询: '哺乳动物' 的结果: |
② 支持直接对问题向量查询(similarity_search_by_vector)
1 | query = "哺乳动物" |
结果:
1 | 查询: '哺乳动物' 的结果: |
③ 相似性检索,支持过滤元数据(filter)
1 | query = "哺乳动物" |
结果:
1 |
|
④ 通过L2距离分数进行搜索(similarity_search_with_score)
说明:分数值越小,检索到的文档越和问题相似。分值取值范围:[0,正无穷]
1 | docs = db.similarity_search_with_score( |
结果:
1 | [L2距离得分=1.055] 狗是人类最早驯化的动物之一,属于犬科。它们具有高度社会性,能理解人类情绪,常被用作宠物、导盲犬或警犬。不同品种的狗在体型、毛色和性格上有很大差异。 [{'source': '动物', 'type': '哺乳动物'}] |
⑤ 通过余弦相似度分数进行搜索(_similarity_search_with_relevance_scores)
说明:分数值越接近1(上限),检索到的文档越和问题相似。
1 | docs = db._similarity_search_with_relevance_scores( |
结果:
1 | * [余弦相似度得分=0.254] 狗是人类最早驯化的动物之一,属于犬科。它们具有高度社会性,能理解人类情绪,常被用作宠物、导盲犬或警犬。不同品种的狗在体型、毛色和性格上有很大差异。 [{'type': '哺乳动物', 'source': '动物'}] |
⑥ MMR(最大边际相关性,max_marginal_relevance_search)
MMR 是一种平衡相关性 和多样性的检索策略,避免返回高度相似的冗余结果。
参数说明: lambda_mult 参数值介于 0 到 1 之间,用于确定结果之间的多样性程度,其中 0 对应最大 多样性,1 对应最小多样性。默认值为 0.5。
1 | docs = db.max_marginal_relevance_search( |
结果:
1 | 🔍 关于【量子力学是什么】的搜索结果: |
检索器(召回器) Retrievers
从“向量存储组件”的代码实现5.4.2中可以看到,向量数据库本身已经包含了实现召回功能的函数方法 (similarity_search )。该函数通过计算原始查询向量与数据库中存储向量之间的相似度来实现召回。
LangChain还提供了 更加复杂的召回策略,这些策略被集成在Retrievers(检索器或召回器)组件中。
Retrievers(检索器)是一种用于从大量文档中检索与给定查询相关的文档或信息片段的工具。检索器 不需要存储文档,只需要 返回(或检索)文档即可。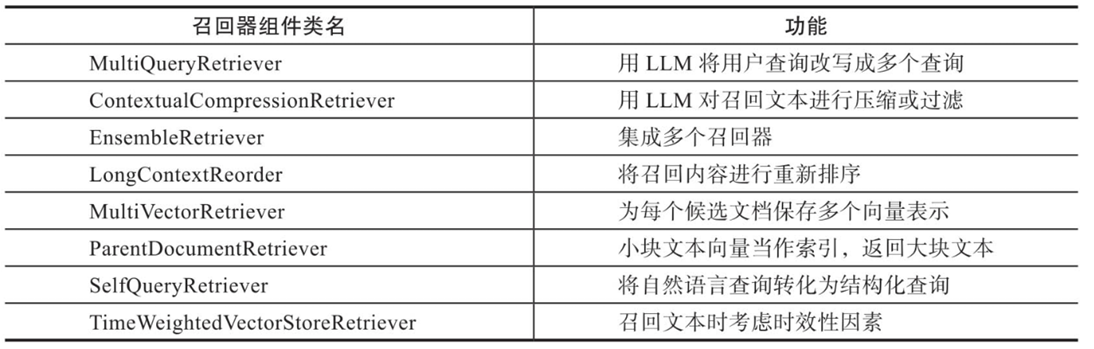
Retrievers 的执行步骤:
- 步骤1:将输入查询转换为向量表示。
- 步骤2:在向量存储中搜索与查询向量最相似的文档向量(通常使用余弦相似度或欧几里得距离等度量方 法)。
- 步骤3:返回与查询最相关的文档或文本片段,以及它们的相似度得分。
代码实现
Retriever 一般和 VectorStore 配套实现,通过as_retriever() 方法获取。
举例:
1 | # 1.导入相关依赖 |
结果:
1 | 3 |
使用相关检索策
1 | pip install faiss-cpu |
前置代码:
1 | # 1.导入相关依赖 |
① 默认检索器使用相似性搜索
1 | # 获取检索器 |
结果:
1 | 结果 1: |
② 分数阈值查询
只有相似度超过这个值才会召回
1 | retriever = db.as_retriever( |
结果:
1 | 📌 内容: 社会正义:承诺解决系统性种族歧视问题。 |
注意只会返回满足阈值分数的文档,不会获取文档的得分。如果想查询文档的得分是否满足阈值,可以 使用向量数据库的 similarity_search_with_relevance_scores 查看
1 | docs_with_scores = db.similarity_search_with_relevance_scores("经济政策") |
结果:
1 |
|
③ MMR搜索
1 | retriever = db.as_retriever( |
结果:
1 | 2 |
结合大模型的使用
举例1:通过FAISS构建一个可搜索的向量索引数据库,并结合RAG技术让LLM去回答问题。
情况1:不用RAG给LLM灌输上下文数据
1 | from langchain_openai import ChatOpenAI |
结果:
1 | 北京作为中国的首都,拥有丰富的历史和现代建筑,以下是一些著名的代表: |
情况2:使用RAG给LLM灌输上下文数据
1 | # 1. 导入所有需要的包 |
结果:
1 | 回答: 根据提供的文本内容,北京有以下著名建筑: |
举例2:使用Chroma数据库 (与举例1类似)
阶段1:文档的切分
1 | ## 1. 文档加载 |
结果:
1 | 13 |
阶段2:向量存储与检索
1 | from langchain_openai import OpenAIEmbeddings |
结果:
1 |
|
阶段3
1 | from langchain_openai import ChatOpenAI |
结果:
1 | 根据已知信息,"Chat Models"(聊天模型)是LangChain中的一个组件,它们以**消息**(Messages)作为输入和输出。每条消息包含内容(content)和角色(role),角色用于描述消息的来源(例如用户、系统等)。 |
聊天模型(Chat Models)是新型的语言模型,它接收消息并输出消息。请查看特定提供者的支持集成以 了解如何开始使用聊天模型。




