RAG介绍 RAG(Retrieval Augmented Generation)
RAG(检索增强生成)是一种结合语言模型与信息检索技术的技术,通过从外部知识源检索相关背景信息来提升文本生成或回答问题的准确性和质量。
1.LLM的缺陷 1.LLM的知识不是实时的,不具备知识更新
2.为什么会用到RAG 1.提高准确性:通过检索相关的信息,RAG可以提高生成文本的准确性。
3.RAG概念 RAG(Retrieval Augmented Generation)顾名思义,通过检索外部数据,增强大模型的生成效果。
4.RAG vs Fine-tuning
RAG(检索增强生成)是把内部的文档数据先进行embedding,借助检索先获得大致的知识范围答案,再结合prompt给到LLM,让 LLM生成最终的答案)100%
Fine-tuning(微调)是用一定量的数据集对LLiv选行局部参数的调整,以期望LLM更加理解我们的业务逻辑,有更好的zero-shot能力。
5.RAG工作流 RAG论文:https://arxiv.org/pdf/2312.10997
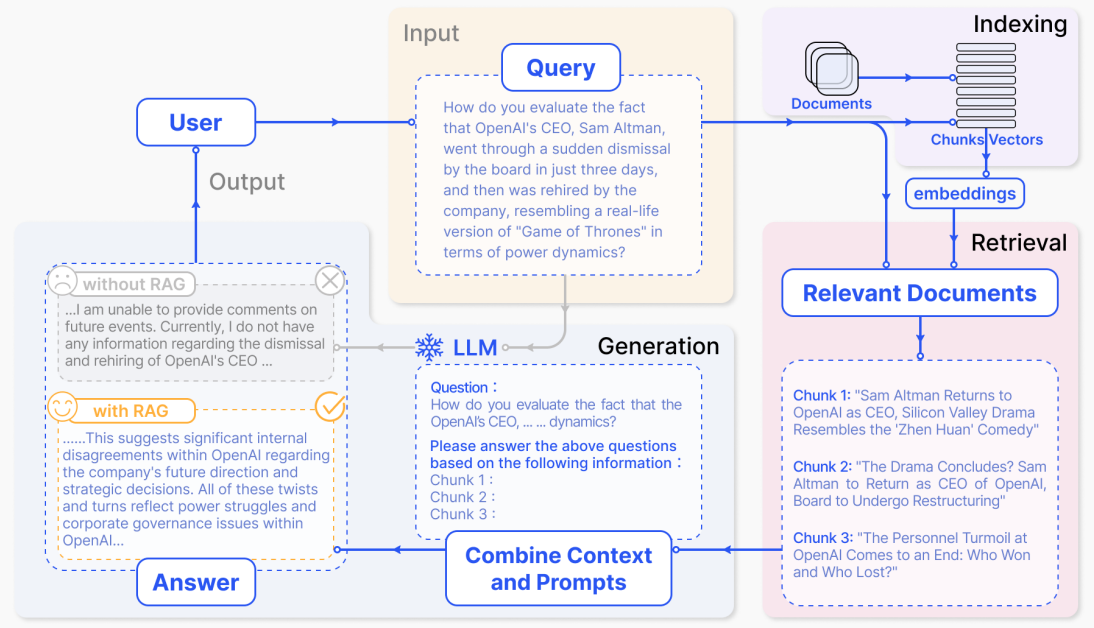
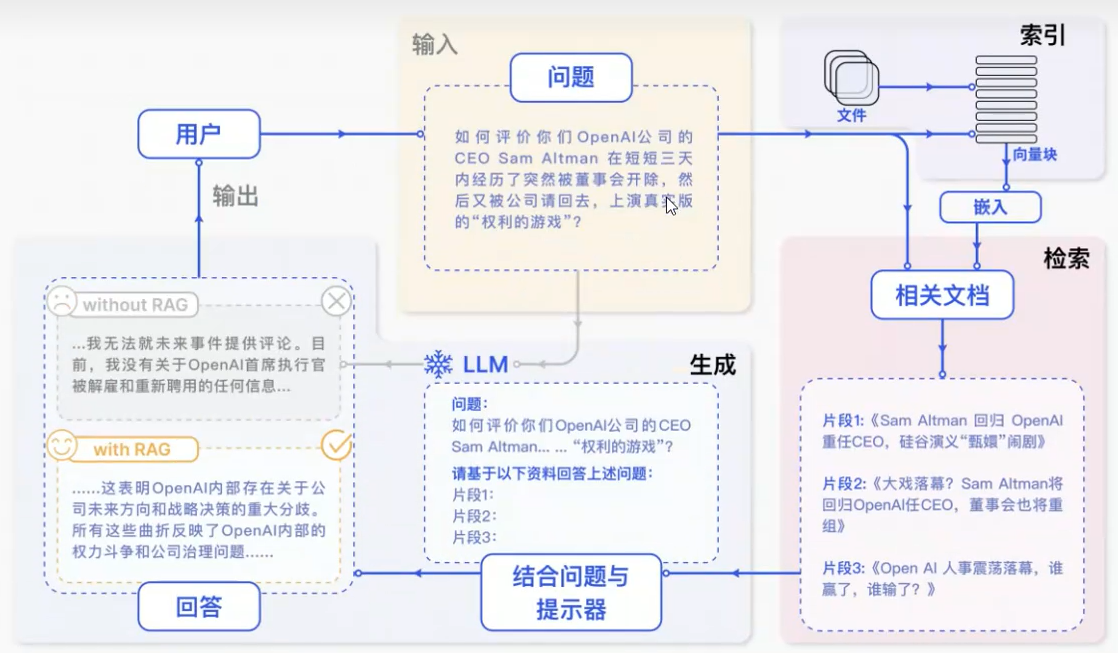
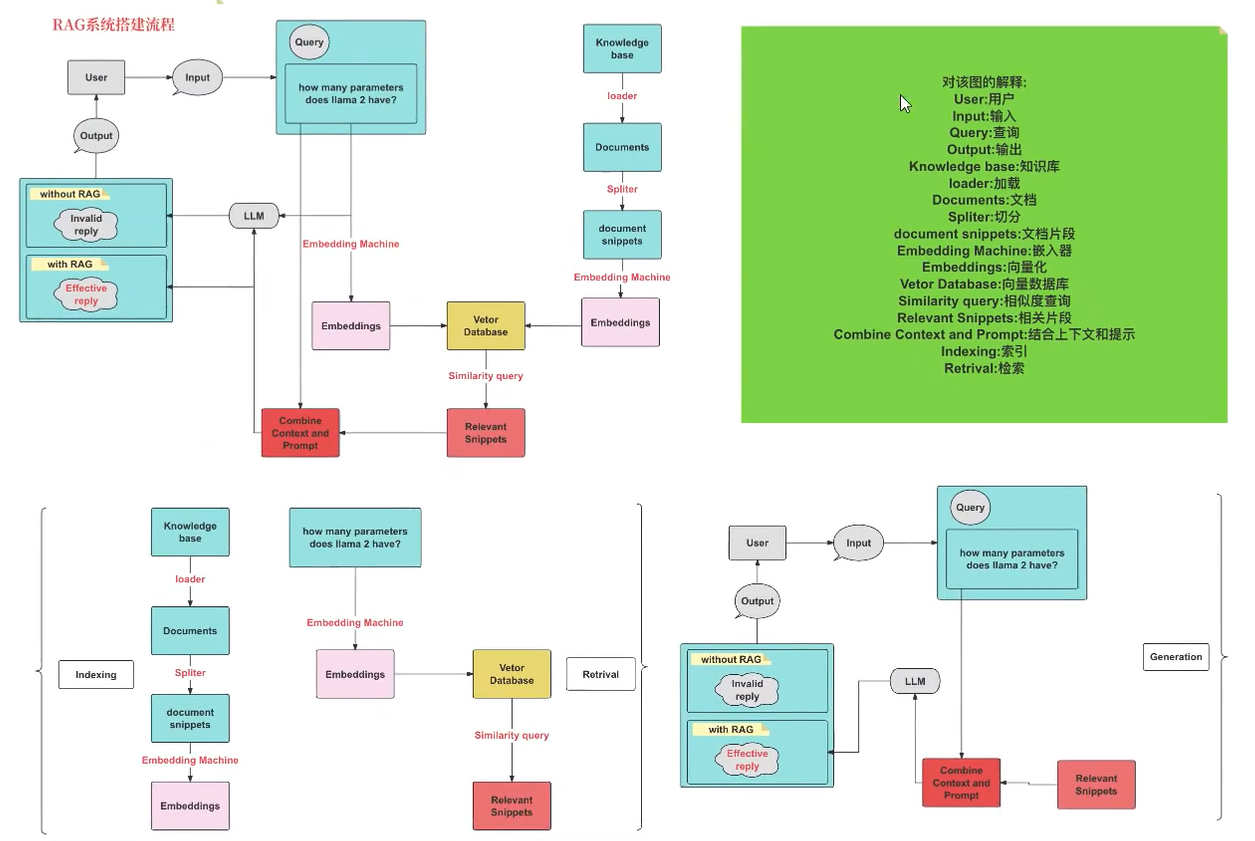
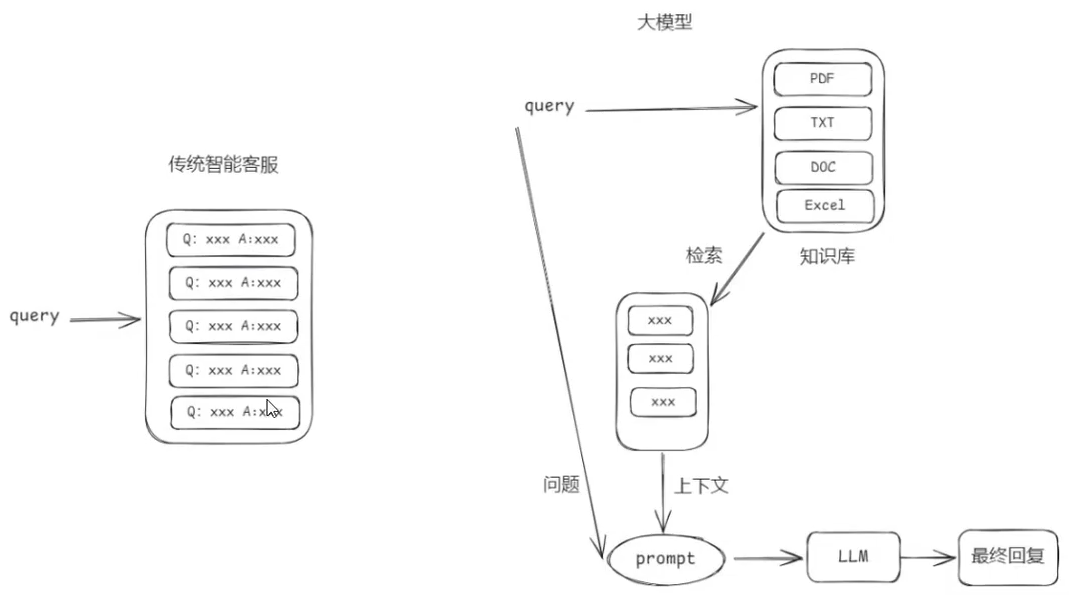
RAG系统的搭建流程 具体流程如下:
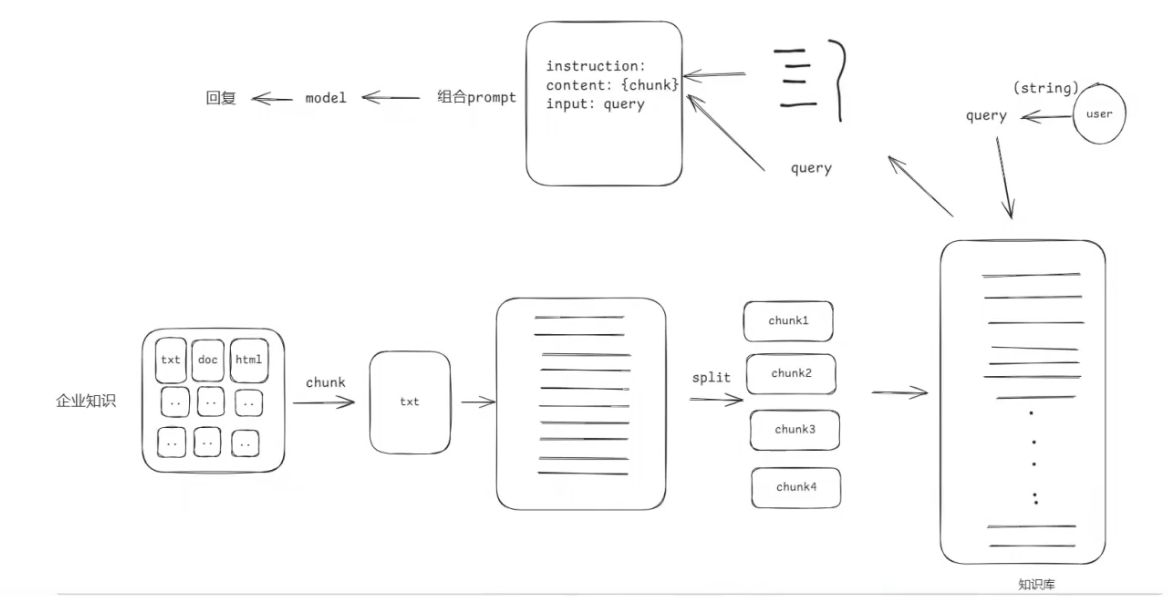
索引(Indexing):索引首先清理和提取各种格式的原始数据,如PDF、HTML、Word和Markdown,然后将其转换为统一的纯文本格式。为了适应语言模型的上下文限制,文本被分割成更小的、可消化的块(chuk)。 然后使用嵌入模型将块编码成向量表示 ,并存储在向量数据库中。这一步对于在随后的检索阶段实现高效的相似性搜索至关重要。知识库分割成chunks,并将chunks向量化至向量库中。
检索(Retrieval):在收到用户查询(Query)后,RAG系统采用与索引阶段 相同的编码模型 将查询转换为向量表示,然后计算索引语料库中查询向量与块向量的相似性得分。该系统优先级和检索最高k(Top-K)块,显示最大的相似性查询。
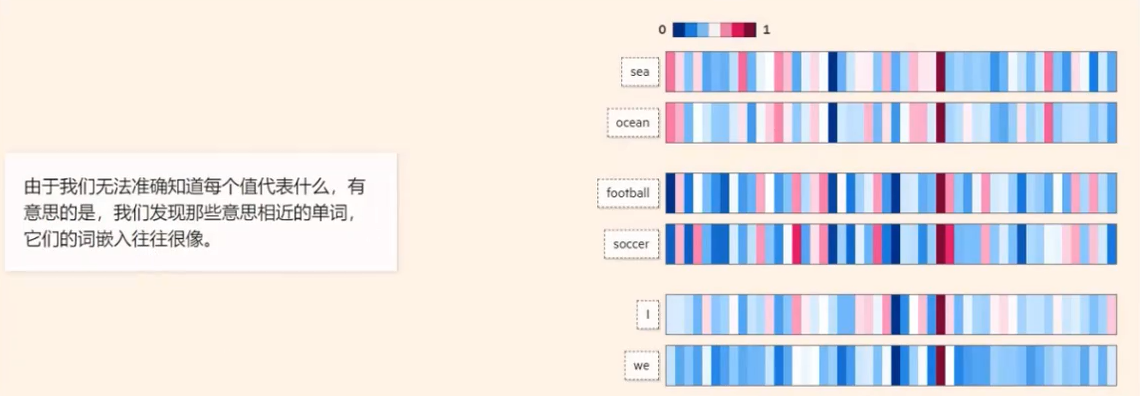
将文本转成一组浮点数:每个下标ⅰ,对应一个维度
整个数组对应一个n维空间的一个点,即文本向量又叫Embeddings
向量之间可以计算距离,距离远近对应语义相似度大小州
RAG具体实现流程:
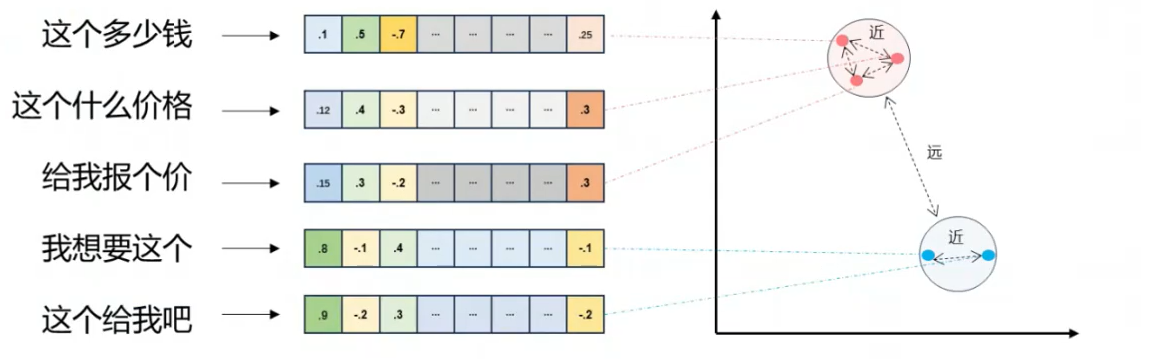
RAG核心 1.传统VS大模型 智能客服系统在没有大模型之前我们也是可以设计完成的只是实现的效果没有大模型那么好。下面是两则设计的原理
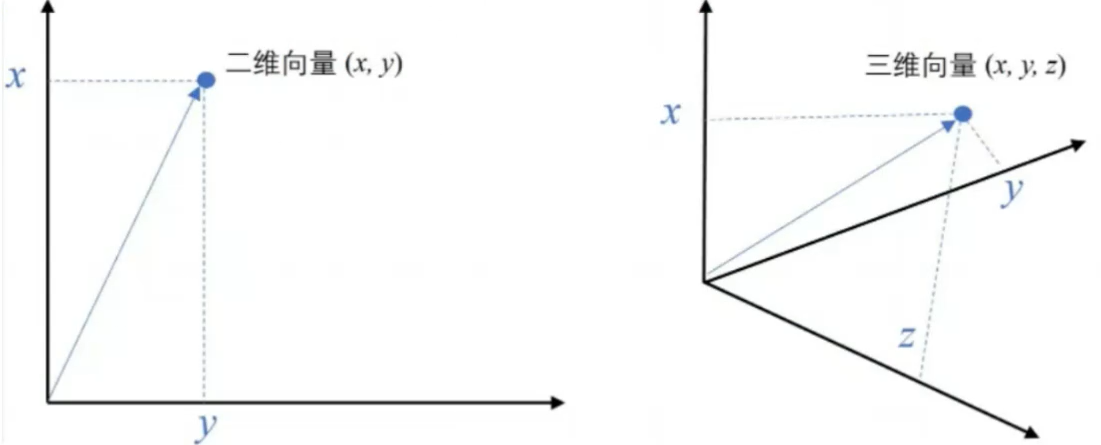
2.向量与Embeddings的定义 在数学中,向量(也称为欧几里得向量、几何向量),指具有大小(magnitude)和方向的量。它可以形象化地表示为带箭头的线段。箭头所指:代表向量的方向;线段长度:代表向量的大小。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from openai import OpenAI import openai from dotenv import load_dotenv load_dotenv() import os openai.api_key = 'your openai api-key' client = OpenAI(api_key=openai.api_key) def get_embeddings (texts,model="text-embedding-3-large" ): data = client.embeddings.create(input =texts,model=model).data return [x.embedding for x in data] test_query=["大模型" ] vec = get_embeddings(test_query) print (vec) print (vec[0 ]) print (len (vec[0 ]))
相似度计算 距离越短相似度越高。
文档的加载与分隔 基于文档的LLM回复系统搭建
把文本切分成chunks 我们把文本切分成chunks的方式有很多种:
按照句子来切分 1 2 3 4 5 6 7 8 9 10 import re text="自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。LP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。" sentences=re.split(r'(。|?|!|\...\...)' ,text) chunks = [sentence + (punctuation if punctuation else '' )for sentence,punctuation in zip (sentences[::2 ],sentences[1 ::2 ])] for i,chunk in enumerate (chunks): print (f"块{i+1 } :{len (chunk)} :{chunk} " )
输出结果:
1 2 3 4 5 6 7 块1:55:自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。 块2:21:在这个领域,机器学习发挥着至关重要的作用。 块3:30:利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。 块4:36:从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。 块5:33:随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。 块6:46:如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。 块7:40:LP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。
按照固定字符来切分 1 2 3 4 5 6 7 8 9 10 import re text="自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。LP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。" def split_by_fixed_char_count (text,count ): return [text[i:i+count]for i in range (0 ,len (text),count)] chunks = split_by_fixed_char_count(text,100 ) for i,chunk in enumerate (chunks): print (f"块{i+1 } :{len (chunk)} :{chunk} " )
结果:
1 2 3 块1:100:自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所 块2:100:理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理 块3:61:解任务,如问答系统、语音识别和对话系统等。LP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。
按照固定字符+滑动窗口 1 2 3 4 5 6 7 8 9 10 11 import re text="自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。LP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。" def sliding_window_chunks (text,chunk_size,stride ): return [text[i:i + chunk_size] for i in range (0 ,len (text),stride)] chunks = sliding_window_chunks(text,100 ,50 ) for i,chunk in enumerate (chunks): print (f"块{i+1 } :{len (chunk)} :{chunk} " )
结果:
1 2 3 4 5 6 块1:100:自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所 块2:100:言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术 块3:100:理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理 块4:100:的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。LP的研究推进不仅优化了人机交流,也对提升机器的自主性和智 块5:61:解任务,如问答系统、语音识别和对话系统等。LP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。 块6:11:能水平起到了关键作用。
递归方法 通过递归的方式处理我们需要借助langchain来实现。所以需要添加对应的模块
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_text_splitters import RecursiveCharacterTextSplitter text="自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。LP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。" splitter=RecursiveCharacterTextSplitter( chunk_size=50 , chunk_overlap=10 , length_function=len , ) chunks = splitter.split_text(text) for i,chunk in enumerate (chunks): print (f"块{i+1 } :{len (chunk)} :{chunk} " )
结果:
1 2 3 4 5 6 7 块1:50:自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语 块2:50:算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析 块3:50:的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NL 块4:50:摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了 块5:50:精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、 块6:50:解任务,如问答系统、语音识别和对话系统等。LP的研究推进不仅优化了人机交流,也对提升机器的自主性和智 块7:21:提升机器的自主性和智能水平起到了关键作用。
向量检索 检索的方式有哪些?列举两种:
关键字搜索:通过用户输入的关键字来查找文本数据。
语义搜索:不仅考虑关键词的匹配,还考虑词汇之间的语义关系,以提供更准确的搜索结果。
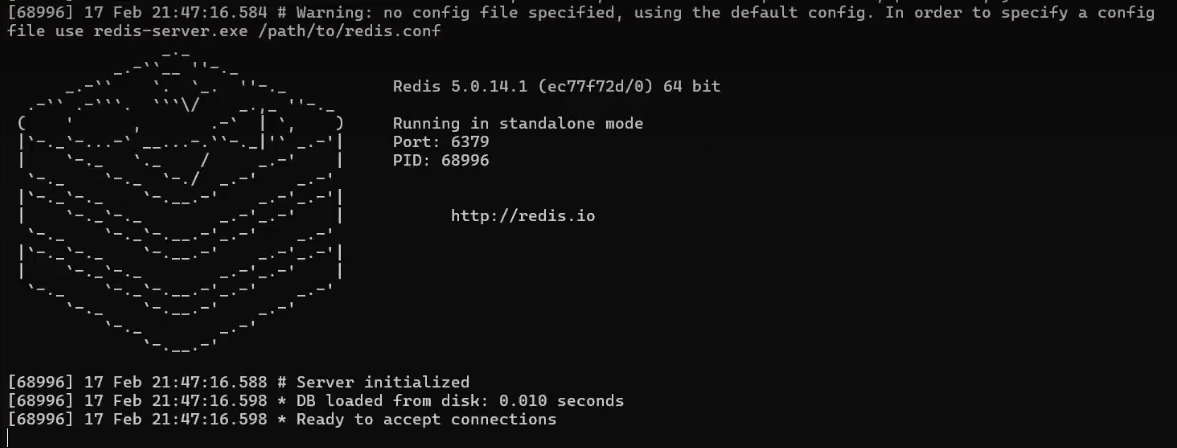
关键字检索 我们需要把相关的信息存储在Redis中。我们需要先按照一个Redis。在提供的资料中有。直接解压缩。然后 cmd进入到对应的目录。然后输入
然后我们可以通过代码把我们的数据导入到Redist中去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from openai import OpenAI from dotenv import load_dotenv import redis import json load_dotenv() client = OpenAI() r = redis.Redis(host='localhost' ,port=6379 ,decode_responses=True ) with open ('train_zh.json' ,'r' ,encoding='utf-8' )as f: data = [json.loads(line)for line in f] instructions = [ entry['instruction' ] for entry in data[0 :1000 ]] outputs = [entry['output' ]for entry in data[0 :1000 ]] for instruction,output in zip (instructions,outputs): r.set (instruction,output) def search_instructions (keyword,top_n=3 ): keys = r.keys(pattern="*" +keyword +"*" ) data=[] for key in keys: data.append(r.get(key)) return data[:top_n]
LLM接口封装:
1 2 3 4 5 6 7 8 9 10 11 from openai import OpenAI client = OpenAI() def get_completion (prompt,model="gpt-3.5-turbo" ): '''封装openai接口''' messages = [{"role" :"user" ,"content" :prompt}] response = client.chat.completions.create( model=model, messages=messages, temperature=0 , ) return response.choices[0 ].message.content
Prompt模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 user_query="白癜风" search_results = search_instructions(user_query,3 ) search_results = "" .join(search_results) print (search_results) prompt =f""" 你是一个问答机器人。 你的任务是根据下述给定的已知信息回答用户问题。 确保你的回复完全依据下述已知信息。 不要编造答案。如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。 已知信息: {search_results} 用户问: {user_query} 请用中文回答用户问题。 """ print ("===Prompt===" ) print (prompt) print ("===Prompt===" ) print ("===回复==" ) print (response)
向量数据库 在人工智能时代,向量数据库已成为数据管理和A模型不可或缺的一部分。向量数据库是一种专门设计用来存储和查询向量嵌入数据的数据库。这些向量嵌入是A模型用于识别模式、关联和潜在结构的关键数据表示。
随着A和机器学习应用的普及,这些模型生成的嵌入包含大量属性或特征,使得它们的表示难以管理。这就是为什么数据从业者需要一种专门为处理这种数据而开发的数据库,这就是向量数据库的用武之地。
Pinecone www.pinecone.io/
重复检测:帮助用户识别和删除重复的数据
排名跟踪:跟踪数据在搜索结果中的排名,有助于优化和调整搜索策略
数据搜索:快速搜索数据库中的数据,支持复杂的搜索条件
分类:对数据进行分类,便于管理和检索
去重:自动识别和删除重复数据,保持数据集的纯净和一致性
Milvus
毫秒级搜索万亿级向量数据集
简单管理非结构化数据
可靠的向量数据库,始终可用
高度可扩展和适应性强
混合搜索
统一的Lambda结构
受到社区支持,得到行业认可
Chroma www.trychroma.com/
功能丰富:支持香询、过滤、密度估计等多种功能
即将添加的语言链(LangChain)、Llamalndex等更多功能
相同的API可以在Python笔记本中运行,也可以扩展到集群,用于开发、测试和生产
Faiss https://github.com/facebookresearch/faiss
不仅返回最近的邻居,还返回第二近、第三近和第k近的邻居
可以同时搜索多个向量,而不仅仅是单个向量(批量处理)
使用最大内积搜索而不是最小欧几里得搜索
也支持其他距离度量,但程度较低。
返回查询位置附近指定半径内的所有元素(范围搜索)
可以将索引存储在磁盘上,而不仅仅是RAM中
如何选型向量数据库
如果已经有了自己的向量嵌入生成模型,那么需要的是一个能够高效存储和查询这些向量的数据库
如果需要数据库服务来生成向量嵌入,那么应该选择提供这类功能的产品
延迟要求
对于需要实时响应的应用程序,低延迟是关键。需要选择能够提供快速查询响应的数据库
如果应用程序允许批量处理,那么可以选择那些优化了大批量数据处理的数据库
开发人员的经验。
根据团队的技术栈和经验,选择一个易于集成和使用的数据库
如果团队成员对某些技术或框架更熟悉,那么选择一个能够与之无缝集成的数据库会更有利
chromadb演示
把数据存储到向量数据库,并通过向量数据库完成了检索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 from openai import OpenAI import chromadb from chromadb.config import settings from dotenv import load_dotenv import json load_dotenv() import os client = OpenAI() def get_embeddings (texts,model="text-embedding-3-large" ): '''封装OpenAI的Embedding模型接口''' data = client.embeddings.create(input =texts,model=model).data return [x.embedding for x in data] with open ('train_zh.json' ,'r' ,encoding='utf-8' )as f: data = [json.loads(line) for line in f ] instructions = [entry['instruction' ]for entry in data[0 :100 ]] outputs=[entry['output' ]for entry in data[0 :100 ]] class MyVectorDBConnector : def __init__ (self,collection_name,embedding_fn ): chroma_client= chromadb.Client(Settings(allow_reset=True )) chroma_client.reset() self .collection = chroma_client.get_or_create_collection(name=collection_name) self .embedding_fn = embedding_fn def add_documents (self,instructions,outputs ): '''向collection中添加文档与向量''' embeddings = self .embedding_fn(instructions) self .collection.add( embeddings=embeddings, documents=outputs, ids = [f"id{i} " for i in range (len (outputs))] ) def search (self,query,top_n ): '''检索向量数据库''' results=self .collection.query( query_embeddings = self .embedding_fn([query]), n_results = top_n ) return results vector_db = MyVectorDBConnector("demo" ,get_embeddings) vector_db.add_documents(instructions,outputs) User_query="得了白癜风怎么办?" results = vector_db.search(user_query,2 ) for para in results['documents' ][0 ]: print (para +"\n" )
基于向量检索的RAG实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 from dotenv import load_dotenvload_dotenv() from openai import OpenAIimport chromadbfrom chromadb.config import Settingsimport jsonclient = OpenAI() prompt_template = """ 你是一个问答机器人。 你的任务是根据下述给定的已知信息回答用户问题。 确保你的回复完全依据下述已知信息。不要编造答案。 如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。 已知信息: __INFO__ 用户问: __QUERY__ 请用中文回答用户问题。 """ with open ('train_zh.json' , 'r' , encoding='utf-8' ) as f: data = [json.loads(line) for line in f] instructions = [entry['instruction' ] for entry in data[0 :1000 ]] outputs = [entry['output' ] for entry in data[0 :1000 ]] def get_completion (prompt, model="gpt-4o" ): '''封装 openai 接口''' messages = [{"role" : "user" , "content" : prompt}] response = client.chat.completions.create( model=model, messages=messages, temperature=0 , ) return response.choices[0 ].message.content def build_prompt (prompt_template, **kwargs ): '''将 Prompt 模板赋值''' prompt = prompt_template for k, v in kwargs.items(): if isinstance (v, str ): val = v elif isinstance (v, list ) and all (isinstance (elem, str ) for elem in v): val = '\n' .join(v) else : val = str (v) prompt = prompt.replace(f"__{k.upper()} __" , val) return prompt class MyVectorDBConnector : def __init__ (self, collection_name, embedding_fn ): chroma_client = chromadb.Client(Settings(allow_reset=True )) chroma_client.reset() self .collection = chroma_client.get_or_create_collection(name=collection_name) self .embedding_fn = embedding_fn def add_documents (self, instructions, outputs ): '''向 collection 中添加文档与向量''' embeddings = self .embedding_fn(instructions) if len (embeddings) != len (instructions) or len (instructions) != len (outputs): raise ValueError("嵌入向量、instructions 和 outputs 数量不一致" ) self .collection.add( embeddings=embeddings, documents=outputs, ids=[f"id{i} " for i in range (len (outputs))] ) def search (self, query, top_n ): '''检索向量数据库''' results = self .collection.query( query_embeddings=self .embedding_fn([query]), n_results=top_n ) return results def get_embeddings (texts, model="text-embedding-3-large" ): '''封装 OpenAI 的 Embedding 模型接口''' data = client.embeddings.create(input =texts, model=model).data return [x.embedding for x in data] vector_db = MyVectorDBConnector("demo" , get_embeddings) vector_db.add_documents(instructions, outputs) class RAG_Bot : def __init__ (self, vector_db, llm_api, n_results=2 ): self .vector_db = vector_db self .llm_api = llm_api self .n_results = n_results def chat (self, user_query ): search_results = self .vector_db.search(user_query, self .n_results) prompt = build_prompt( prompt_template, info=search_results['documents' ][0 ], query=user_query) response = self .llm_api(prompt) return response bot = RAG_Bot( vector_db, llm_api=get_completion ) user_query = "拉肚子怎么办?" response = bot.chat(user_query) print (response)
输出的结果
1 2 3 4 5 6 7 8 您好,拉肚子可能是许多不同原因导致的,例如食物中毒、肠炎、病毒感染等。建议您注意以下几点: 1. 多喝水,保持水分,防止脱水。可以选择椰子水、果汁或盐水等饮品。 2. 避免食用生肉、生蛋、生海鲜等容易感染细菌的食物。 3. 避免食用过多的辛辣、油腻、刺激性食物,以及含有咖啡因和酒精的饮料。 4. 注意个人卫生,勤洗手,避免与患病的人接触。 5. 保持充足的休息,放松心情,避免过度劳累。 6. 注意饮食,少食多餐,可以吃些易消化、营养丰富的食物,如米粥、面条、鸡蛋、鸡肉等。 如果症状严重或持续加重,建议您去医院就诊,接受医生的诊断和治疗。
三、各大平台RAG实现 1.阿⾥云-百炼RAG 创建应⽤->上传数据->知识索引 https://bailian.console.aliyun.com/
通过Python来调用ARG服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import osfrom http import HTTPStatusfrom dashscope import Applicationresponse = Application.call( api_key="输入你自身的key" , app_id='输入你自身的appId' , prompt='观察者模式的介绍?你是基于知识库回答的还是基于你自身来回复的?' ) if response.status_code != HTTPStatus.OK: print (f'request_id={response.request_id} ' ) print (f'code={response.status_code} ' ) print (f'message={response.message} ' ) print (f'请参考文档:https://help.aliyun.com/zh/model-studio/developer-reference/error-code' ) else : print (response.output.text)
2. 智普RAG 创建应⽤->上传数据
https://www.zhipuai.cn/
3.Google的NoteBook https://notebooklm.google/
四、本地向量库 前面的案例中我们的向量化模型使用的是OpenAI提供的text-embedding-3-large,针对这块我们可以本地话一个向量模型。这样处理起来效率会更高一些。
将向量化的结果保存
huggingface:https://huggingface.co/models
国内的镜像:https://hf-mirror.com/
直接使用我们提供的本地的向量模型,并且拷贝到项目中
需要安装下这个依赖
1 pip install sentence_transformers
然后将数据保存到向量数据库并且持久化到本地
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from sentence_transformers import SentenceTransformerimport jsonimport numpy as npimport osimport chromadbmodel = SentenceTransformer(r'maidalun1020' ) with open ('train_zh.json' , 'r' , encoding='utf-8' ) as f: data = [json.loads(line) for line in f] instructions = [entry['instruction' ] for entry in data[0 :1000 ]] outputs = [entry['output' ] for entry in data[0 :1000 ]] instruction_embeddings = model.encode(instructions, convert_to_numpy=True ) np.save('instruction_embeddings.npy' , instruction_embeddings) client = chromadb.PersistentClient(path="./collection.pkl" ) collection = client.create_collection(name="demo" ) for i, (sentence, embedding) in enumerate (zip (instructions, instruction_embeddings)): collection.add( documents=[sentence], embeddings=[embedding.tolist()], ids=[f"id-{i} " ], metadatas=[{"output" : outputs[i]}] )
然后我们就可以结合LLM来实现对应的RAG案例效果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 import numpy as npfrom openai import OpenAIimport chromadbfrom dotenv import load_dotenvimport osfrom sentence_transformers import SentenceTransformerload_dotenv() client_openai = OpenAI() instruction_embeddings = np.load('instruction_embeddings.npy' ) client = chromadb.PersistentClient(path="./collection.pkl" ) collection = client.get_collection(name="demo" ) print (collection.count())model = SentenceTransformer(r'maidalun1020' ) def retrieve_response (query, top_k=5 ): query_embedding = model.encode([query], convert_to_numpy=True ) results = collection.query( query_embeddings=query_embedding.tolist(), n_results=top_k ) return [metadata['output' ] for metadata_list in results['metadatas' ] for metadata in metadata_list] prompt_template = """你是一个问答机器人。 你的任务是根据下述给定的已知信息回答用户问题。 确保你的回复完全依据下述已知信息。不要编造答案。 如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。 已知信息: __INFO__ 用户问: __QUERY__ 请用中文回答用户问题。 """ def build_prompt (prompt_template, **kwargs ): prompt = prompt_template for k, v in kwargs.items(): val = v if isinstance (v, str ) else '\n' .join(v) if isinstance (v, list ) else str (v) prompt = prompt.replace(f"__{k.upper()} __" , val) return prompt def get_completion (prompt, model="gpt-4o" ): messages = [{"role" : "user" , "content" : prompt}] response = client_openai.chat.completions.create( model=model, messages=messages, temperature=0 , ) return response.choices[0 ].message.content class RAG_Bot : def __init__ (self, llm_api, n_results=5 ): self .llm_api = llm_api self .n_results = n_results def chat (self, user_query ): search_results = retrieve_response(user_query, self .n_results) prompt = build_prompt(prompt_template, info=search_results, query=user_query) print (prompt) response = self .llm_api(prompt) return response user_query = "全身没劲,没精神,吃不下饭,怎么办?" bot = RAG_Bot(llm_api=get_completion) response = bot.chat(user_query) print (response)
然后获取到对应的响应结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 你是一个问答机器人。 你的任务是根据下述给定的已知信息回答用户问题。 确保你的回复完全依据下述已知信息。不要编造答案。 如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。 已知信息: 这种情况可能是皮肤过敏或者荨麻疹,建议您去医院皮肤科进行检查和诊断。在等待就医期间,您可以尝试以下措施缓解症状: 1. 避免摩擦或刺激皮肤,不要穿紧身衣物或使用过于刺激性的洗涤用品。 2. 保持皮肤清洁,定期洗澡并用温水。 3. 涂抹舒缓皮肤的乳液或药膏,如氢化可的松乳膏。 4. 避免暴露在过度干燥或过度潮湿的环境中。 5. 饮食上避免过度刺激的食物,如辛辣食品、海鲜等。 请注意,以上措施仅能缓解症状,如情况严重或症状持续,还是需要及时就医。 根据您的描述,这可能是一个鸡眼,也可能是一个肉瘤,建议您去医院就诊,由专业医生进行诊断。如果是鸡眼,可以使用一些药膏软化鸡眼,再用专业的工具去除。如果是肉瘤,需要进行手术治疗。在就诊之前,避免用手抠挖或切割,以免感染。 根据您的描述,这可能是皮肤受到了创伤或感染,建议您在保持手部清洁的前提下,使用一些抗生素软膏来预防感染。您可以前往药店购买一些非处方药,比如盐酸氯霉素软膏、红霉素软膏等,按照说明使用即可。如果症状加重或持续不缓解,建议您及时就医。 这种情况可能是因为毛囊炎或粉刺引起的。毛囊炎是毛囊感染或炎症,通常会在皮肤上形成红色丘疹或红点。粉刺是一种常见的皮肤问题,通常是因为皮脂和角质堵塞了毛孔。如果这些情况不引起疼痛或瘙痒,通常不需要治疗,只需保持皮肤清洁,避免挤压或摩擦区域。如果出现疼痛、发热、红肿等症状,建议就医咨询。 如果您的中指长了一个透明的水泡状物,但不痛不痒,这可能是一个无害的皮肤病变,例如皮肤囊肿。囊肿通常是由于皮肤下的毛囊或皮脂腺堵塞而形成的,可以出现在任何部位,包括手指。 建议您去看皮肤科医生,让医生进行诊断和治疗。医生可能会建议将囊肿切开和排出囊内物质,或者开处方药物来治疗。 用户问: 手臂上有小红点不痒不过怎样可以去除 请用中文回答用户问题。 这种情况可能是皮肤过敏或者荨麻疹,建议您去医院皮肤科进行检查和诊断。在等待就医期间,您可以尝试以下措施缓解症状: 6. 避免摩擦或刺激皮肤,不要穿紧身衣物或使用过于刺激性的洗涤用品。 7. 保持皮肤清洁,定期洗澡并用温水。 8. 涂抹舒缓皮肤的乳液或药膏,如氢化可的松乳膏。 9. 避免暴露在过度干燥或过度潮湿的环境中。 10. 饮食上避免过度刺激的食物,如辛辣食品、海鲜等。 请注意,以上措施仅能缓解症状,如情况严重或症状持续,还是需要及时就医。
五、RAG的缺陷 RAG痛点问题分析论文
论文:《Seven Failure Points When Engineering a Retrieval Augmented Generation System》
地址:https://arxiv.org/pdf/2401.05856
https://www.163.com/dy/article/JFTQNA200511D3QS.html
1. 具体痛点问题总结 Index Process(文本向量化构建索引的过程):
+ MIssing Content(内容缺失): 原本的文本中就没有问题的答案文档加载准确性和效率: 比如pdf文件的加载,如何提取其中的有用文字信息和图片信息等文档切分的粒度: 文本切分的大小和位置会影响后面检索出来的上下文完整性和与大模型交互的token数量,怎么控制好文档切分的度,是个难题。
Query Process(检索增强回答的过程中):Missed Top Ranked: 错过排名靠前的文档Not in Context: 提取上下文与答案无关Wrong Format(格式错误): 例如需要Json,给了字符串Incomplete(答案不完整): 答案只回答了问题的一部分Not Extracted(未提取到答案:) 提取的上下文中有答案,但大模型没有提取出来Incorrect Specificity: 答案不够具体或过于具体
2. 痛点问题策略分析 2.1 文档加载准确性和效率 优化文档读取器
一般知识库中的文档格式都不尽相同,HTML、PDF、MarkDown、TXT、CSV等。每种格式文档都有其都有的数据组织方式。怎么在读取这些数据时将干扰项去除(如一些特殊符号等),同时还保留原文本之间的关联关系(如csv文件保留其原有的表格结构),是主要的优化方向。
目前针对这方面的探索为:针对每一类文档,设计一个专门的读取器。如LangChain中提供的WebBaseLoader专门用来加载HTML文本等。
网址:https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/
数据清洗与增强
输入垃圾,那也必定输出垃圾。如果你的源数据质量低劣,比如包含互相冲突的信息,那不管你的 RAG 工作构建得多么好,它都不可能用你输入的垃圾神奇地输出高质量结果。这个解决方案不仅适用于这个痛点,任何RAG工作流程想要获得优良表现,都必须先清洁数据。
2.2 文档切分的粒度 粒度太大可能导致检索到的文本包含太多不相关的信息,降低检索准确性,粒度太小可能导致信息不全面,导致答案的片面性。问题的答案可能跨越两个甚至多个片段。
固定长度的分块
直接设定块中的字数,每个文本块有多少字。
内容重叠分块
在固定大小分块的基础上,为了保持文本块之间语义上下文的连贯性,在分块时,保持文本块之间有一定的内容重叠。
基于结构的分块
基于结构的分块方法利用文档的固有结构,如HTML或Markdown中的标题和段落,以保持内容的逻辑性和完整性。
基于递归的分块
重复的利用分块规则不断细分文本块。在langchain中会先通过段落换行符(\n\n)进行分割。然后,检查这些块的大小。如果大小不超过一定阈值,则该块被保留。对于大小超过标准的块,使用单换行符(\n)再次分割。以此类推,不断根据块大小更新更小的分块规则(如空格,句号)。
分块大小的选择
(1)不同的嵌入模型有其最佳输入大小。比如Openai的text-embedding-ada-002的模型在256 或 512大小的块上效果更好。
(2)文档的类型和用户查询的长度及复杂性也是决定分块大小的重要因素。处理长篇文章或书籍时,较大的分块有助于保留更多的上下文和主题连贯性;而对于社交媒体帖子,较小的分块可能更适合捕捉每个帖子的精确语义。如果用户的查询通常是简短和具体的,较小的分块可能更为合适;相反,如果查询较为复杂,可能需要更大的分块。
2.3 内容缺失 准备的外挂文本中没有回答问题所需的知识。这时候,RAG可能会提供一个自己编造的答案。
增加相应知识库
将相应的知识文本加入到向量知识库中。
数据清洗与增强
输入垃圾,那也必定输出垃圾。如果你的源数据质量低劣,比如包含互相冲突的信息,那不管你的 RAG 工作构建得多么好,它都不可能用你输入的垃圾神奇地输出高质量结果。这个解决方案不仅适用于这个痛点,任何RAG工作流程想要获得优良表现,都必须先清洁数据。
更好的Prompt设计
通过Prompts,让大模型在找不到答案的情况下,输出“根据当前知识库,无法回答该问题”等提示。这样的提示,就能鼓励模型承认自己的局限,并更透明地向用户传达它的不确定。虽然不能保证 100% 准确度,但在清洁数据之后,精心设计 prompt 是最好的做法之一。
2.4 错过排名靠前的文档 外挂知识库中存在回答问题所需的知识,但是可能这个知识块与问题的向量相似度排名并不是靠前的,导致无法召回该知识块传给大模型,导致大模型始终无法得到正确的答案.
增加召回数量
增加召回的 topK 数量,也就是说,例如原来召回前3个知识块,修改为召回前5个知识块。不推荐此种方法,因为知识块多了,不光会增加token消耗,也会增加大模型回答问题的干扰。
重排(Reranking)
该方法的步骤是,首先检索出 topN 个知识块(N > K,过召回),然后再对这 topN 个知识块进行重排序,取重排序后的 K 个知识块当作上下文。重排是利用另一个排序模型或排序策略,对知识块和问题之间进行关系计算与排序。
2.5 提取上下文与答案无关 内容缺失 或 错过排名靠前的文档 的具体体现
2.6 格式错误 Prompt调优
优化Prompt逐渐让大模型返回正确的格式。
2.7 答案不完整 将问题分开提问:一方面引导用户精简问题,一次只提问一个问题。 另一方面,针对用户的问题进行内部拆分处理,拆分成数个子问题,等子问题答案都找到后,再总结起来回复给用户
2.8 未提取到答案 提示压缩技术: 网址:https://mp.weixin.qq.com/s/61LZgc1a5yRP2J7MTIVZ4Q
3. RAG评估 3.1 RAG效果评估的必要性
评估出RAG对大模型能力改善的程度
RAG优化过程,通过评估可以知道改善的方向和参数调整的程度
3.2 RAG评估方法 人工评估
最Low的方式是进行人工评估:邀请专家或人工评估员对RAG生成的结果进行评估。他们可以根据预先定义的标准对生成的答案进行质量评估,如准确性、连贯性、相关性等。这种评估方法可以提供高质量的反馈,但可能会消耗大量的时间和人力资源。
自动化评估
自动化评估肯定是RAG评估的主流和发展方向。
LangSmith
需要准备测试数据集
RAGAS
RAGAs(Retrieval-Augmented Generation Assessment)是一个评估框架,文档。考虑检索系统识别相关和重点上下文段落的能力,LLM 以忠实方式利用这些段落的能力,以及生成本身的质量。
数据集格式
question:作为 RAG 管道输入的用户查询。输入。
answer:从 RAG 管道生成的答案。输出。
contexts:从用于回答question外部知识源中检索的上下文。
ground_truths:question的基本事实答案。这是唯一人工注释的信息。
3.3 评估指标 评估检索质量:
context_relevancy(上下文相关性,也叫 context_precision)
context_recall(召回性,越高表示检索出来的内容与正确答案越相关)
评估生成质量:
faithfulness(忠实性,越高表示答案的生成使用了越多的参考文档(检索出来的内容))
answer_relevancy(答案的相关性)
Context Recall:上下文召回衡量检索到的上下文(contexts)与标准答案(ground_truths)的匹配程度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from datasets import Datasetfrom ragas.metrics import context_precision, context_recall, faithfulness, answer_relevancyfrom ragas import evaluatefrom dotenv import load_dotenvload_dotenv() import osdata_samples = { 'question' : ['When was the first super bowl?' , 'Who won the most super bowls?' ], 'answer' : ['The first superbowl was held on Jan 15, 1967' , 'The most super bowls have been won by The New England Patriots' ], 'contexts' : [ ['The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles,' ], ['The Green Bay Packers...Green Bay, Wisconsin.' , 'The Packers compete...Football Conference' ] ], 'ground_truth' : ['The first superbowl was held on January 15, 1967' , 'The New England Patriots have won the Super Bowl a record six times' ] } dataset = Dataset.from_dict(data_samples) context_precision_score = evaluate(dataset, metrics=[context_precision]) context_recall_score = evaluate(dataset, metrics=[context_recall]) faithfulness_score = evaluate(dataset, metrics=[faithfulness]) answer_relevancy_score = evaluate(dataset, metrics=[answer_relevancy]) print (context_precision_score.to_pandas())print (context_recall_score.to_pandas())print (faithfulness_score.to_pandas())print (answer_relevancy_score.to_pandas())
输出的答案
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Python 3.9.13 (tags/v3.9.13:6de2ca5, May 17 2022, 16:36:42) [MSC v.1929 64 bit (AMD64)] Type 'copyright', 'credits' or 'license' for more information IPython 8.18.1 -- An enhanced Interactive Python. Type '?' for help. PyDev console: using IPython 8.18.1 Python 3.9.13 (tags/v3.9.13:6de2ca5, May 17 2022, 16:36:42) [MSC v.1929 64 bit (AMD64)] on win32 runfile('E:\\PythonWorkSpace\\LLMProject\\demo4.py', wdir='E:\\PythonWorkSpace\\LLMProject') Evaluating: 100%|██████████| 2/2 [00:05<00:00, 2.74s/it] Evaluating: 100%|██████████| 2/2 [00:03<00:00, 1.76s/it] Evaluating: 100%|██████████| 2/2 [00:07<00:00, 3.55s/it] Evaluating: 100%|██████████| 2/2 [00:36<00:00, 18.45s/it] user_input ... context_precision 0 When was the first super bowl? ... 1.0 1 Who won the most super bowls? ... 0.0 [2 rows x 5 columns] user_input ... context_recall 0 When was the first super bowl? ... 1.0 1 Who won the most super bowls? ... 0.0 [2 rows x 5 columns] user_input ... faithfulness 0 When was the first super bowl? ... 1.0 1 Who won the most super bowls? ... 0.0 [2 rows x 5 columns] user_input ... answer_relevancy 0 When was the first super bowl? ... 0.980736 1 Who won the most super bowls? ... 0.943014 [2 rows x 5 columns]