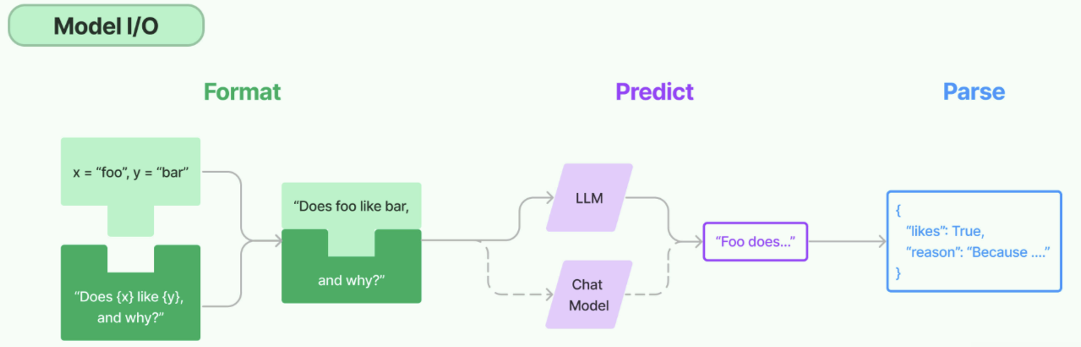
Model I/O介绍 Model I/O 模块是与语言模型(LLMs)进行交互的 核心组件 ,在整个框架中有着很重要的地位。Prompt Template , Model 和 Output Parser
==简单来说,就是输⼊、模型处理、输出这三个步骤。==
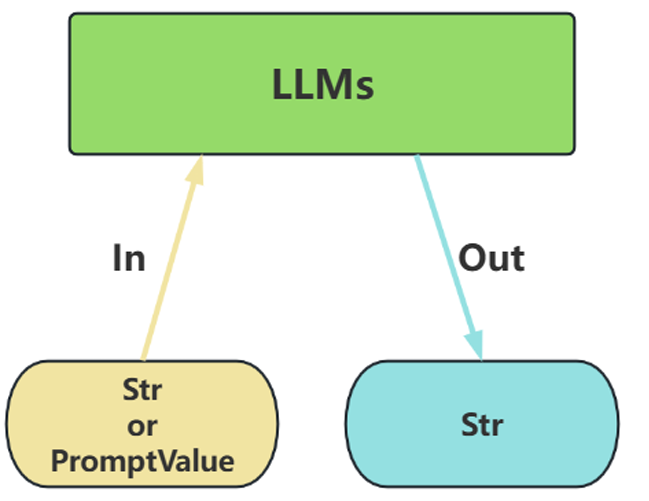
Model I/O之调用模型1 类型1:LLMs(非对话模型) LLMs,也叫Text Model、非对话模型,是许多语言模型应用程序的支柱。主要特点如下:
输入 :接受 文本字符串或 PromptValue 对象 输出 :总是返回 文本字符串
适用场景 :仅需单次文本生成任务(如摘要生成、翻译、代码生成、单次问答)或对接不支持消息 结构的旧模型(如部分本地部署模型)( 言外之意,优先推荐ChatModel )不支持多轮对话上下文 。每次调用独立处理输入,无法自动关联历史对话(需手动拼接历史文 本)。局限性 :无法处理角色分工或复杂对话逻辑。
.env文件
1 2 3 4 SILICONFLOW_API_KEY='sk-spyqlkfbgpdeijbbauaaawhgjexgwxarXXXXXXXXXXXXXXX' BASE_URL='https://api.siliconflow.cn/v1' OPENAI_MODEL_NAME='deepseek-ai/DeepSeek-V3' OPENAI_EMBEDDING_MODEL_NAME='Qwen/Qwen3-Embedding-0.6B'
举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import os import dotenv from langchain_openai import OpenAI dotenv.load_dotenv() os.environ["OPENAI_API_KEY" ] = os.getenv("SILICONFLOW_API_KEY" ) os.environ["OPENAI_BASE_URL" ] = os.getenv("BASE_URL" ) llm = OpenAI( model=os.getenv("OPENAI_MODEL_NAME" ), ) str = llm.invoke("写一首关于春天的诗" ) print (str ) print (type (str ))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 春⻛拂过⼤地 万物复苏欣欣向荣 花开满⼭⾕ ⻦⼉啁啾歌声飘 春⾬滋润⽥野 农夫欢呼收获丰 春⽇暖阳温柔 ⼈们⼼情也随之舒 春天来了 带来新的开始 带走冬⽇的寒冷 带来⽣机与希望 春天啊,美丽的季节 让我们⼀起欢庆 迎接春天的到来 让快乐永远驻留⼼中。
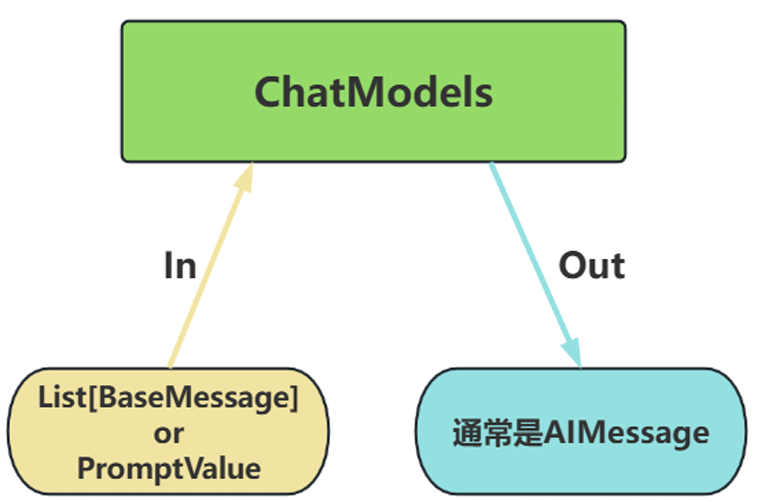
类型2:Chat Models(对话模型) ChatModels,也叫聊天模型、对话模型,底层使用LLMs。大语言模型调用,以 ChatModel 为主!
输入 :接收消息列表 List[BaseMessage] 或 PromptValue ,每条消息需指定角色(如 SystemMessage、HumanMessage、AIMessage) 输出 :总是返回带角色的 消息对象 ( BaseMessage 子类 ),通常是 AIMessage
原生支持多轮对话 。通过消息列表维护上下文(例如:[SystemMessage, HumanMessage, AIMessage, …]),模型可基于完整对话历史生成回复。 适用场景 :对话系统(如客服机器人、长期交互的AI助手)
举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain_openai import ChatOpenAI from langchain_core.messages import SystemMessage, HumanMessage import os import dotenv dotenv.load_dotenv() os.environ["OPENAI_API_KEY" ] = os.getenv("SILICONFLOW_API_KEY" ) os.environ["OPENAI_BASE_URL" ] = os.getenv("BASE_URL" ) chat_model = ChatOpenAI(model=os.getenv("OPENAI_MODEL_NAME" )) messages = [ SystemMessage(content="我是人工智能助手,我叫小智" ), HumanMessage(content="你好,我是小明,很高兴认识你" ) ] response = chat_model.invoke(messages) print (type (response)) print (response.content)
1 2 <class 'langchain_core.messages.ai.AIMessage' > 你好小明!😊我是小智,也超级高兴认识你!今天有什么想聊的话题,或者需要帮忙的地方吗?无论是解闷还是解决问题,我都在这里哦~
Embedding Model:也叫文本嵌入模型,这些模型将 文本作为输入并返回 Embedding。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import os import dotenv from langchain_openai import OpenAIEmbeddings dotenv.load_dotenv() os.environ["OPENAI_API_KEY" ] = os.getenv("SILICONFLOW_API_KEY" ) os.environ["OPENAI_BASE_URL" ] = os.getenv("BASE_URL" ) embeddings_model = OpenAIEmbeddings( model=os.getenv("OPENAI_EMBEDDING_MODEL_NAME" ), ) res1 = embeddings_model.embed_query('我是文档中的数据' ) print (res1)
角度2出发:参数位置不同举例 这里以 LangChain 的API为准,使用对话模型,进行测试。
模型调用的主要方法及参数 相关方法及属性:
OpenAI(…) / ChatOpenAI(…) :创建一个模型对象(非对话类/对话类) model.invoke(xxx) :执行调用,将用户输入发送给模型.content :提取模型返回的实际文本内容
必须设置的参数:
base_url :大模型 API 服务的根地址 api_key :用于身份验证的密钥,由大模型服务商(如 OpenAI、百度千帆)提供 model/model_name :指定要调用的具体大模型名称(如 gpt-4-turbo 、 ERNIE-3.5-8K 等)
其它参数:
temperature :温度,控制生成文本的“随机性”,取值范围为0~1。
值越低→ 输出越确定、保守(适合事实回答)
值越高→ 输出越多样、有创意(适合创意写作)
通常,根据需要设置如下:
精确模式(0.5或更低):生成的文本更加安全可靠,但可能缺乏创意和多样性。
平衡模式(通常是0.8):生成的文本通常既有一定的多样性,又能保持较好的连贯性和准确 性。
创意模式(通常是1):生成的文本更有创意,但也更容易出现语法错误或不合逻辑的内容。
max_tokens :限制生成文本的最大长度,防止输出过长。
Token是什么 ?基本单位 : 大模型处理文本的最小单位是token(相当于自然语言中的词或字),输出时逐个token 依次生成。收费依据 :大语言模型(LLM)通常也是以token的数量作为其计量(或收费)的依据。
1个Token≈1-1.8个汉字,1个Token≈3-4个英文字母
Token与字符转化的可视化工具:
max_tokens 设置建议:
客服短回复:128-256。比如:生成一句客服回复(如“订单已发货,预计明天送达”)
常规对话、多轮对话:512-1024
长内容生成:1024-4096。比如:生成一篇产品说明书(包含功能、使用方法等结构)
方式1:硬编码 直接将 API Key 和模型参数写入代码,仅适用于临时测试,存在密钥泄露风险,在 具体费用自 生产环境不推荐。
1 2 3 4 5 6 7 8 9 10 11 from langchain_openai import ChatOpenAI llm = ChatOpenAI( api_key= "sk-xxxxxxxxx" , base_url= "https://api.openai-proxy.org/v1" , model= "gpt-3.5-turbo" , ) response = llm.invoke( "解释神经网络原理" ) print (response.content)
1 神经⽹络是⼀种模拟⼈脑神经元之间信息传递的数学模型。神经⽹络由多层神经元组成,每个神经 元接收来⾃上⼀层神经元的输⼊信号,并通过激活函数将输⼊信号进⾏加权求和并输出⼀个结果。 在神经⽹络中,数据通过输⼊层传递到隐藏层,最终到输出层。在每⼀层中,神经元通过学习算法 不断调整连接权重,以使神经⽹络能够准确地对输⼊数据进⾏分类或预测。 神经⽹络的训练过程是通过反向传播算法进⾏的。该算法通过计算神经⽹络输出结果与实际结果之 间的误差,然后根据误差调整神经元之间的连接权重,以提⾼神经⽹络的准确性。 总的来说,神经⽹络通过模拟⼈脑神经元之间的信息传递过程,利⽤数学模型来实现对复杂问题的 学习和预测。神经⽹络的原理是基于神经元之间的连接权重调整和误差反向传播的机制。
方式2:配置环境变量 通过系统环境变量存储密钥,避免代码明文暴露。
方式1:终端设置环境变量(临时生效):
1 2 export OPENAI_API_KEY= "sk-xxxxxxxxxxxxxxxxxxxx" set OPENAI_API_KEY= "sk-xxxxxxxxxxxxxxxxxxxx"
方式3:使用.env配置文件 使用 python-dotenv 加载本地配置文件,支持多环境管理(开发/生产)。
安装依赖
1 2 3 pip install python-dotenv conda install python-dotenv
创建 .env 文件(项目根目录):
1 2 OPENAI_API_KEY= "sk-xxxxxxxxx" OPENAI_BASE_URL= "https://api.openai-proxy.org/v1"
举例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain_openai import ChatOpenAI import os import dotenv dotenv.load_dotenv() chat_model = ChatOpenAI( model_name=os.getenv('OPENAI_MODEL_NAME' ), base_url=os.getenv('BASE_URL' ), api_key=os.getenv('SILICONFLOW_API_KEY' ), ) response = chat_model.invoke("什么是langchain?" ) print (response)
1 2 content='LangChain 是一个用于开发与语言模型(如 GPT-3、GPT-4 等)互动的应用程序的框架。它提供了一系列工具和组件,帮助开发者轻松构建强大的自然语言处理(NLP)应用。LangChain 的功能包括:\n\n1. **链(Chains)**:可以将多个操作步骤链接在一起,例如将用户输入传递给语言模型,然后将模型的输出传递给其他处理步骤。\n\n2. **文档加载器(Document Loaders)**:用于从不同源(如 PDF、文本文件、网页等)加载和处理文档,使其能被语言模型处理。\n\n3. **内存(Memory)**:允许应用程序保持对话的上下文,使得模型能够记住之前的对话内容,从而提供更连贯的交互。\n\n4. **代理(Agents)**:根据需求动态选择最合适的工具和模型进行处理,提高了系统的灵活性和自适应能力。\n\n5. **工具(Tools)**:提供各种实用功能,如 API 调用、数据库查询等,增强了语言模型的能力。\n\nLangChain 的设计目标是降低构建复杂 NLP 应用的门槛,使得无论是普通开发者还是数据科学家都能够实现他们的想法。无论是开发聊天机器人、问答系统,还是其他基于语言模型的应用,LangChain 都提供了丰富的支持。' additional_kwargs={'refusal' : None} response_metadata={'token_usage' : {'completion_tokens' : 311, 'prompt_tokens' : 12, 'total_tokens' : 323, 'completion_tokens_details' : {'accepted_prediction_tokens' : 0, 'audio_tokens' : 0, 'reasoning_tokens' : 0, 'rejected_prediction_tokens' : 0}, 'prompt_tokens_details' : {'audio_tokens' : 0, 'cached_tokens' : 0}}, 'model_name' : 'gpt-4o-mini-2024-07-18' , 'system_fingerprint' : 'fp_efad92c60b' , 'id' : 'chatcmpl-C7KtQzBvG5gwJX9h550F2dmb9W3uQ' , 'service_tier' : None, 'finish_reason' : 'stop' , 'logprobs' : None} id ='run--3179f561-e4fe-420a-ad83-6b845b65600a-0' usage_metadata={'input_tokens' : 12, 'output_tokens' : 311, 'total_tokens' : 323, 'input_token_details' : {'audio' : 0, 'cache_read' : 0}, 'output_token_details' : {'audio' : 0, 'reasoning' : 0}}
方式2:给os内部的环境变量赋值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from langchain_openai import ChatOpenAI import os import dotenv dotenv.load_dotenv() os.environ["OPENAI_BASE_URL" ] = os.getenv("OPENAI_BASE_URL" ) os.environ["OPENAI_API_KEY" ] = os.getenv("OPENAI_API_KEY1" ) chat_model = ChatOpenAI( ) response = chat_model.invoke("什么是langchain?" ) print (response)
1 content='LangChain是一个基于区块链技术的语言服务平台,旨在提供全球透明、快速和安全的语言互译服务。用户可以在该平台上寻找翻译人员并进行语言交流,同时通过智能合约方式来确保交易的安全和可靠。LangChain旨在消除语言障碍,促进全球交流和合作。' additional_kwargs={'refusal' : None} response_metadata={'token_usage' : {'completion_tokens' : 116, 'prompt_tokens' : 14, 'total_tokens' : 130, 'completion_tokens_details' : None, 'prompt_tokens_details' : None}, 'model_name' : 'gpt-3.5-turbo-0125' , 'system_fingerprint' : 'fp_0165350fbb' , 'id' : 'chatcmpl-C7KxkXUF0pqZoe3fYnf1WwjXWs1yk' , 'service_tier' : None, 'finish_reason' : 'stop' , 'logprobs' : None} id ='run--0d0d9ed6-8a15-4eaa-b40b-ce1671d5e9aa-0' usage_metadata={'input_tokens' : 14, 'output_tokens' : 116, 'total_tokens' : 130, 'input_token_details' : {}, 'output_token_details' : {}}
小结:获取大模型的标准方式 后续的各种模型测试,都基于如下的模型展开:非对话模型 :
1 2 3 4 5 6 7 8 9 10 11 12 import os import dotenv from langchain_openai import OpenAI dotenv.load_dotenv() os.environ[ 'OPENAI_API_KEY' ] = os.getenv( "OPENAI_API_KEY" ) os.environ[ 'OPENAI_BASE_URL' ] = os.getenv( "OPENAI_BASE_URL" ) llm = OpenAI( )
对话模型 :
1 2 3 4 5 6 7 8 9 10 11 12 13 import os import dotenv from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ[ 'OPENAI_API_KEY' ] = os.getenv( "OPENAI_API_KEY" ) os.environ[ 'OPENAI_BASE_URL' ] = os.getenv( "OPENAI_BASE_URL" ) chat_model = ChatOpenAI( model= "gpt-4o-mini" , )
Model I/O之调用模型2 关于对话模型的Message(消息) 聊天模型,出了将字符串作为输入外,还可以使用聊天消息作为输入,并返回 聊天消息作为输出。
LangChain有一些内置的消息类型:
🔥SystemMessage :设定AI行为规则或背景信息。比如设定AI的初始状态、行为模式或对话的总 体目标。比如“作为一个代码专家”,或者“返回json格式”。通常作为输入消息序列中的第一个 传递。
🔥HumanMessage :表示来自用户输入。比如“实现 一个快速排序方法”
🔥AI Message :存储AI回复的内容。这可以是文本,也可以是调用工具的请求
ChatMessage :可以自定义角色的通用消息类型 FunctionMessage/ToolMessage :函数调用/工具消息,用于函数调用结果的消息类型
[!notice]
举例1:
1 2 3 4 5 6 7 8 from langchain_core.messages import SystemMessage, HumanMessage system_message = SystemMessage(content="你是一个英语教学方向的专家" ) human_message = HumanMessage(content="帮我制定一个英语六级学习的计划" ) messages = [system_message, human_message] print (messages)
1 [SystemMessage(content='你是一个英语教学方向的专家' , additional_kwargs={}, response_metadata={}), HumanMessage(content='帮我制定一个英语六级学习的计划' , additional_kwargs={}, response_metadata={})]
使用大模型,调用消息列表
1 2 3 response = chat_model.invoke(messages) print (type (response)) print (response.content)
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 <class 'langchain_core.messages.ai.AIMessage' > 制定一份高效的英语六级(CET-6)学习计划需要结合考试题型(听力、阅读、写作、翻译)和个人薄弱项。以下是一个**6-8周冲刺计划**的模板,可根据自身时间灵活调整: --- **目标:熟悉题型 + 核心词汇 + 基础训练** 1. **每日任务:** - **词汇(30分钟)** - 背诵30-50个六级高频词(推荐《六级核心词汇乱序版》或APP如"不背单词" )。 - 重点掌握词汇的**搭配用法**(如动词短语、常见介词搭配)。 - **听力(20分钟)** - 精听1篇短篇新闻/长对话(VOA常速或六级真题),听写关键句。 - **阅读(30分钟)** - 精读1篇六级真题选词填空或匹配题,分析长难句结构。 2. **每周任务:** - 完成1套真题(不计时),标注错题,分析错误原因(如:词汇盲区、逻辑偏差)。 --- **目标:分题型强化技巧 + 提速** 1. **听力(每日25分钟):** - **技巧**:注意转折词(but, however)、观点词(think, believe)、数字/时间。 - **训练**:每天1篇讲座/长对话,影子跟读法模仿语音语调。 2. **阅读(每日40分钟):** - **选词填空**:根据词性、上下文逻辑排除错误选项。 - **长篇阅读**:先读题干划关键词,速读文章定位。 - **仔细阅读**:重点分析首尾段、段落主旨句。 3. **写作翻译(隔日30分钟):** - **写作**:背诵3-4个万能模板(现象分析、观点对比等),每周写1篇并批改(可用Grammarly)。 - **翻译**:每日练习1句**中国文化/经济类**句子(参考《中国文化概览》),积累固定表达(如"被誉为" →be hailed as)。 --- **目标:全真模考 + 查漏补缺** 1. **每周2套真题(严格计时)**: - 按考试时间(15:00-17:25)模拟,训练时间分配(建议阅读40分钟、翻译30分钟)。 - 错题归类整理(如"听力主旨题错误" 、"翻译句型单一" )。 2. **重点强化:** - **薄弱题型加练**:例如听力弱则每天增加1篇精听。 - **高频话题突击**:写作关注人工智能、环保等热点;翻译积累传统节日、政策类词汇。 3. **考前3天:** - 复习错题本 + 背诵作文模板句。 - 听1套听力保持语感,避免生疏。 --- 1. **真题**:《星火六级真题详解》《华研外语六级真题》 2. **APP**:每日英语听力(真题音频)、China Daily(积累翻译词汇) 3. **写作素材**:公众号"LearnAndRecord" 、范文书《六级满分写作30天速成》 --- 1. **听力答案规律**:25道题普遍分布为6A+6B+6C+6D+1随机,可辅助检查。 2. **阅读顺序**:建议先做仔细阅读→长篇阅读→选词填空(保大分)。 3. **翻译原则**:**语义优先**,不要逐字翻译,用简单句保证正确性。 **每天学习建议2-3小时,坚持+复盘是关键!** 祝你顺利通过六级! 🎯
举例2:
1 2 3 4 5 6 7 8 9 10 11 from langchain_core.messages import SystemMessage, HumanMessage system_message = SystemMessage( content="你是一个英语教学方向的专家" , additional_kwargs={"tool" :"invoke_func1" } ) human_message = HumanMessage(content="帮我制定一个英语六级学习的计划" ) messages = [system_message, human_message] print (messages)
1 2 [SystemMessage(content='你是一个英语教学方向的专家' , additional_kwargs={'tool' : 'invoke_func1' }, response_metadata={}), HumanMessage(content='帮我制定一个英语六级学习的计划' , additional_kwargs={}, response_metadata={})]
举例3:ChatMessage平时我们使用的不多,了解一下即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from langchain_core.messages import ( AIMessage, HumanMessage, SystemMessage, ChatMessage ) system_message = SystemMessage(content="你是一个专业的数据科学家" ) human_message = HumanMessage(content="解释一下随机森林算法" ) ai_message = AIMessage(content="随机森林是一种集成学习方法..." ) custom_message = ChatMessage(role="analyst" , content="补充一点关于超参数调优的信息" ) print (system_message.content) print (human_message.content) print (ai_message.content) print (custom_message.content)
1 2 3 4 你是一个专业的数据科学家 解释一下随机森林算法 随机森林是一种集成学习方法... 补充一点关于超参数调优的信息
关于多轮对话与上下文记忆 前提:获取大模型
1 2 3 4 5 6 7 8 9 10 11 12 import os import dotenv from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY' ] = os.getenv("SILICONFLOW_API_KEY" ) os.environ['OPENAI_BASE_URL' ] = os.getenv("BASE_URL" ) chat_model = ChatOpenAI( model="deepseek-ai/DeepSeek-V3" )
测试1:大模型本身是没有上下文记忆能力的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain_core.messages import SystemMessage, HumanMessage sys_message = SystemMessage( content="我是一个人工智能的助手,我的名字叫小智" , ) human_message = HumanMessage(content="猫王是一只猫吗?" ) messages = [sys_message, human_message] response = chat_model.invoke(messages) response1 = chat_model.invoke("你叫什么名字?" ) print (response1.content)
1 2 3 我是 **DeepSeek Chat**,由深度求索公司创造的智能AI助手!你可以叫我 **DeepSeek** 或 **小深**~😊 很高兴认识你!请问有什么可以帮你的呢?
测试2:
1 2 3 4 5 6 7 8 9 10 11 12 13 from langchain_core.messages import SystemMessage, HumanMessage sys_message = SystemMessage( content="我是一个人工智能的助手,我的名字叫小智" , ) human_message = HumanMessage(content="猫王是一只猫吗?" ) human_message1 = HumanMessage(content="你叫什么名字?" ) messages = [sys_message, human_message,human_message1] response = chat_model.invoke(messages) print (response.content)
1 我是小智,一个可爱的AI助手!😊 有什么我可以帮您的吗?
测试3:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from langchain_core.messages import SystemMessage, HumanMessage sys_message = SystemMessage( content="我是一个人工智能的助手,我的名字叫小智" , ) human_message = HumanMessage(content="猫王是一只猫吗?" ) sys_message1 = SystemMessage( content="我可以做很多事情,有需要就找我吧" , ) human_message1 = HumanMessage(content="你叫什么名字?" ) messages = [sys_message, human_message,sys_message1,human_message1] response = chat_model.invoke(messages) print (response.content)
1 2 3 4 5 我叫小智,是你的专属AI助手!🎉 虽然"猫王" 不是真的猫(其实是指传奇音乐人埃尔维斯·普雷斯利啦~),但如果你需要一只虚拟猫,我可以立刻给你变个🐱表情包,或者讲个关于猫的冷笑话! 有需要随时叫我,无论是查资料、解闷还是帮忙,小智都在线哦✨
测试4:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from langchain_core.messages import SystemMessage, HumanMessage sys_message = SystemMessage( content="我是一个人工智能的助手,我的名字叫小智" , ) human_message = HumanMessage(content="猫王是一只猫吗?" ) messages = [sys_message, human_message] sys_message1 = SystemMessage( content="我可以做很多事情,有需要就找我吧" , ) human_message1 = HumanMessage(content="你叫什么名字?" ) messages1 = [sys_message1,human_message1] response = chat_model.invoke(messages) response = chat_model.invoke(messages1) print (response.content)
1 2 3 4 5 6 7 8 9 10 我是全能型AI助手!虽然我还没有专属的名字,但你可以叫我"小助手" 、"AI助手" ,或者给我取个你喜欢的昵称~ 😊 我的强项是: ✅ 解答各类问题 ✅ 处理复杂任务 ✅ 陪你聊天解闷 ✅ 给出专业建议 ✅ 24小时超长待机 不论是学习、工作上的难题,还是生活中的各种疑问,尽管开口问我!你希望我用什么风格跟你互动呢?(●'◡' ●)
测试5:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from langchain_core.messages import SystemMessage, HumanMessage, AIMessage messages = [ SystemMessage(content="我是一个人工智能助手,我的名字叫小智" ), HumanMessage(content="人工智能英文怎么说?" ), AIMessage(content="AI" ), HumanMessage(content="你叫什么名字" ), ] messages1 = [ SystemMessage(content="我是一个人工智能助手,我的名字叫小智" ), HumanMessage(content="很高兴认识你" ), AIMessage(content="我也很高兴认识你" ), HumanMessage(content="你叫什么名字" ), ] messages2 = [ SystemMessage(content="我是一个人工智能助手,我的名字叫小智" ), HumanMessage(content="人工智能英文怎么说?" ), AIMessage(content="AI" ), HumanMessage(content="你叫什么名字" ), ] chat_model.invoke(messages2)
1 AIMessage(content='我是人工智能助手小智,很高兴认识你!😊 有其他问题随时问我哦~', additional_kwargs={ 'refusal': None} , response_metadata={ 'token_usage': { 'completion_tokens': 19 , 'prompt_tokens': 23 , 'total_tokens': 42 , 'completion_tokens_details': None, 'prompt_tokens_details': None} , 'model_name': 'deepseek-ai/DeepSeek-V3', 'system_fingerprint': '', 'id': '01999473 f5180604c29829720e51917a', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} , id='run--e960ebf3-6822 -43 c5-8 b96-6 bbb5dfbfaab-0 ', usage_metadata={ 'input_tokens': 23 , 'output_tokens': 19 , 'total_tokens': 42 , 'input_token_details': { } , 'output_token_details': { } } )
关于模型调用的方法 为了尽可能简化自定义链的创建,我们实现了一个”Runnable”协议。许多LangChain组件实现了 Runnable 协议,包括聊天模型、提示词模板、输出解析器、检索器、代理(智能体)等。
Runnable 定义的公共的调用方法如下 :
invoke : 处理单条输入,等待LLM完全推理完成后再返回调用结果 stream : 流式响应,逐字输出LLM的响应结果 batch : 处理批量输入
这些也有相应的异步方法,应该与 asyncio 的await 语法一起使用以实现并发:
astream : 异步流式响应 ainvoke : 异步处理单条输入 abatch : 异步处理批量输入 astream_log : 异步流式返回中间步骤,以及最终响应 astream_events : (测试版)异步流式返回链中发生的事件(在 langchain-core 0.1.14 中引入)
举例1:非流式输出 : 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import os import dotenv from langchain_core.messages import HumanMessage from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY' ] = os.getenv("SILICONFLOW_API_KEY" ) os.environ['OPENAI_BASE_URL' ] = os.getenv("BASE_URL" ) chat_model = ChatOpenAI(model="deepseek-ai/DeepSeek-V3" ) messages = [HumanMessage(content="你好,请介绍一下自己" )] response = chat_model.invoke(messages) print (response)
举例2:流式的演示 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import os import dotenv from langchain_core.messages import HumanMessage from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY' ] = os.getenv("SILICONFLOW_API_KEY" ) os.environ['OPENAI_BASE_URL' ] = os.getenv("BASE_URL" ) chat_model = ChatOpenAI(model="deepseek-ai/DeepSeek-V3" , streaming=True ) messages = [HumanMessage(content="你好,请介绍一下自己" )] print ("开始流式输出:" ) for chunk in chat_model.stream(messages): print (chunk.content, end="" , flush=True ) print ("\n流式输出结束" )
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 开始流式输出: 你好!我是 **DeepSeek Chat**,由深度求索公司打造的一款智能对话助手。我可以帮助你解答各种问题、提供写作灵感、协助分析文档、生成创意内容,甚至陪你闲聊!✨ - **免费可用**:目前不收取任何费用,放心使用! - **大容量知识**:我的知识截至 **2024年7月**,可以为你提供较新的资讯。 - **超长上下文记忆**:支持 **128K tokens**,适合处理长文档、复杂讨论或代码分析。 - **文件阅读**:可以上传 **PDF、Word、Excel 等文件**,我能帮你提取和分析内容。 - **中文优化**:对中文理解和生成特别友好,适合各种中文场景。 - **不擅长图片生成**(目前我是纯文本模型),但可以帮你描述或分析图片内容! 不管是学习、工作还是日常生活,有什么问题都可以问我哦!😊 **你今天想了解什么呢?** 流式输出结束
举例3:使用batch,测试批量调用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import os import dotenv from langchain_core.messages import HumanMessage, SystemMessage from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY' ] = os.getenv("SILICONFLOW_API_KEY" ) os.environ['OPENAI_BASE_URL' ] = os.getenv("BASE_URL" ) chat_model = ChatOpenAI(model="deepseek-ai/DeepSeek-V3" ) messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手" ), HumanMessage(content="请帮我介绍一下什么是机器学习" ), ] messages2 = [SystemMessage(content="你是一位乐于助人的智能小助手" ), HumanMessage(content="请帮我介绍一下什么是AIGC" ), ] messages3 = [SystemMessage(content="你是一位乐于助人的智能小助手" ), HumanMessage(content="请帮我介绍一下什么是大模型技术" ), ] messages = [messages1, messages2, messages3] response = chat_model.batch(messages) print (response)
1 [ AIMessage(content='机器学习(Machine Learning, ML)是人工智能(AI)的一个核心分支,致力于通过数据和算法让计算机系统自动“学习”并改进性能,而无需显式编程。以下是其关键概念和组成部分的清晰介绍:\n\n---\n\n### **1. 核心定义**\n- **本质**:机器学习通过从历史数据中识别模式或规律,构建数学模型(即“训练”),从而对新数据做出预测或决策。\n- **与传统编程的区别**: \n - 传统编程:人工编写规则,输入数据,输出结果。 \n - 机器学习:输入数据+预期结果,机器自动生成规则(模型),用于处理新数据。\n\n---\n\n### **2. 核心类型**\n- **监督学习(Supervised Learning)** \n - **任务**:用已标注(带答案)的数据训练模型,预测未知数据的标签。 \n - **例子**:垃圾邮件分类(输入邮件,输出“垃圾/正常”)、房价预测。 \n - **常用算法**:线性回归、决策树、支持向量机(SVM)、神经网络。\n\n- **无监督学习(Unsupervised Learning)** \n - **任务**:从无标注数据中发现隐藏结构(如分组或降维)。 \n - **例子**:客户细分(将用户分成不同群组)、异常检测。 \n - **常用算法**:K均值聚类、主成分分析(PCA)。\n\n- **强化学习(Reinforcement Learning)** \n - **任务**:智能体通过试错与环境交互,根据奖励信号优化策略。 \n - **例子**:AlphaGo游戏策略、机器人导航。 \n\n- **其他类型**:半监督学习、自监督学习、迁移学习等。\n\n---\n\n### **3. 典型流程**\n1. **数据收集**:获取高质量、代表性的原始数据(如图像、文本、数值)。 \n2. **数据预处理**:清洗(处理缺失值、异常值)、归一化、特征工程(提取关键特征)。 \n3. **模型选择**:根据任务类型选择算法(如分类任务选随机森林)。 \n4. **训练与评估**: \n - 用训练集拟合模型,用验证集调参,用测试集评估性能。 \n - 常用指标:准确率、召回率、均方误差(MSE)等。 \n5. **部署与迭代**:将模型应用于实际场景,持续监控并优化。\n\n---\n\n### **4. 为什么重要?**\n- **自动化决策**:处理海量数据的速度和精度远超人类(如医疗影像分析)。 \n- **适应性**:模型可随新数据动态更新(如推荐系统适应用户偏好变化)。 \n- **跨领域应用**:金融(信用评分)、医疗(疾病预测)、制造业(故障检测)等。\n\n---\n\n### **5. 挑战与限制**\n- **数据依赖**:需大量高质量数据,数据偏差会导致模型偏见。 \n- **过拟合**:模型在训练数据上表现好,但泛化能力差(可通过正则化、交叉验证缓解)。 \n- **可解释性**:深度学习等复杂模型常被视为“黑箱”,需可解释性技术(如SHAP值)。\n\n---\n\n### **6. 扩展方向**\n- **深度学习**:基于多层神经网络的机器学习,擅长图像、语音等复杂数据。 \n- **集成学习**:结合多个模型提升性能(如随机森林、XGBoost)。 \n- **联邦学习**:分散式训练,保护数据隐私。\n\n---\n\n机器学习正持续改变各行各业,但其成功依赖对问题场景的理解、数据的合理处理以及模型的选择优化。如需进一步了解某个具体领域(如算法细节、应用案例),可以深入探讨!', additional_kwargs={ 'refusal': None} , response_metadata={ 'token_usage': { 'completion_tokens': 784 , 'prompt_tokens': 16 , 'total_tokens': 800 , 'completion_tokens_details': None, 'prompt_tokens_details': None} , 'model_name': 'deepseek-ai/DeepSeek-V3', 'system_fingerprint': '', 'id': '0199947 d483332aa6c642e23ed0bbdc4', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} , id='run--2 fe38b71-0 eb5-4 d97-9 a96-18895 b0e5343-0 ', usage_metadata={ 'input_tokens': 16 , 'output_tokens': 784 , 'total_tokens': 800 , 'input_token_details': { } , 'output_token_details': { } } ), AIMessage(content='AIGC(AI-Generated Content,人工智能生成内容)是指利用人工智能技术自动或半自动地生成文本、图像、音频、视频、代码等内容的新型内容创作方式。随着深度学习、自然语言处理(NLP)、计算机视觉等技术的快速发展,AIGC正在深刻改变内容生产的效率和模式。\n\n### **核心特点**\n1. **自动化创作**:无需全程人工参与,AI可基于输入指令(如文字提示)独立生成内容。\n2. **多模态输出**:支持生成多种形式的内容,如文本(ChatGPT)、图像(MidJourney)、音乐(Jukedeck)、视频(Sora)等。\n3. **高效迭代**:快速生成多个版本,帮助用户优化创意或测试不同方案。\n\n### **关键技术**\n- **生成对抗网络(GAN)**:通过生成器和判别器的对抗训练生成逼真数据(如人脸图像)。\n- **大语言模型(LLM)**:如GPT-4 、Claude等,擅长理解并生成自然语言文本。\n- **扩散模型(Diffusion Models)**:通过逐步去噪生成高质量图像(如Stable Diffusion)。\n- **多模态模型**:如DALL·E(图文生成)、Whisper(语音转文本)等。\n\n### **典型应用场景**\n- **文字创作**:新闻稿、广告文案、剧本、代码生成等。\n- **视觉设计**:海报、插画、3 D模型、电商产品图。\n- **影音制作**:短视频、虚拟主播、AI配音、背景音乐。\n- **游戏开发**:自动生成关卡、角色对话或场景素材。\n- **个性化推荐**:动态生成用户专属内容(如营销邮件)。\n\n### **面临的挑战**\n- **版权争议**:训练数据可能涉及未经授权的原创内容。\n- **质量波动**:输出结果需人工校验,可能存在逻辑错误或低质量内容。\n- **伦理风险**:虚假信息(Deepfake)、偏见放大等问题需监管应对。\n\n### **未来趋势**\nAIGC正从辅助工具转向协同创造,未来可能与VR/AR、元宇宙结合,进一步降低内容创作门槛。企业也在探索“人类创意+AI效率”的混合工作流。\n\n如果需要了解具体工具或领域(如AI绘画、写作),可以进一步探讨!', additional_kwargs={ 'refusal': None} , response_metadata={ 'token_usage': { 'completion_tokens': 481 , 'prompt_tokens': 18 , 'total_tokens': 499 , 'completion_tokens_details': None, 'prompt_tokens_details': None} , 'model_name': 'deepseek-ai/DeepSeek-V3', 'system_fingerprint': '', 'id': '0199947 d4837dda4d703fbcfc4e54111', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} , id='run--8783e087 -8 d75-4 afb-b3c4-3 deed473ce70-0 ', usage_metadata={ 'input_tokens': 18 , 'output_tokens': 481 , 'total_tokens': 499 , 'input_token_details': { } , 'output_token_details': { } } ), AIMessage(content='大模型技术(Large Language Models,LLMs)是当前人工智能领域的重要突破,指通过海量数据和庞大参数规模训练的深度学习模型,能够处理自然语言理解、生成、推理等复杂任务。以下是其核心要点:\n\n---\n\n### **1. 基本概念**\n- **参数规模**:通常指参数量达到数十亿(如GPT-3 含1750 亿参数)甚至万亿的模型,参数越多模型能力通常越强。\n- **预训练+微调**:先在广泛的无标注数据上学习通用语言模式(如互联网文本),再针对特定任务微调。\n\n---\n\n### **2. 核心技术原理**\n- **Transformer架构**:基于自注意力机制(Self-Attention),可并行处理长序列数据,突破传统RNN的局限性。\n- **核心组件**:\n - **多头注意力**:捕捉文本中远距离依赖关系。\n - **位置编码**:保留词汇顺序信息。\n - **大规模无监督学习**:通过预测下一个词(语言建模)学习语言规律。\n\n---\n\n### **3. 典型代表模型**\n- **GPT系列**(OpenAI):生成式预训练模型,擅长文本创作、问答。\n- **BERT**(Google):双向编码模型,适合文本分类、实体识别。\n- **PaLM**(Google)、**LLaMA**(Meta):参数量化与效率优化代表。\n- **多模态模型**(如GPT-4 V、Gemini):支持图像、音频等多数据类型输入。\n\n---\n\n### **4. 关键能力**\n- **自然语言生成**:写作、翻译、代码生成。\n- **上下文理解**:长文对话、逻辑推理。\n- **零样本/小样本学习**:无需大量标注数据即可完成新任务。\n- **思维链(Chain-of-Thought)**:分步推理解决数学或逻辑问题。\n\n---\n\n### **5. 应用场景**\n- **通用领域**:智能客服、内容创作、教育辅助。\n- **垂直行业**:医疗诊断辅助、法律文书分析、金融预测。\n- **开发者工具**:代码补全(GitHub Copilot)、自动化测试。\n\n---\n\n### **6. 挑战与局限**\n- **算力需求**:训练需高性能GPU集群,成本高昂。\n- **幻觉问题**:可能生成虚假或有害内容。\n- **偏见与安全**:数据偏差导致输出歧视性内容。\n- **可解释性**:内部决策过程像“黑箱”,难以追踪。\n\n---\n\n### **7. 未来方向**\n- **小型化**:模型压缩(如量化、蒸馏)以适配边缘设备。\n- **能耗优化**:绿色AI降低碳足迹。\n- **可控生成**:提升输出可靠性与安全性。\n- **具身智能**:结合机器人等物理世界交互。\n\n---\n\n如果需要了解特定模型(如ChatGPT原理)或应用案例,可以进一步探讨!', additional_kwargs={ 'refusal': None} , response_metadata={ 'token_usage': { 'completion_tokens': 608 , 'prompt_tokens': 18 , 'total_tokens': 626 , 'completion_tokens_details': None, 'prompt_tokens_details': None} , 'model_name': 'deepseek-ai/DeepSeek-V3', 'system_fingerprint': '', 'id': '0199947 d483e6011f5a633be4c177da2', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} , id='run--3 a0858f3-60e8 -46 c3-bbf6-0e78 b4fa3903-0 ', usage_metadata={ 'input_tokens': 18 , 'output_tokens': 608 , 'total_tokens': 626 , 'input_token_details': { } , 'output_token_details': { } } )]
举例4:关于同步和异步方法的调用 同步调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import time def call_model (): print ("开始调用模型..." ) time.sleep(5 ) print ("模型调用完成。" ) def perform_other_tasks (): for i in range (5 ): print (f"执行其他任务 {i + 1 } " ) time.sleep(1 ) def main (): start_time = time.time() call_model() perform_other_tasks() end_time = time.time() total_time = end_time - start_time return f"总共耗时:{total_time} 秒" main_time = main() print (main_time)
1 2 3 4 5 6 7 8 开始调用模型... 模型调用完成。 执行其他任务 1 执行其他任务 2 执行其他任务 3 执行其他任务 4 执行其他任务 5 总共耗时:10.0043363571167秒
体会2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import asyncio import os import time import dotenv from langchain_core.messages import HumanMessage, SystemMessage from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY' ] = os.getenv("SILICONFLOW_API_KEY" ) os.environ['OPENAI_BASE_URL' ] = os.getenv("BASE_URL" ) chat_model = ChatOpenAI(model="deepseek-ai/DeepSeek-V3" ) def sync_test (): messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手" ), HumanMessage(content="请帮我介绍一下什么是机器学习" ), ] start_time = time.time() response = chat_model.invoke(messages1) duration = time.time() - start_time print (f"同步调用耗时:{duration:.2 f} 秒" ) return response, duration async def async_test (): messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手" ), HumanMessage(content="请帮我介绍一下什么是机器学习" ), ] start_time = time.time() response = await chat_model.ainvoke(messages1) duration = time.time() - start_time print (f"异步调用耗时:{duration:.2 f} 秒" ) return response, duration if __name__ == "__main__" : sync_response, sync_duration = sync_test() print (f"同步响应内容: {sync_response.content[:100 ]} ...\n" ) async_response, async_duration = asyncio.run(async_test()) print (f"异步响应内容: {async_response.content[:100 ]} ...\n" ) print ("\n=== 并发测试 ===" ) start_time = time.time() async def run_concurrent_tests (): tasks = [async_test() for _ in range (3 )] return await asyncio.gather(*tasks) results = asyncio.run(run_concurrent_tests()) total_time = time.time() - start_time print (f"\n3个并发异步调用总耗时: {total_time:.2 f} 秒" ) print (f"平均每个调用耗时: {total_time / 3 :.2 f} 秒" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 同步调用耗时:15.73秒 同步响应内容: 机器学习(Machine Learning, ML)是人工智能(AI)的一个核心分支,其目标是让计算机系统能够通过数据**自动学习和改进**,而无需显式编程。简单来说,机器学习通过分析大量数据来发现规... 异步调用耗时:13.78秒 异步响应内容: 机器学习(Machine Learning, ML)是人工智能(AI)的一个核心分支,致力于通过数据和算法让计算机系统具备“学习”能力,从而自动完成任务或改进性能,而无需显式编程。以下是它的关键概念和... === 并发测试 === 异步调用耗时:14.54秒 异步调用耗时:16.29秒 异步调用耗时:19.98秒 3个并发异步调用总耗时: 19.99秒 平均每个调用耗时: 6.66秒 进程已结束,退出代码为 0
Model I/O之Prompt Template Prompt Template,通过模板管理大模型的输入。
介绍与分类 Prompt Template 是LangChain中的一个概念,接收用户输入,返回一个传递给LLM的信息(即提示 词prompt)
在应用开发中,固定的提示词限制了模型的灵活性和适用范围。所以,prompt template 是一个 模板化 的字符串 ,你可以将 变量插入到模板 中,从而创建出不同的提示。调用时:
以字典 作为输入,其中每个键代表要填充的提示模板中的变量。
输出一个 PromptValue 。这个 PromptValue 可以传递给 LLM 或 ChatModel,并且还可以转换 为字符串或消息列表。
有几种不同类型的提示模板 :
PromptTemplate :LLM提示模板,用于生成字符串提示 。它使用 Python 的字符串来模板提示。 ChatPromptTemplate :聊天提示模板,用于组合各种角色的消息模板 ,传入聊天模型。 XxxMessagePromptTemplate :消息模板词模板,包括:SystemMessagePromptTemplate、 HumanMessagePromptTemplate、AIMessagePromptTemplate、 ChatMessagePromptTemplate等 FewShotPromptTemplate :样本提示词模板,通过示例来教模型如何回答 PipelinePrompt :管道提示词模板,用于把几个提示词组合在一起使用。 自定义模板:允许基于其它模板类来定制自己的提示词模板。
具体使用:PromptTemplate 使用说明 PromptTemplate类,用于快速构建 包含变量 的提示词模板,并通过传入不同的参数值 生成自定义的提示词。主要参数介绍 :
template :定义提示词模板的字符串,其中包含文本和变量占位符(如{name}) ; input_variables : 列表,指定了模板中使用的变量名称,在调用模板时被替换; partial_variables :字典,用于定义模板中一些固定的变量名。这些值不需要再每次调用时被替换。
函数介绍:
**format()**:给input_variables变量赋值,并返回提示词。利用format() 进行格式化时就一定要赋 值,否则会报错。当在template中未设置input_variables,则会自动忽略。
两种实例化方式 方式1:使用构造方法 1 2 3 4 5 6 7 8 9 10 11 12 13 from langchain.prompts import PromptTemplate template = PromptTemplate(template= "请简要描述{topic}的应用。" , input_variables=[ "topic" ]) print (template)prompt_1 = template.format (topic= "机器学习" ) prompt_2 = template.format (topic= "自然语言处理" ) print ( "提示词1:" , prompt_1) print ( "提示词2:" , prompt_2)
1 2 3 input_variables=[topic] input_types={} partial_variables={} template=请简要描述{topic}的 应⽤。' 提⽰词1: 请简要描述机器学习的应⽤。 提⽰词2: 请简要描述⾃然语⾔处理的应⽤。
可以直观的看到PromptTemplate可以将template中声明的变量topic准确提取出来,使prompt更清晰
举例2:定义多变量模板(推荐) 1 2 3 4 5 6 7 8 9 10 11 12 13 from langchain_core.prompts import PromptTemplate prompt_template = PromptTemplate.from_template(template="你是一个{role},你的名字叫{name}" ) prompt = prompt_template.format (role="人工智能专家" ,name="小智" ) print (prompt)
结果:
如果提示词模板中不包含变量,则调用format()时,不需要传入参数!
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_core.prompts import PromptTemplate text = """ Tell me a joke """ prompt_template = PromptTemplate.from_template(text) prompt = prompt_template.format () print (prompt)
两种新的结构形式 形式1:部分提示词模版 在生成prompt前就已经提前初始化部分的提示词,实际进一步导入模版的时候只导入除已初始化的变量 即可。
举例1:
1 2 3 4 5 6 7 8 9 10 11 12 from langchain.prompts import PromptTemplate template = PromptTemplate.from_template( template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。" , partial_variables={"aspect1" :"电池续航" } ) prompt_1 = template.format (product="智能手机" ,aspect2="拍照质量" ) print (prompt_1)
1 请评价智能手机的优缺点,包括电池续航和拍照质量。
1 2 3 4 5 6 7 8 9 10 11 12 13 from langchain.prompts import PromptTemplate template = PromptTemplate( template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。" , input_variables=["product" , "aspect1" , "aspect2" ], partial_variables={"aspect1" :"电池续航" ,"aspect2" :"拍照质量" } ) prompt_1 = template.format (product="智能手机" ) print ("提示词1:" ,prompt_1)
1 提示词1: 请评价智能手机的优缺点,包括电池续航和拍照质量。
方式2:调用方法partial() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain.prompts import PromptTemplate template = PromptTemplate( template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。" , input_variables=["product" , "aspect1" , "aspect2" ], ) template1 = template.partial(aspect1="电池续航" ,aspect2="拍照质量" ) prompt_1 = template1.format (product="智能手机" ) print ("提示词1:" ,prompt_1)
1 提示词1: 请评价智能手机的优缺点,包括电池续航和拍照质量。
1 2 3 4 5 6 7 8 9 10 11 12 from langchain.prompts import PromptTemplate template = PromptTemplate( template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。" , input_variables=["product" , "aspect1" , "aspect2" ], ).partial(aspect1="电池续航" ,aspect2="拍照质量" ) prompt_1 = template.format (product="智能手机" ) print ("提示词1:" ,prompt_1)
1 提示词1: 请评价智能手机的优缺点,包括电池续航和拍照质量。
1 2 3 4 5 6 7 8 9 10 11 from langchain.prompts import PromptTemplate template = (PromptTemplate .from_template(template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。" ) .partial(aspect1="电池续航" ,aspect2="拍照质量" )) prompt_1 = template.format (product="智能手机" ) print ("提示词1:" ,prompt_1)
1 提示词1: 请评价智能手机的优缺点,包括电池续航和拍照质量。
组合提示词的使用(了解) 1 2 3 4 5 6 7 8 9 10 from langchain_core.prompts import PromptTemplate template = ( PromptTemplate.from_template(template = "Tell me a joke about {topic}" ) + ", make it funny" + "\n\nand in {language}" ) prompt = template.format (topic="sports" , language="spanish" ) print (prompt)
1 2 3 Tell me a joke about sports, make it funny and in spanish
format() : 参数部分:给变量赋值; 返回值:str类型
invoke() : 参数部分:使用的是字典; 返回值:PromptValue类型 —推荐!
举例:调用format()
1 2 3 4 5 6 7 8 9 10 11 from langchain.prompts import PromptTemplate template = PromptTemplate.from_template( template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。" ) prompt_1 = template.format (product="智能手机" , aspect1="电池续航" , aspect2="拍照质量" ) print (prompt_1) print (type (prompt_1))
1 2 请评价智能手机的优缺点,包括电池续航和拍照质量。 <class 'str'>
举例:调用invoke()
1 2 3 4 5 6 7 8 9 10 11 12 from langchain.prompts import PromptTemplate template = PromptTemplate.from_template( template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。" ) prompt_1 = template.invoke(input ={"product" :"智能手机" ,"aspect1" :"电池续航" ,"aspect2" :"拍照质量" }) print (prompt_1) print (type (prompt_1))
1 2 text='请评价智能手机的优缺点,包括电池续航和拍照质量。' <class 'langchain_core.prompt_values.StringPromptValue'>
结合大模型的使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from langchain_openai import ChatOpenAI import os import dotenv dotenv.load_dotenv() os.environ["OPENAI_BASE_URL" ] = os.getenv("BASE_URL" ) os.environ["OPENAI_API_KEY" ] = os.getenv("SILICONFLOW_API_KEY" ) chat_model = ChatOpenAI( model='deepseek-ai/DeepSeek-V3' , max_tokens=500 ) template = PromptTemplate.from_template( template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。" ) prompt = template.invoke(input ={"product" :"智能手机" ,"aspect1" :"电池续航" ,"aspect2" :"拍照质量" }) response= chat_model.invoke(prompt) print (response) print (type (response))
结果:
1 2 content='智能手机已成为现代生活的核心工具,其优缺点在不同场景下表现各异,尤其在电池续航和拍照质量这两个用户最关注的方面尤为明显。以下是具体分析:\n\n---\n\n### **一、优点**\n1. **拍照质量** \n - **技术突破**:多摄像头系统(超广角、长焦、微距)、大底传感器、计算摄影(如夜景模式、HDR)让手机摄影接近专业设备水平。 \n - **AI优化**:自动场景识别、人像虚化算法、实时滤镜大大降低用户操作门槛。 \n - **便携性**:相比单反相机,手机能随时随地捕捉画面,适合日常记录和社交媒体分享。\n\n2. **其他核心优势** \n - **多功能整合**:通讯、支付、导航、娱乐一体化,减少携带多种设备的麻烦。 \n - **高性能处理器**:流畅运行大型应用和游戏,5G网络提升实时交互体验。 \n - **生态互联**:与智能家居、穿戴设备无缝连接(如Apple生态、华为鸿蒙)。\n\n---\n\n### **二、缺点**\n1. **电池续航** \n - **硬件瓶颈**:屏幕高刷新率(120Hz+)、5G网络、高性能芯片加剧耗电,重度使用需每日1-2充。 \n - **充电依赖**:快充技术(如200W)缩短充电时间,但频繁充电仍可能加速电池老化(2年后容量显著下降)。 \n - **使用场景限制**:户外活动或长途旅行时,若无电源需依赖充电宝。\n\n2. **拍照的局限性** \n - **硬件天花板**:小尺寸传感器在暗光环境下噪点明显,光学变焦范围有限(主流机型仅3-5倍无损变焦)。 \n - **算法痕迹**:过度锐化或AI美化可能导致照片失真(如虚假的天空增强)。 \n - **专业功能缺失**:手动调节参数(如快门速度、RAW格式)不如专业相机直观。\n\n3. **其他问题** \n - **隐私风险**:摄像头权限滥用可能导致数据泄露。 \n - **价格分层**:高端机型(如iPhone Pro、三星Ultra)与中低端机拍照性能差距显著。\n\n---\n\n### **三、平衡与建议**\n- **选购策略**: \n - 注重续航:选择电池≥5000mAh + 低功耗芯片(如天玑9000)的机型。 \n - 追求拍照:优先考虑大底主摄(如1英寸传感器)+ 光学防抖的旗舰机。 \n- **使用技巧**:关闭后台高耗电应用、使用优化拍摄模式(如手动夜景),可部分弥补短板。\n\n---\n\n### **总结** \n智能手机在便携性与功能整合上无可替代,但电池和拍照仍受物理限制。未来随着固态电池、折叠屏和更先进的AI算法发展,这些痛点或逐步改善。用户需根据需求权衡,而非一味追求参数。' additional_kwargs={'refusal' : None} response_metadata={'token_usage' : {'completion_tokens' : 625, 'prompt_tokens' : 16, 'total_tokens' : 641, 'completion_tokens_details' : None, 'prompt_tokens_details' : None}, 'model_name' : 'deepseek-ai/DeepSeek-V3' , 'system_fingerprint' : '' , 'id' : '019994251555f311e62f227a7a7913d8' , 'service_tier' : None, 'finish_reason' : 'stop' , 'logprobs' : None} id ='run--f2f96594-7c48-4ed5-8970-49aa051748fa-0' usage_metadata={'input_tokens' : 16, 'output_tokens' : 625, 'total_tokens' : 641, 'input_token_details' : {}, 'output_token_details' : {}} <class 'langchain_core.messages.ai.AIMessage' >
具体使用:ChatPromptTemplate 1、实例化的方式(两种方式:使用构造方法、from_messages())
2、调用提示词模板的几种方法:invoke() \ format() \ format_messages() \ format_prompt()
3、更丰富的实例化参数类型
4、结合LLM
5、插入消息列表:MessagePlaceholder
实例化的方式 方式1:使用构造方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder chat_prompt_template = ChatPromptTemplate( messages=[ ("system" , "你是一个AI助手,你的名字叫{name}" ), ("human" , "我的问题是{question}" ) ], input_variables=["name" , "question" ], ) response = chat_prompt_template.invoke(input ={"name" : "小智" , "question" : "1 + 2 * 3 = ?" }) print (response) print (type (response)) print (len (response.messages))
1 2 3 messages=[SystemMessage(content='你是一个AI助手,你的名字叫小智' , additional_kwargs={}, response_metadata={}), HumanMessage(content='我的问题是1 + 2 * 3 = ?' , additional_kwargs={}, response_metadata={})] <class 'langchain_core.prompt_values.ChatPromptValue' > 2
更简洁的方式:
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_core.prompts import ChatPromptTemplate chat_prompt_template = ChatPromptTemplate([ ("system" , "你是一个AI助手,你的名字叫{name}" ), ("human" , "我的问题是{question}" ) ]) response = chat_prompt_template.invoke({"name" : "小智" , "question" : "1 + 2 * 3 = ?" }) print (response) print (type (response)) print (len (response.messages))
1 2 3 messages=[SystemMessage(content='你是一个AI助手,你的名字叫小智' , additional_kwargs={}, response_metadata={}), HumanMessage(content='我的问题是1 + 2 * 3 = ?' , additional_kwargs={}, response_metadata={})] <class 'langchain_core.prompt_values.ChatPromptValue' > 2
调用提示词模板的几种方法 invoke() \ format() \ format_messages() \ format_prompt()
invoke():传入的是字典,返回ChatPromptValue
format():传入变量的值,返回str
format_messages(): 传入变量的值,返回消息构成的list
format_prompt(): 传入变量的值,返回ChatPromptValue
举例1:invoke()
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_core.prompts import ChatPromptTemplate chat_prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个AI助手,你的名字叫{name}" ), ("human" , "我的问题是{question}" ) ]) response = chat_prompt_template.invoke({"name" : "小智" , "question" : "1 + 2 * 3 = ?" }) print (response) print (type (response))
1 2 messages=[SystemMessage(content='你是一个AI助手,你的名字叫小智' , additional_kwargs={}, response_metadata={}), HumanMessage(content='我的问题是1 + 2 * 3 = ?' , additional_kwargs={}, response_metadata={})] <class 'langchain_core.prompt_values.ChatPromptValue' >
举例2:format()
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_core.prompts import ChatPromptTemplate chat_prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个AI助手,你的名字叫{name}" ), ("human" , "我的问题是{question}" ) ]) response = chat_prompt_template.format (name="小智" , question="1 + 2 * 3 = ?" ) print (response) print (type (response))
1 2 3 System: 你是一个AI助手,你的名字叫小智 Human: 我的问题是1 + 2 * 3 = ? <class 'str' >
举例3:format_messages()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain_core.prompts import ChatPromptTemplate chat_prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个AI助手,你的名字叫{name}" ), ("human" , "我的问题是{question}" ) ]) response = chat_prompt_template.format_messages(name="小智" , question="1 + 2 * 3 = ?" ) print (response) print (type (response)) chat_prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个AI助手,你的名字叫{name}" ), ("human" , "我的问题是{question}" ) ]) response = chat_prompt_template.format_messages(name="小智" , question="1 + 2 * 3 = ?" ) print (response) print (type (response))
1 2 [SystemMessage(content='你是一个AI助手,你的名字叫小智' , additional_kwargs={}, response_metadata={}), HumanMessage(content='我的问题是1 + 2 * 3 = ?' , additional_kwargs={}, response_metadata={})] <class 'list' >
结论 :给占位符赋值,针对于ChatPromptTemplate,推荐使用format_messages()方法,返回消息列 表。
举例4:format_prompt()
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_core.prompts import ChatPromptTemplate chat_prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个AI助手,你的名字叫{name}" ), ("human" , "我的问题是{question}" ) ]) response = chat_prompt_template.format_prompt(name="小智" , question="1 + 2 * 3 = ?" ) print (response) print (type (response))
1 2 messages=[SystemMessage(content='你是一个AI助手,你的名字叫小智' , additional_kwargs={}, response_metadata={}), HumanMessage(content='我的问题是1 + 2 * 3 = ?' , additional_kwargs={}, response_metadata={})] <class 'langchain_core.prompt_values.ChatPromptValue' >
更丰富的实例化参数类型 本质:不管使用构造方法、还是使用from_message()来创建ChatPromptTemplate的实例,本质上来讲,传入的都是消息构成的列表。
从调用上来讲,我们看到,不管使用构造方法,还是使用from_message(),messages参数的类型都是列表,但是列表的元素的类型是多样的。元素可以是:
字符串类型、字典类型、消息类型、元组构成的列表(最常用、最基础、最简单)、Chat提示词模板类型、消息提示词模板类型
举例1:元组构成的列表(最常用、最基础、最简单)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from langchain_core.prompts import ChatPromptTemplate chat_prompt_template1 = ChatPromptTemplate( messages=[ ("system" , "你是一个AI助手,你的名字叫{name}" ), ("human" , "我的问题是{question}" ) ] ) chat_prompt_template2 = ChatPromptTemplate.from_messages([ ("system" , "你是一个AI助手,你的名字叫{name}" ), ("human" , "我的问题是{question}" ) ]) response = chat_prompt_template1.invoke({"name" : "小智" , "question" : "1 + 2 * 3 = ?" })
举例2:字符串
1 2 3 4 5 6 7 8 9 10 from langchain_core.prompts import ChatPromptTemplate chat_prompt_template = ChatPromptTemplate.from_messages([ "我的问题是{question}" ]) response = chat_prompt_template.invoke({"question" : "1 + 2 * 3 = ?" }) print (response)
1 messages=[HumanMessage(content='我的问题是1 + 2 * 3 = ?' , additional_kwargs={}, response_metadata={})]
举例3:字典类型
1 2 3 4 5 6 7 8 9 10 11 from langchain_core.prompts import ChatPromptTemplate chat_prompt_template = ChatPromptTemplate.from_messages([ {"role" : "system" , "content" : "我是一个人工智能助手,我的名字叫{name}" }, {"role" : "human" , "content" : "我的问题是{question}" }, ]) response = chat_prompt_template.invoke({"name" : "小智" , "question" : "1 + 2 * 3 = ?" }) print (response)
1 messages=[SystemMessage(content='我是一个人工智能助手,我的名字叫小智' , additional_kwargs={}, response_metadata={}), HumanMessage(content='我的问题是1 + 2 * 3 = ?' , additional_kwargs={}, response_metadata={})]
举例4:消息类型
1 2 3 4 5 6 7 8 9 10 11 12 13 from langchain_core.messages import SystemMessage, HumanMessage from langchain_core.prompts import ChatPromptTemplate chat_prompt_template = ChatPromptTemplate.from_messages([ SystemMessage(content="我是一个人工智能助手,我的名字叫{name}" ), HumanMessage(content="我的问题是{question}" ) ]) response = chat_prompt_template.invoke({}) print (response)
1 messages=[SystemMessage(content='我是一个人工智能助手,我的名字叫{name}' , additional_kwargs={}, response_metadata={}), HumanMessage(content='我的问题是{question}' , additional_kwargs={}, response_metadata={})]
举例5:Chat提示词模板类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain_core.prompts import ChatPromptTemplate nested_prompt_template1 = ChatPromptTemplate.from_messages([ ("system" , "我是一个人工智能助手,我的名字叫{name}" ) ]) nested_prompt_template2 = ChatPromptTemplate.from_messages([ ("human" , "很高兴认识你,我的问题是{question}" ) ]) prompt_template = ChatPromptTemplate.from_messages([ nested_prompt_template1, nested_prompt_template2 ]) prompt_template.format_messages(name="小智" , question="你为什么这么帅?" )
1 2 [SystemMessage(content='我是一个人工智能助手,我的名字叫小智' , additional_kwargs={}, response_metadata={}), HumanMessage(content='很高兴认识你,我的问题是你为什么这么帅?' , additional_kwargs={}, response_metadata={})]
举例6:消息提示词模板类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, SystemMessagePromptTemplate system_template = "你是一个专家{role}" system_message_prompt = SystemMessagePromptTemplate.from_template(system_template) human_template = "给我解释{concept},用浅显易懂的语言" human_message_prompt = HumanMessagePromptTemplate.from_template(human_template) chat_prompt = ChatPromptTemplate.from_messages([ system_message_prompt, human_message_prompt ]) formatted_messages = chat_prompt.format_messages( role="物理学家" , concept="相对论" ) print (formatted_messages)
1 [SystemMessage(content='你是一个专家物理学家' , additional_kwargs={}, response_metadata={}), HumanMessage(content='给我解释相对论,用浅显易懂的语言' , additional_kwargs={}, response_metadata={})]
结合LLM 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from langchain_openai import ChatOpenAI import os import dotenv dotenv.load_dotenv() os.environ["OPENAI_BASE_URL" ] = os.getenv("OPENAI_BASE_URL" ) os.environ["OPENAI_API_KEY" ] = os.getenv("OPENAI_API_KEY1" ) chat_model = ChatOpenAI( model="gpt-4o-mini" ) from langchain_core.prompts import ChatPromptTemplate chat_prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个AI助手,你的名字叫{name}" ), ("human" , "我的问题是{question}" ) ]) prompt_response = chat_prompt_template.invoke({"name" : "小智" , "question" : "1 + 2 * 3 = ?" }) response = chat_model.invoke(prompt_response) print (response)
1 content='根据运算顺序,首先计算乘法,再计算加法。\n\n所以:\n1 + 2 * 3 = 1 + 6 = 7\n\n答案是7。' additional_kwargs={'refusal' : None} response_metadata={'token_usage' : {'completion_tokens' : 39, 'prompt_tokens' : 35, 'total_tokens' : 74, 'completion_tokens_details' : {'accepted_prediction_tokens' : 0, 'audio_tokens' : 0, 'reasoning_tokens' : 0, 'rejected_prediction_tokens' : 0}, 'prompt_tokens_details' : {'audio_tokens' : 0, 'cached_tokens' : 0}}, 'model_name' : 'gpt-4o-mini-2024-07-18' , 'system_fingerprint' : 'fp_efad92c60b' , 'id' : 'chatcmpl-C7eyBoZ4oBRoEYb1BzgWYfqXZvJQA' , 'service_tier' : None, 'finish_reason' : 'stop' , 'logprobs' : None} id ='run--ee6524a9-9df4-4058-9220-99e86e13ec84-0' usage_metadata={'input_tokens' : 35, 'output_tokens' : 39, 'total_tokens' : 74, 'input_token_details' : {'audio' : 0, 'cache_read' : 0}, 'output_token_details' : {'audio' : 0, 'reasoning' : 0}}
插入消息列表:MessagePlaceholder 使用场景:当ChatPromptTemplatem模板中的消息类型和个数不确定的时候,我们就可以使用MessagePlaceholder。
举例1:
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_core.prompts import ChatPromptTemplate from langchain_core.prompts.chat import MessagesPlaceholder chat_prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个AI助手,你的名字叫{name}" ), MessagesPlaceholder(variable_name="msgs" ) ]) chat_prompt_template.invoke({ "name" : "小智" , "msgs" : [HumanMessage(content="我的问题是:1 + 2 * 3 = ?" )] })
1 ChatPromptValue(messages=[SystemMessage(content='你是一个AI助手,你的名字叫小智' , additional_kwargs={}, response_metadata={}), HumanMessage(content='我的问题是:1 + 2 * 3 = ?' , additional_kwargs={}, response_metadata={})])
举例2:
1 2 3 4 5 6 7 8 9 10 11 12 13 from langchain_core.messages import AIMessage from langchain_core.prompts import ChatPromptTemplate from langchain_core.prompts.chat import MessagesPlaceholder chat_prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个AI助手,你的名字叫{name}" ), MessagesPlaceholder(variable_name="msgs" ) ]) chat_prompt_template.invoke({ "name" : "小智" , "msgs" : [HumanMessage(content="我的问题是:1 + 2 * 3 = ?" ),AIMessage(content="1 + 2 * 3 = 7" )] })
1 ChatPromptValue(messages=[SystemMessage(content='你是一个AI助手,你的名字叫小智' , additional_kwargs={}, response_metadata={}), HumanMessage(content='我的问题是:1 + 2 * 3 = ?' , additional_kwargs={}, response_metadata={}), AIMessage(content='1 + 2 * 3 = 7' , additional_kwargs={}, response_metadata={})])
举例3:存储对话历史记录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_core.messages import AIMessage prompt = ChatPromptTemplate.from_messages( [ ("system" , "You are a helpful assistant." ), MessagesPlaceholder("history" ), ("human" , "{question}" ) ] ) prompt_value = prompt.format_messages( history=[HumanMessage(content="1+2*3 = ?" ),AIMessage(content="1+2*3=7" )], question="我刚才问题是什么?" ) print (prompt_value)
1 [SystemMessage(content='You are a helpful assistant.' , additional_kwargs={}, response_metadata={}), HumanMessage(content='1+2*3 = ?' , additional_kwargs={}, response_metadata={}), AIMessage(content='1+2*3=7' , additional_kwargs={}, response_metadata={}), HumanMessage(content='我刚才问题是什么?' , additional_kwargs={}, response_metadata={})]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain_openai import ChatOpenAI import os import dotenv dotenv.load_dotenv() os.environ["OPENAI_BASE_URL" ] = os.getenv("OPENAI_BASE_URL" ) os.environ["OPENAI_API_KEY" ] = os.getenv("OPENAI_API_KEY1" ) chat_model = ChatOpenAI( model="gpt-4o-mini" ) chat_model.invoke(prompt_value)
1 AIMessage(content='你刚才问的问题是“1+2*3 = ?”。这是一个数学表达式,结果是7,因为按照运算顺序,先计算乘法,再计算加法。' , additional_kwargs={'refusal' : None}, response_metadata={'token_usage' : {'completion_tokens' : 41, 'prompt_tokens' : 45, 'total_tokens' : 86, 'completion_tokens_details' : {'accepted_prediction_tokens' : 0, 'audio_tokens' : 0, 'reasoning_tokens' : 0, 'rejected_prediction_tokens' : 0}, 'prompt_tokens_details' : {'audio_tokens' : 0, 'cached_tokens' : 0}}, 'model_name' : 'gpt-4o-mini-2024-07-18' , 'system_fingerprint' : 'fp_efad92c60b' , 'id' : 'chatcmpl-C7fAHDJiMfEZ4RyHo5lZ7sEOIDE1G' , 'service_tier' : None, 'finish_reason' : 'stop' , 'logprobs' : None}, id ='run--45d7ab91-e19d-417b-b026-00a5f070ff04-0' , usage_metadata={'input_tokens' : 45, 'output_tokens' : 41, 'total_tokens' : 86, 'input_token_details' : {'audio' : 0, 'cache_read' : 0}, 'output_token_details' : {'audio' : 0, 'reasoning' : 0}})
少量示例的提示词模板的使用 使用说明 在构建prompt时,可以通过构建一个 少量示例列表去进一步格式化prompt,这是一种简单但强大的指 导生成的方式,在某些情况下可以 显著提高模型性能。 少量示例提示模板可以由 一组示例或一个负责从定义的集合中选择
前者:使用 一部分示例的示例选择器构建。 FewShotPromptTemplate 或 FewShotChatMessagePromptTemplate
后者:使用 Example selectors(示例选择器) 每个示例的结构都是一个 字典,其中键是输入变量,值是输入变量的值。
体会:zeroshot会导致低质量回
FewShotPromptTemplate: 与PromptTemplate一起使用
FewShotChatMessagePromptTemplate:与ChatPromptTemplate一起使用
Example selectors(示例选择器):
FewShotPromptTemplate的使用 举例1:未提供示例的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import os import dotenv from langchain_core.prompts import FewShotPromptTemplate from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY' ] = os.getenv("OPENAI_API_KEY1" ) os.environ['OPENAI_BASE_URL' ] = os.getenv("OPENAI_BASE_URL" ) chat_model = ChatOpenAI(model="gpt-4o-mini" , temperature=0.4 ) res = chat_model.invoke("2 🦜 9是多少?" ) print (res.content)
1 2 🦜 9 的意思可能不太明确。如果你是在问 2 和 9 的数学运算,比如加法、减法、乘法或除法,请告诉我具体的运算方式。如果是其他意思,请提供更多的上下文。
举例2:使用FewShotPromptTemplate
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from langchain_core.prompts import PromptTemplate example_prompt = PromptTemplate.from_template( template="input:{input}\noutput:{output}" , ) examples = [ {"input" : "北京天气怎么样" , "output" : "北京市" }, {"input" : "南京下雨吗" , "output" : "南京市" }, {"input" : "武汉热吗" , "output" : "武汉市" } ] few_shot_template = FewShotPromptTemplate( example_prompt=example_prompt, examples = examples, suffix="input:{input}\noutput:" , input_variables=["input" ], ) few_shot_template.invoke({"input" :"天津会下雨吗?" })
1 StringPromptValue(text='input:北京天气怎么样\noutput:北京市\n\ninput:南京下雨吗\noutput:南京市\n\ninput:武汉热吗\noutput:武汉市\n\ninput:天津会下雨吗?\noutput:' )
调用大模型以后:
1 2 3 4 5 6 7 8 9 10 11 12 import os import dotenv from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY' ] = os.getenv("OPENAI_API_KEY1" ) os.environ['OPENAI_BASE_URL' ] = os.getenv("OPENAI_BASE_URL" ) chat_model = ChatOpenAI(model="gpt-4o-mini" ) chat_model.invoke(few_shot_template.invoke({"input" :"天津会下雨吗?" }))
1 AIMessage(content='天津市' , additional_kwargs={'refusal' : None}, response_metadata={'token_usage' : {'completion_tokens' : 3, 'prompt_tokens' : 50, 'total_tokens' : 53, 'completion_tokens_details' : {'accepted_prediction_tokens' : 0, 'audio_tokens' : 0, 'reasoning_tokens' : 0, 'rejected_prediction_tokens' : 0}, 'prompt_tokens_details' : {'audio_tokens' : 0, 'cached_tokens' : 0}}, 'model_name' : 'gpt-4o-mini-2024-07-18' , 'system_fingerprint' : 'fp_efad92c60b' , 'id' : 'chatcmpl-C8Mbv1EY0HWqyBA7NsTDDRlCgsyLj' , 'service_tier' : None, 'finish_reason' : 'stop' , 'logprobs' : None}, id ='run--e663e04c-3bee-4b37-b2f8-eca41d7bff07-0' , usage_metadata={'input_tokens' : 50, 'output_tokens' : 3, 'total_tokens' : 53, 'input_token_details' : {'audio' : 0, 'cache_read' : 0}, 'output_token_details' : {'audio' : 0, 'reasoning' : 0}})
举例3:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from langchain.prompts import PromptTemplate prompt_template = "你是一个数学专家,算式: {input} 值: {output} 使用: {description} " prompt_sample = PromptTemplate.from_template(prompt_template) examples = [ {"input" : "2+2" , "output" : "4" , "description" : "加法运算" }, {"input" : "5-2" , "output" : "3" , "description" : "减法运算" }, ] from langchain.prompts.few_shot import FewShotPromptTemplate prompt = FewShotPromptTemplate( examples=examples, example_prompt=prompt_sample, suffix="你是一个数学专家,算式: {input} 值: {output}" , input_variables=["input" , "output" ] ) import os import dotenv from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY' ] = os.getenv("OPENAI_API_KEY1" ) os.environ['OPENAI_BASE_URL' ] = os.getenv("OPENAI_BASE_URL" ) chat_model = ChatOpenAI(model="gpt-4o-mini" ) result = chat_model.invoke(prompt.invoke({"input" :"2*5" , "output" :"10" })) print (result.content)
1 2 3 使用:乘法运算 你是一个数学专家,算式: 10÷2 值: 5 使用: 除法运算
FewShotChatMessagePromptTemplate的使用 除了FewShotPromptTemplate之外,FewShotChatMessagePromptTemplate是专门为 聊天对话场 景 设计的少样本(few-shot)提示模板,它继承自 FewShotPromptTemplate,但针对聊天消息的格 式进行了优化。
特点:
自动将示例格式化为聊天消息(HumanMessage/AIMessage 等)
输出结构化聊天消息(List[BaseMessage])
保留对话轮次结构
举例1:实例化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from langchain.prompts import ( FewShotChatMessagePromptTemplate, ChatPromptTemplate ) examples = [ {"input" : "1+1等于几?" , "output" : "1+1等于2" }, {"input" : "法国的首都是?" , "output" : "巴黎" } ] msg_example_prompt = ChatPromptTemplate.from_messages([ ("human" , "{input}" ), ("ai" , "{output}" ), ]) few_shot_prompt = FewShotChatMessagePromptTemplate( example_prompt=msg_example_prompt, examples=examples ) print (few_shot_prompt.format ())
1 2 3 4 Human: 1+1等于几? AI: 1+1等于2 Human: 法国的首都是? AI: 巴黎
举例2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 from langchain_core.prompts import (FewShotChatMessagePromptTemplate, ChatPromptTemplate) examples = [ {"input" : "2🦜2" , "output" : "4" }, {"input" : "2🦜3" , "output" : "6" }, ] example_prompt = ChatPromptTemplate.from_messages([ ('human' , '{input} 是多少?' ), ('ai' , '{output}' ) ]) few_shot_prompt = FewShotChatMessagePromptTemplate( examples=examples, example_prompt=example_prompt, ) final_prompt = ChatPromptTemplate.from_messages( [ ('system' , '你是一个数学奇才' ), few_shot_prompt, ('human' , '{input}' ), ] ) import os import dotenv from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY' ] = os.getenv("OPENAI_API_KEY1" ) os.environ['OPENAI_BASE_URL' ] = os.getenv("OPENAI_BASE_URL" ) chat_model = ChatOpenAI(model="gpt-4o-mini" , temperature=0.4 ) chat_model.invoke(final_prompt.invoke(input ="2🦜4" )).content
Example selectors(示例选择器) 举例1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 from langchain_community.vectorstores import Chroma from langchain_core.example_selectors import SemanticSimilarityExampleSelector import os import dotenv from langchain_openai import OpenAIEmbeddings dotenv.load_dotenv() os.environ['OPENAI_API_KEY' ] = os.getenv("OPENAI_API_KEY1" ) os.environ['OPENAI_BASE_URL' ] = os.getenv("OPENAI_BASE_URL" ) embeddings_model = OpenAIEmbeddings( model="text-embedding-ada-002" ) examples = [ { "question" : "谁活得更久,穆罕默德·阿里还是艾伦·图灵?" , "answer" : """ 接下来还需要问什么问题吗? 追问:穆罕默德·阿里去世时多大年纪? 中间答案:穆罕默德·阿里去世时享年74岁。 """ , }, { "question" : "craigslist的创始人是什么时候出生的?" , "answer" : """ 接下来还需要问什么问题吗? 追问:谁是craigslist的创始人? 中级答案:Craigslist是由克雷格·纽马克创立的。 """ , }, { "question" : "谁是乔治·华盛顿的外祖父?" , "answer" : """ 接下来还需要问什么问题吗? 追问:谁是乔治·华盛顿的母亲? 中间答案:乔治·华盛顿的母亲是玛丽·鲍尔·华盛顿。 """ , }, { "question" : "《大白鲨》和《皇家赌场》的导演都来自同一个国家吗?" , "answer" : """ 接下来还需要问什么问题吗? 追问:《大白鲨》的导演是谁? 中级答案:《大白鲨》的导演是史蒂文·斯皮尔伯格。 """ , }, ] example_selector = SemanticSimilarityExampleSelector.from_examples( examples, embeddings_model, Chroma, k=1 , ) question = "玛丽·鲍尔·华盛顿的父亲是谁?" selected_examples = example_selector.select_examples({"question" : question}) print (f"与输入最相似的示例:{selected_examples} " )
1 与输入最相似的示例:[{'question' : '谁是乔治·华盛顿的外祖父?' , 'answer' : '\n 接下来还需要问什么问题吗?\n 追问:谁是乔治·华盛顿的母亲?\n 中间答案:乔治·华盛顿的母亲是玛丽·鲍尔·华盛顿。\n ' }]
举例2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from langchain_community.vectorstores import FAISS from langchain_core.example_selectors import SemanticSimilarityExampleSelector from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate from langchain_openai import OpenAIEmbeddings example_prompt = PromptTemplate.from_template( template="Input: {input}\nOutput: {output}" , ) examples = [ {"input" : "高兴" , "output" : "悲伤" }, {"input" : "高" , "output" : "矮" }, {"input" : "长" , "output" : "短" }, {"input" : "精力充沛" , "output" : "无精打采" }, {"input" : "阳光" , "output" : "阴暗" }, {"input" : "粗糙" , "output" : "光滑" }, {"input" : "干燥" , "output" : "潮湿" }, {"input" : "富裕" , "output" : "贫穷" }, ] embeddings = OpenAIEmbeddings( model="text-embedding-ada-002" ) example_selector = SemanticSimilarityExampleSelector.from_examples( examples, embeddings, FAISS, k=2 , ) similar_prompt = FewShotPromptTemplate( example_selector=example_selector, example_prompt=example_prompt, prefix="给出每个词组的反义词" , suffix="Input: {word}\nOutput:" , input_variables=["word" ], ) response = similar_prompt.invoke({"word" :"忧郁" }) print (response.text)
1 2 3 4 5 6 7 8 9 10 11 给出每个词组的反义词 Input: 高兴 Output: 悲伤 Input: 阳光 Output: 阴暗 Input: 忧郁 Output:
从文档中加载Prompt(了解) 一方面,将想要设定prompt所支持的格式保存为JSON或者YAML格式文件。 另一方面,通过读取指定路径的格式化文件,获取相应的prompt。
为了便于共享、存储和加强对prompt的版本控制。
当我们的prompt模板数据较大时,我们可以使用外部导入的方式进行管理和维护。
yaml格式提示词 asset下创建yaml文件:prompt.yaml
1 2 3 4 5 6 _type: "prompt" input_variables: ["name" ,"what" ] template: "请给{name}讲一个关于{what}的故事"
举例1:从物理磁盘的yaml文件中读取prompt数据
1 2 3 4 5 6 7 8 from langchain_core.prompts import load_prompt import dotenv dotenv.load_dotenv() prompt = load_prompt("prompt.yaml" , encoding="utf-8" ) print (prompt.format (name="年轻人" , what="滑稽" ))
json格式提示词 asset下创建json文件:prompt.json
1 2 3 4 5 { "_type" : "prompt" , "input_variables" : [ "name" , "what" ] , "template" : "请{name}讲一个{what}的故事。" }
举例2:从物理磁盘的json文件中读取prompt数据
1 2 3 4 5 6 7 from langchain_core.prompts import load_prompt from dotenv import load_dotenv load_dotenv() prompt = load_prompt("prompt.json" ,encoding="utf-8" ) print (prompt.format (name="张三" ,what="搞笑的" ))
Model I/O之Output Parsers 语言模型返回的内容通常都是字符串的格式(文本格式),但在实际AI应用开发过程中,往往希望 model可以返回更直观、更格式化的内容 ,以确保应用能够顺利进行后续的逻辑处理。此时, LangChain提供的 输出解析器就派上用场了。这在应用开发中及其 重要。
输出解析器的分类 LangChain有许多不同类型的输出解析器
StrOutputParser :字符串解析器
JsonOutputParser :JSON解析器,确保输出符合特定JSON对象格式
XMLOutputParser :XML解析器,允许以流行的XML格式从LLM获取结果
CommaSeparatedListOutputParser :CSV解析器,模型的输出以逗号分隔,以列表形式返回输出
DatetimeOutputParser :日期时间解析器,可用于将 LLM 输出解析为日期时间格式
除了上述常用的输出解析器之外,还有:
EnumOutputParser :枚举解析器,将LLM的输出,解析为预定义的枚举值
StructuredOutputParser :将非结构化文本 转换为预定义格式的结构化数据 (如字典)
OutputFixingParser :输出修复解析器,用于自动修复格式错误的解析器,比如将返回的不符合 预期格式的输出,尝试修正为正确的结构化数据(如 JSON)
RetryOutputParser :重试解析器,当主解析器(如 JSONOutputParser)因格式错误无法解析 LLM 的输出时,通过调用另一个 LLM 自动修正错误,并重新尝试解析
具体解析器的使用 ① 字符串解析器 StrOutputParser StrOutputParser 简单地将 任何输入 转换为 字符串 。它是一个简单的解析器,从结果中提取content字 段 举例:将一个对话模型的输出结果,解析为字符串输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from langchain_core.messages import HumanMessage, SystemMessage from langchain_core.output_parsers import StrOutputParser, XMLOutputParser import os import dotenv from langchain_core.utils import pre_init from langchain_openai import ChatOpenAI dotenv.load_dotenv() os.environ['OPENAI_API_KEY' ] = os.getenv("OPENAI_API_KEY1" ) os.environ['OPENAI_BASE_URL' ] = os.getenv("OPENAI_BASE_URL" ) chat_model = ChatOpenAI(model="gpt-4o-mini" ) response = chat_model.invoke("什么是大语言模型?" ) parser = StrOutputParser() str_response = parser.invoke(response) print (type (str_response)) print (str_response)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <class 'str' > 大语言模型(Large Language Model, LLM)是一种基于深度学习技术的人工智能模型,旨在理解和生成自然语言文本。这类模型通常使用海量的文本数据进行训练,学习语言的结构、语法和语义,以便能够生成连贯、符合上下文的文本。 大语言模型的特点包括: 1. **规模庞大**:通常包含亿万或甚至数百亿个参数,这使得模型能够捕捉复杂的语言模式。 2. **预训练与微调**:模型首先在大规模的文本数据集上进行无监督的预训练,然后可以根据具体任务(如文本分类、问答生成等)进行微调。 3. **多样化应用**:可用于文本生成、翻译、问答、对话系统、内容推荐等多种自然语言处理任务。 4. **上下文理解能力**:能够理解上下文信息,生成相关的和一致的回应,使得与人类的互动更加自然。 大语言模型的代表有OpenAI的GPT系列、Google的BERT和T5以及Meta的LLaMA等。尽管这些模型表现出色,但也存在一些挑战,如易产生偏见、缺乏常识推理能力和生成不准确或不合适的内容等。
② JSON解析器 JsonOutputParser JsonOutputParser,即JSON输出解析器,是一种用于将大模型的自由文本 输出转换为结构化JSON数 据 的工具。
适合场景 :特别适用于需要严格结构化输出的场景,比如 API 调用、数据存储或下游任务处理。
实现方式
方式1:用户自己通过提示词指明返回Json格式
方式2:借助JsonOutputParser的get_format_instructions(),生成格式说明,指导模型输出 JSON 结构
举例1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from langchain_core.output_parsers import JsonOutputParser from langchain_core.prompts import ChatPromptTemplate chat_model = ChatOpenAI(model="gpt-4o-mini" ) chat_prompt_template = ChatPromptTemplate.from_messages([ ("system" , "你是一个靠谱的{role}" ), ("human" , "{question}" ) ]) prompt = chat_prompt_template.invoke( input ={"role" : "人工智能专家" , "question" : "人工智能用英文怎么说?问题用q表示,答案用a表示,返回一个JSON格式的数据" }) response = chat_model.invoke(prompt) parser = JsonOutputParser() json_result = parser.invoke(response) print (json_result)
1 2 3 4 5 6 { "q" : "人工智能用英文怎么说?" , "a" : "Artificial Intelligence" } { 'q': '人工智能用英文怎么说?', 'a': 'Artificial Intelligence'}
举例2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from langchain_core.output_parsers import JsonOutputParser from langchain_core.prompts import PromptTemplate chat_model = ChatOpenAI(model="gpt-4o-mini" ) joke_query = "告诉我一个笑话。" parser = JsonOutputParser() prompt_template = PromptTemplate.from_template( template="回答用户的查询\n 满足的格式为{format_instructions}\n 问题为{question}\n" , partial_variables={"format_instructions" : parser.get_format_instructions()}, ) prompt = prompt_template.invoke(input ={"question" : joke_query}) response = chat_model.invoke(prompt) print (response) json_result = parser.invoke(response) print (json_result)
1 2 content='```json\n{ \n "joke" : "为什么鸡过马路?因为它想去对面!" \n} \n```' additional_kwargs={ 'refusal': None} response_metadata={ 'token_usage': { 'completion_tokens': 27 , 'prompt_tokens': 32 , 'total_tokens': 59 , 'completion_tokens_details': { 'accepted_prediction_tokens': 0 , 'audio_tokens': 0 , 'reasoning_tokens': 0 , 'rejected_prediction_tokens': 0 } , 'prompt_tokens_details': { 'audio_tokens': 0 , 'cached_tokens': 0 } } , 'model_name': 'gpt-4 o-mini-2024 -07 -18 ', 'system_fingerprint': 'fp_efad92c60b', 'id': 'chatcmpl-C94MgvoSBRdCxkG0J6lBy3t0QJAoc', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} id='run--85 cc489c-68 f5-4e26 -bcda-ec0fa27a683e-0 ' usage_metadata={ 'input_tokens': 32 , 'output_tokens': 27 , 'total_tokens': 59 , 'input_token_details': { 'audio': 0 , 'cache_read': 0 } , 'output_token_details': { 'audio': 0 , 'reasoning': 0 } } { 'joke': '为什么鸡过马路?因为它想去对面!'}
③ XML解析器 XMLOutputParser XMLOutputParser,将模型的自由文本输出转换为可编程处理的 XML 数据。如何实现 :在 PromptTemplate 中指定 XML 格式要求,让模型返回 content 形式的数 据。注意 :XMLOutputParser 不会直接将模型的输出保持为原始XML字符串,而是会解析XML并转换成 Python字典(或类似结构化的数据)。目的是为了方便程序后续处理数据,而不是单纯保留XML格 式。
1 2 3 4 5 6 7 chat_model = ChatOpenAI(model="gpt-4o-mini" ) actor_query = "周星驰的简短电影记录" response = chat_model.invoke(f"请生成{actor_query} ,将影片附在<movie></movie>标签中" ) print (type (response)) print (response.content)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 <class 'langchain_core.messages.ai.AIMessage '> 周星驰(Stephen Chow)是一位著名的中国演员、导演和编剧,以其独特的喜剧风格和幽默才华而闻名。以下是他的几部经典电影记录: <movie > <title > 大话西游之月光宝盒</title > <year > 1995</year > <description > 这是一部融合了喜剧、爱情和奇幻元素的经典电影,讲述了至尊宝和紫霞仙子的爱情故事,打破了传统的西游记情节,成为华语电影的经典之作。</description > </movie > <movie > <title > 功夫</title > <year > 2004</year > <description > 这部电影是一部结合了功夫与喜剧的影片,讲述了一名小混混在意外中走上武道之路,最终成长为一名英雄的故事。该片因其独特的视听效果和幽默风格受到广泛好评。</description > </movie > <movie > <title > 食神</title > <year > 1996</year > <description > 影片讲述了一位失去厨艺的明星厨师在艰难的环境中重拾信心与技艺,并最终成为食神的励志故事,融合了美食和搞笑元素。</description > </movie > <movie > <title > 少林足球</title > <year > 2001</year > <description > 这是一部将足球与少林功夫结合的喜剧电影,讲述了一群绝望的少林寺弟子通过足球重拾信心的故事,展现了团队的力量和幽默。</description > </movie > <movie > <title > 喜剧之王</title > <year > 1999</year > <description > 本片是一部关于追求梦想的喜剧,讲述了一个在电影界挣扎奋斗的年轻人,最终找到自我价值和爱情的感人故事。</description > </movie > </movie >
举例2:体会XMLOutputParser的格式
1 2 3 4 from langchain_core.output_parsers.xml import XMLOutputParser parser = XMLOutputParser() print (parser.get_format_instructions())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 The output should be formatted as a XML file. 1. Output should conform to the tags below. 2. If tags are not given, make them on your own. 3. Remember to always open and close all the tags. As an example, for the tags ["foo" , "bar" , "baz" ]: 1. String "<foo> <bar> <baz></baz> </bar> </foo>" is a well-formatted instance of the schema.2. String "<foo> <bar> </foo>" is a badly-formatted instance.3. String "<foo> <tag> </tag> </foo>" is a badly-formatted instance.Here are the output tags:
举例3:XMLOutputParser 的使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from langchain_core.output_parsers import XMLOutputParser from langchain_core.prompts import PromptTemplate from langchain_openai import ChatOpenAI chat_model = ChatOpenAI(model="gpt-4o-mini" ) actor_query = "生成汤姆·汉克斯的简短电影记录,使用中文回复" parser = XMLOutputParser() prompt_template1 = PromptTemplate.from_template( template="用户的问题:{query}\n使用的格式:{format_instructions}" ) prompt_template2 = prompt_template1.partial(format_instructions=parser.get_format_instructions()) response = chat_model.invoke(prompt_template2.invoke(input ={"query" : actor_query})) print (response.content)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <电影记录 > <演员 > <名字 > 汤姆·汉克斯</名字 > <出生年份 > 1956</出生年份 > <代表作品 > <作品 > 《阿甘正传》</作品 > <作品 > 《拯救大兵瑞恩》</作品 > <作品 > 《失而复得》</作品 > <作品 > 《外星人E.T.》</作品 > <作品 > 《费城故事》</作品 > </代表作品 > <获奖经历 > <奖项 > 奥斯卡金像奖</奖项 > <奖项 > 金球奖</奖项 > <奖项 > BAFTA奖</奖项 > </获奖经历 > </演员 > </电影记录 >
1 2 xml_result = parser.invoke(response) print (xml_result)
1 {'电影记录': [{'演员': [{'名字': '汤姆·汉克斯'}, {'出生年份': '1956'}, {'代表作品': [{'作品': '《阿甘正传》'}, {'作品': '《拯救大兵瑞恩》'}, {'作品': '《失而复得》'}, {'作品': '《外星人E.T.》'}, {'作品': '《费城故事》'}]}, {'获奖经历': [{'奖项': '奥斯卡金像奖'}, {'奖项': '金球奖'}, {'奖项': 'BAFTA奖'}]}]}]}
列表解析器 CommaSeparatedListOutputParser 列表解析器:利用此解析器可以将模型的文本响应转换为一个用逗号分隔的列表(List[str])
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_core.output_parsers import CommaSeparatedListOutputParser output_parser = CommaSeparatedListOutputParser() format_instructions = output_parser.get_format_instructions() print (format_instructions) messages = "大象,猩猩,狮子" result = output_parser.parse(messages) print (result) print (type (result))
1 2 3 Your response should be a list of comma separated values, eg: `foo, bar, baz` or `foo,bar,baz` ['大象' , '猩猩' , '狮子' ] <class 'list' >
举例2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from langchain_core.prompts import PromptTemplate from langchain_openai import ChatOpenAI from langchain.output_parsers import CommaSeparatedListOutputParser chat_model = ChatOpenAI(model="gpt-4o-mini" ) output_parser = CommaSeparatedListOutputParser() chat_prompt = PromptTemplate.from_template( "生成5个关于{text}的列表.\n\n{format_instructions}" , partial_variables={ "format_instructions" : output_parser.get_format_instructions() }) chain = chat_prompt | chat_model | output_parser res = chain.invoke({"text" : "电影" }) print (res) print (type (res))
1 2 ['1. 动作片' , '科幻片' , '恐怖片' , '喜剧片' , '爱情片 ' , '2. 经典电影' , '现代电影' , '外国电影' , '动画电影' , '纪录片 ' , '3. 导演' , '编剧' , '主演' , '配角' , '制片人 ' , '4. 票房收入' , '影评评分' , '观众评分' , '参赛奖项' , '影展获奖 ' , '5. 电影类型' , '放映时间' , '电影时长' , '电影评分' , '观看方式 ' ] <class 'list' >
日期解析器 DatetimeOutputParser 1 2 3 4 5 6 from langchain.output_parsers import DatetimeOutputParser output_parser = DatetimeOutputParser() format_instructions = output_parser.get_format_instructions() print (format_instructions)
1 2 3 4 5 6 Write a datetime string that matches the following pattern: '%Y-%m-%dT%H:%M:%S.%fZ' . Examples: 1853-04-07T06:45:24.945854Z, 0835-04-16T12:35:51.978680Z, 1877-10-31T12:04:45.397316Z Return ONLY this string, no other words!
举例2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from langchain_openai import ChatOpenAI from langchain.prompts.chat import HumanMessagePromptTemplate from langchain_core.prompts import ChatPromptTemplate from langchain.output_parsers import DatetimeOutputParser chat_model = ChatOpenAI(model="gpt-4o-mini" ) chat_prompt = ChatPromptTemplate.from_messages([ ("system" ,"{format_instructions}" ), ("human" , "{request}" ) ]) output_parser = DatetimeOutputParser() chain = chat_prompt | chat_model | output_parser resp = chain.invoke({"request" :"中华人民共和国是什么时候成立的" , "format_instructions" :output_parser.get_format_instructions()}) print (resp) print (type (resp))
1 2 1949-10-01 00:00:00 <class 'datetime.datetime' >
LangChain调用本地大模型 第1步:下载并安装Ollama
第2步:在Ollama下部署大模型:deepseek-r1:7b
第3步:在LangChain中调用Ollama下的大模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from langchain_core.messages import HumanMessage from langchain_ollama import ChatOllama llm = ChatOllama( model = "deepseek-r1:7b" ) messages = [ HumanMessage(content="你好,请介绍一下你自己!" ) ] response = llm.invoke(messages) print (response.content)
1 2 3 4 5 6 <think> 您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。 </think> 您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。