
深度学习
名词解释
目标函数
在机器学习中,我们需要定义模型的优劣程度的度量,这个度量在大多数情况是“可优化”的,这被称之为目标函数(objective function)。
我们通常定义一个目标函数,并希望优化它到最低点。 因为越低越好,所以这些函数有时被称为损失函数(loss function,或cost function)。
在一个数据集上,我们可以通过最小化总损失来学习模型参数的最佳值。 该数据集由一些为训练而收集的样本组成,称为训练数据集(training dataset,或称为训练集(training set))。 然而,在训练数据上表现良好的模型,并不一定在“新数据集”上有同样的性能,这里的“新数据集”通常称为测试数据集(test dataset,或称为_测试集_(test set))。
训练数据集用于拟合模型参数,测试数据集用于评估拟合的模型。
优化算法
一个模型和一个合适的损失函数,接下来就需要一种算法,它能够搜索出最佳参数,以最小化损失函数。
大多流行的优化算法通常基于一种基本方法–**_梯度下降_(gradient descent)**
监督学习
_监督学习_(supervised learning)擅长在“给定输入特征”的情况下预测标签。
每个“特征-标签”对都称为一个样本(example)。 有时,即使标签是未知的,样本也可以指代输入特征。
我们的目标是生成一个模型,能够将任何输入特征映射到标签(即预测)。
回归
是否是回归问题,本质上是由输出决定的。
当标签取任意数值时,我们称之为回归问题,此时的目标是生成一个模型,使它的预测非常接近实际标签值。
特点:预测一个值
分类
分类问题希望模型能够预测样本属于哪个类别(category,正式称为类(class))
分类问题的常见损失函数被称为交叉熵(cross-entropy)
标记问题
学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)。
推荐系统
推荐系统的目标是向特定用户进行“个性化”推荐。
推荐系统会为“给定用户和物品”的匹配性打分,这个“分数”可能是估计的评级或购买的概率。 由此,对于任何给定的用户,推荐系统都可以检索得分最高的对象集,然后将其推荐给用户。
无监督学习
数据中不含有“目标”的机器学习问题通常被为无监督学习(unsupervised learning)
例子:
_聚类_(clustering)问题:没有标签的情况下,我们是否能给数据分类呢?比如,给定一组照片,我们能把它们分成风景照片、狗、婴儿、猫和山峰的照片吗?同样,给定一组用户的网页浏览记录,我们能否将具有相似行为的用户聚类呢?
_主成分分析_(principal component analysis)问题:我们能否找到少量的参数来准确地捕捉数据的线性相关属性?比如,一个球的运动轨迹可以用球的速度、直径和质量来描述。再比如,裁缝们已经开发出了一小部分参数,这些参数相当准确地描述了人体的形状,以适应衣服的需要。另一个例子:在欧几里得空间中是否存在一种(任意结构的)对象的表示,使其符号属性能够很好地匹配?这可以用来描述实体及其关系,例如“罗马” - “意大利” + “法国” = “巴黎”。
_因果关系_(causality)和_概率图模型_(probabilistic graphical models)问题:我们能否描述观察到的许多数据的根本原因?例如,如果我们有关于房价、污染、犯罪、地理位置、教育和工资的人口统计数据,我们能否简单地根据经验数据发现它们之间的关系?
_生成对抗性网络_(generative adversarial networks):为我们提供一种合成数据的方法,甚至像图像和音频这样复杂的非结构化数据。潜在的统计机制是检查真实和虚假数据是否相同的测试,它是无监督学习的另一个重要而令人兴奋的领域。
强化学习
在强化学习问题中,智能体(agent)在一系列的时间步骤上与环境交互。 在每个特定时间点,智能体从环境接收一些_观察_(observation),并且必须选择一个_动作_(action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得_奖励_(reward)。 此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。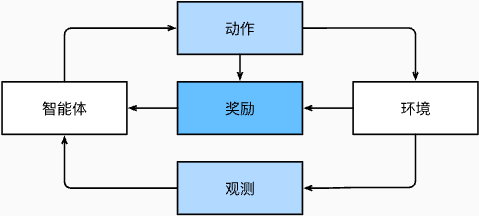
感知机
总结
感知机是一个二分类模型,是最早的A模型之一
它的求解算法等价于使用批量大小小为1的悌度下降
它不能以合XOR函数,导致的第一次AI寒冬
训练数据集:训练模型参数(数据集划分train那个训练集)
验证数据集:选择模型超参数 (数据集集别划分为test那个)
测试数据集:理论上只被使用一次
非大数据集上通常使用k-折交叉验证(对每一个超参数都会得到交叉验证的平均精度,任何我我们把最好的那个精度选择出来作为我们要采用的超参数)
超参数,模型以外的参数可以选的都是超参数(需要人为定义)
问题:k折交叉验证的目的是确定超参数吗?然后还要用这个超参数再训练一遍全数数据吗?
k折交叉验证有n种做法,
- 第一种做法就是确定超参数,然后用这个超参数再训练一遍全数数据
- 第二种做法是不再重新训练了,选定参数随便选一则的模型或者是找出精度最好的那一则模型拿出来,代价是训练得少一点点,少看了一些训练集。
- k则交叉验证的k个模型全部拉下来真的要预测的时候,把测试集全部放到每一个模型都预测一次,然后把预测结果取均值,代价预测时是代价k倍了。好处是增加模型的稳定性。
权重衰退
- 权重衰退通过L2正则项使得模型参数不会过大,从而控制模型复杂度
- 正则项权重是控制模型复杂度的超参数
丢弃法
- 丢弃法将一些输出项随机置0来控制模型复杂度
- 常作用在多层感知机的隐藏层输出上
- 丢弃概率是控制模型复杂度的超参数
如果网络层的输出中间层特征元素的值突然变成nan了,一般是梯度爆炸造成的
卷积层
- 卷积层将输入和核矩阵进行交叉相关,加上偏移后得到输出
- 核矩阵和偏移是可学习的参数
- 核矩阵的大小是超参数
填充
- 填充和步幅是卷积层的超参数
- 填充在输入周围添加额外的行列,来控制输出形状的减少量
- 步幅是每次滑动核窗口时的行/列的步长,可以成倍的减少输出形状
多个输入和输出的通道
- 输出通道数是卷积层的超参数
- 每个输入通道有独立的二维卷积核,所有通道结果相加得到一个输出通道结果
- 每个输出通道有独立的三维卷积核
池化层
- 池化层返回窗口中最大或平均值
- 缓解卷积层会位置的敏感性
- 同样有窗口大小、填充、和步幅作为超参数
LeNet
手写体识别
- LeNet是早期成功的神经网络
- 先使用卷积层来学习图片空间信息
- 然后使用全连接层来转换到类别空间
之前流行现在完全不一了
AlexNet
- AlexNet是更大更深的LeNet,10x参数个数,260x计算复杂度
- 新进入了丢弃法,RLU,最大池化层,和数据增强
- AlexNet赢下了20l2 ImageNet竞赛后,标志着新的一轮神经网络热潮的开始
VGG
- LeNet(1995)
- 2卷积+池化层
- 2全连接层
- AlexNet
- 更大更深
- ReLu,Dropout,数据增强
- VGG
- 更大更深的AlexNet(重复的VGG块)
总结
- VGG使用可重复使用的卷积块来构建深度卷积神经网络
- 不同的卷积块个数和超参数可以得到不同复杂度的变种
网络中的网络(NiN)
在现实中用的不是特别多,但提出了很多新的概念
- NiN块使用卷积层加两个1X1卷积层,
- 后者对每个像素增加了非线性性
- NN使用全局平均池化层来替代VGG和 AlexNet中的全连接层
- 不容易过拟合,更少的参数个数
含并行连结的网络(GoogLeNet)
inception块:小学生才做选择题,我全都要了
视频看到这里,先暂停一断时间


