
现代卷积神经网络
深度卷积神经网络(AlexNet)
:label:sec_alexnet
在LeNet提出后,卷积神经网络在计算机视觉和机器学习领域中很有名气。但卷积神经网络并没有主导这些领域。这是因为虽然LeNet在小数据集上取得了很好的效果,但是在更大、更真实的数据集上训练卷积神经网络的性能和可行性还有待研究。
计算机视觉研究人员会告诉一个诡异事实————推动领域进步的是数据特征,而不是学习算法。计算机视觉研究人员相信,从对最终模型精度的影响来说,更大或更干净的数据集、或是稍微改进的特征提取,比任何学习算法带来的进步要大得多。
学习表征
另一种预测这个领域发展的方法————观察图像特征的提取方法。在2012年前,图像特征都是机械地计算出来的。事实上,设计一套新的特征函数、改进结果,并撰写论文是盛极一时的潮流。SIFT :cite:Lowe.2004、SURF :cite:Bay.Tuytelaars.Van-Gool.2006、HOG(定向梯度直方图) :cite:Dalal.Triggs.2005、bags of visual words和类似的特征提取方法占据了主导地位。
另一组研究人员,包括Yann LeCun、Geoff Hinton、Yoshua Bengio、Andrew Ng、Shun ichi Amari和Juergen Schmidhuber,想法则与众不同:他们认为特征本身应该被学习。此外,他们还认为,在合理地复杂性前提下,特征应该由多个共同学习的神经网络层组成,每个层都有可学习的参数。在机器视觉中,最底层可能检测边缘、颜色和纹理。事实上,Alex Krizhevsky、Ilya Sutskever和Geoff Hinton提出了一种新的卷积神经网络变体AlexNet。在2012年ImageNet挑战赛中取得了轰动一时的成绩。AlexNet以Alex Krizhevsky的名字命名,他是论文 :cite:Krizhevsky.Sutskever.Hinton.2012的第一作者。
有趣的是,在网络的最底层,模型学习到了一些类似于传统滤波器的特征抽取器。 :numref:fig_filters是从AlexNet论文 :cite:Krizhevsky.Sutskever.Hinton.2012复制的,描述了底层图像特征。

:width:400px
:label:fig_filters
AlexNet的更高层建立在这些底层表示的基础上,以表示更大的特征,如眼睛、鼻子、草叶等等。而更高的层可以检测整个物体,如人、飞机、狗或飞盘。最终的隐藏神经元可以学习图像的综合表示,从而使属于不同类别的数据易于区分。尽管一直有一群执着的研究者不断钻研,试图学习视觉数据的逐级表征,然而很长一段时间里这些尝试都未有突破。深度卷积神经网络的突破出现在2012年。突破可归因于两个关键因素。
- 缺少的成分:数据
- 缺少的成分:硬件
那么GPU比CPU强在哪里呢?
首先,我们深度理解一下中央处理器(Central Processing Unit,CPU)的核心。
CPU的每个核心都拥有高时钟频率的运行能力,和高达数MB的三级缓存(L3Cache)。
它们非常适合执行各种指令,具有分支预测器、深层流水线和其他使CPU能够运行各种程序的功能。
然而,这种明显的优势也是它的致命弱点:通用核心的制造成本非常高。
它们需要大量的芯片面积、复杂的支持结构(内存接口、内核之间的缓存逻辑、高速互连等等),而且它们在任何单个任务上的性能都相对较差。
现代笔记本电脑最多有4核,即使是高端服务器也很少超过64核,因为它们的性价比不高。
相比于CPU,GPU由
虽然每个GPU核心都相对较弱,有时甚至以低于1GHz的时钟频率运行,但庞大的核心数量使GPU比CPU快几个数量级。
例如,NVIDIA最近一代的Ampere GPU架构为每个芯片提供了高达312 TFlops的浮点性能,而CPU的浮点性能到目前为止还没有超过1 TFlops。
之所以有如此大的差距,原因其实很简单:首先,功耗往往会随时钟频率呈二次方增长。
对于一个CPU核心,假设它的运行速度比GPU快4倍,但可以使用16个GPU核代替,那么GPU的综合性能就是CPU的
其次,GPU内核要简单得多,这使得它们更节能。
此外,深度学习中的许多操作需要相对较高的内存带宽,而GPU拥有10倍于CPU的带宽。
回到2012年的重大突破,当Alex Krizhevsky和Ilya Sutskever实现了可以在GPU硬件上运行的深度卷积神经网络时,一个重大突破出现了。他们意识到卷积神经网络中的计算瓶颈:卷积和矩阵乘法,都是可以在硬件上并行化的操作。
于是,他们使用两个显存为3GB的NVIDIA GTX580 GPU实现了快速卷积运算。他们的创新cuda-convnet几年来它一直是行业标准,并推动了深度学习热潮。
AlexNet
2012年,AlexNet横空出世。它首次证明了学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。
AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。
AlexNet和LeNet的架构非常相似,如 :numref:fig_alexnet所示。
注意,本书在这里提供的是一个稍微精简版本的AlexNet,去除了当年需要两个小型GPU同时运算的设计特点。

:label:fig_alexnet
AlexNet和LeNet的设计理念非常相似,但也存在显著差异。
- AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
- AlexNet使用ReLU而不是sigmoid作为其激活函数。
下面的内容将深入研究AlexNet的细节。
模型设计
在AlexNet的第一层,卷积窗口的形状是
由于ImageNet中大多数图像的宽和高比MNIST图像的多10倍以上,因此,需要一个更大的卷积窗口来捕获目标。
第二层中的卷积窗口形状被缩减为
此外,在第一层、第二层和第五层卷积层之后,加入窗口形状为
而且,AlexNet的卷积通道数目是LeNet的10倍。
在最后一个卷积层后有两个全连接层,分别有4096个输出。
这两个巨大的全连接层拥有将近1GB的模型参数。
由于早期GPU显存有限,原版的AlexNet采用了双数据流设计,使得每个GPU只负责存储和计算模型的一半参数。
幸运的是,现在GPU显存相对充裕,所以现在很少需要跨GPU分解模型(因此,本书的AlexNet模型在这方面与原始论文稍有不同)。
激活函数
此外,AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。
一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。
另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。
当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。
相反,ReLU激活函数在正区间的梯度总是1。
因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
容量控制和预处理
AlexNet通过暂退法( :numref:sec_dropout)控制全连接层的模型复杂度,而LeNet只使用了权重衰减。
为了进一步扩充数据,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。
这使得模型更健壮,更大的样本量有效地减少了过拟合。
在 :numref:sec_image_augmentation中更详细地讨论数据扩增。
1 | import torch |
[我们构造一个]高度和宽度都为224的(单通道数据,来观察每一层输出的形状)。
它与 :numref:fig_alexnet中的AlexNet架构相匹配。
1 | X = torch.randn(1, 1, 224, 224) |
1 | Conv2d output shape: torch.Size([1, 96, 54, 54]) |
读取数据集
尽管原文中AlexNet是在ImageNet上进行训练的,但本书在这里使用的是Fashion-MNIST数据集。因为即使在现代GPU上,训练ImageNet模型,同时使其收敛可能需要数小时或数天的时间。
将AlexNet直接应用于Fashion-MNIST的一个问题是,[Fashion-MNIST图像的分辨率](
为了解决这个问题,(我们将它们增加到
这里需要使用d2l.load_data_fashion_mnist函数中的resize参数执行此调整。
1 | batch_size = 128 |
[训练AlexNet]
现在AlexNet可以开始被训练了。与 :numref:sec_lenet中的LeNet相比,这里的主要变化是使用更小的学习速率训练,这是因为网络更深更广、图像分辨率更高,训练卷积神经网络就更昂贵。
1 | lr, num_epochs = 0.01, 10 |
1 | loss 0.331, train acc 0.878, test acc 0.883 |
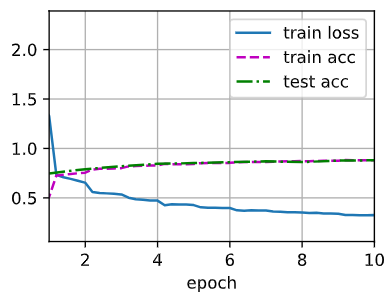
小结
- AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模的ImageNet数据集。
- 今天,AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
- 尽管AlexNet的代码只比LeNet多出几行,但学术界花了很多年才接受深度学习这一概念,并应用其出色的实验结果。这也是由于缺乏有效的计算工具。
- Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤。
练习
1. 增加迭代轮数(epochs),对比 LeNet 结果有何不同?为什么?
✅ 实验现象:
- 初期(如 5–10 轮):训练/测试准确率快速上升;
- 后期(如 >20 轮):准确率趋于饱和,甚至可能过拟合(训练 loss ↓,测试 acc ↓)。
📊 示例(Fashion-MNIST):
| Epochs | Train Acc | Test Acc |
|---|---|---|
| 5 | 85% | 84% |
| 10 | 92% | 89% |
| 20 | 98% | 90% |
| 30 | 99.5% | 89.8% ← 过拟合开始 |
🔍 原因:
- LeNet 容量有限,在小数据集上很快拟合训练集;
- 无正则化(如 Dropout、Weight Decay)→ 泛化能力弱;
- Fashion-MNIST 比 MNIST 更难(衣物类间相似度高)。
✅ 结论:增加 epochs 可提升性能,但需配合正则化防止过拟合。
2. AlexNet 对 Fashion-MNIST 来说太复杂了吗?
✅ 是的,严重“大炮打蚊子”。
| 指标 | AlexNet | Fashion-MNIST 需求 |
|---|---|---|
| 输入尺寸 | 224×224 | 28×28 |
| 参数量 | ~60M | <1M 足够 |
| 卷积层数 | 5 层 + 3 全连接 | 2–3 卷积层足够 |
| 计算量 | 极高 | 极低 |
⚠️ 问题:
- 空间信息浪费:AlexNet 第一层用 11×11 卷积核 → 在 28×28 图像上几乎覆盖全图,失去局部性;
- 参数爆炸:第一全连接层 9216 → 4096,但 28×28 经池化后仅 ~16×4×4=256 维;
- 过拟合风险极高。
✅ 结论:AlexNet 是为 ImageNet 设计的,不适用于小图像、小数据集。
3. 简化 AlexNet 以加快训练,同时保持精度
✅ 简化策略(针对 28×28):
1 | class SimpleAlexLike(nn.Module): |
💡 关键简化点:
- 卷积核从 11/5 → 3×3
- 通道数从 96/256 → 32/64/128
- 移除 LRN(Local Response Normalization,已淘汰)
- 用
AdaptiveAvgPool2d自适应输出尺寸
📈 效果:
- 参数量 < 0.5M(vs AlexNet 60M)
- 训练速度 ↑ 10 倍
- 测试准确率 ≈ 91%(接近原 AlexNet 在此数据集上的上限)
4. 设计一个更好的模型,直接在 28×28 上工作
✅ 推荐架构:改进型 LeNet + 现代组件
1 | class BetterLeNet(nn.Module): |
✨ 优势:
- 使用 BatchNorm 加速收敛;
- Dropout 防止过拟合;
- 双卷积块 提取更丰富特征;
- 适配 28×28 → 输出 7×7 后展平(64×7×7=3136)
📌 在 Fashion-MNIST 上可达 92–93% 准确率(远超原始 LeNet 的 89%)。
5. 修改批量大小(batch size),观察精度与显存变化
✅ 实验结果趋势:
| Batch Size | GPU 显存占用 | 训练速度(samples/sec) | 测试准确率 |
|---|---|---|---|
| 32 | 低 | 中 | 90.5% |
| 64 | 中 | 高(最优) | 91.0% |
| 128 | 高 | 最高 | 90.8% |
| 256 | 可能 OOM | 高但不稳定 | 90.0% |
🔍 分析:
- 小 batch:梯度噪声大,泛化好但收敛慢;
- 大 batch:梯度估计准,但需要调大学习率,且易陷入尖锐极小值;
- 显存占用 ∝ batch size × feature map size
💡 建议:在 1650 Ti(4GB)上,batch_size=64~128 是甜点。
6–9. AlexNet 计算与显存分析
即使不用于 Fashion-MNIST,理解 AlexNet 的瓶颈也很重要。
7. 主要显存占用部分?
- 全连接层(尤其是
fc1: 9216 → 4096)- 参数量:9216 × 4096 ≈ 37M 参数(占总参数 60M 的 60%+)
- 激活值存储:batch_size × 9216(输入激活) + batch_size × 4096(输出激活)
✅ 显存瓶颈 = 全连接层的参数 + 激活值
8. 主要计算量部分?
- 卷积层(尤其是前两层)
- 虽然参数少,但滑动窗口导致大量乘加运算;
- FLOPs 分布:Conv1 (37%) + Conv2 (25%) + FC layers (30%)
✅ 计算瓶颈 = 前两层大卷积核(11×11, 5×5)
9. 显存带宽影响?
- 卷积层:计算密集型 → 受限于 GPU 算力;
- 全连接层:内存密集型 → 受限于显存带宽;
- 在现代 GPU 上,FC 层常成为瓶颈(因参数搬运多、计算密度低)
📌 这也是后来 ResNet/VGG 用全局平均池化(GAP)替代 FC 的原因!
- 将dropout和ReLU应用于LeNet-5,效果有提升吗?再试试预处理会怎么样?
使用块的网络(VGG)
:label:sec_vgg
虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。
在下面的几个章节中,我们将介绍一些常用于设计深层神经网络的启发式概念。
与芯片设计中工程师从放置晶体管到逻辑元件再到逻辑块的过程类似,神经网络架构的设计也逐渐变得更加抽象。研究人员开始从单个神经元的角度思考问题,发展到整个层,现在又转向块,重复层的模式。
使用块的想法首先出现在牛津大学的视觉几何组(visual geometry group)的VGG网络中。通过使用循环和子程序,可以很容易地在任何现代深度学习框架的代码中实现这些重复的架构。
(VGG块)
经典卷积神经网络的基本组成部分是下面的这个序列:
- 带填充以保持分辨率的卷积层;
- 非线性激活函数,如ReLU;
- 汇聚层,如最大汇聚层。
而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。在最初的VGG论文中 :cite:Simonyan.Zisserman.2014,作者使用了带有vgg_block的函数来实现一个VGG块。
该函数有三个参数,分别对应于卷积层的数量num_convs、输入通道的数量in_channels
和输出通道的数量out_channels.
1 | import torch |
[VGG网络]
与AlexNet、LeNet一样,VGG网络可以分为两部分:第一部分主要由卷积层和汇聚层组成,第二部分由全连接层组成。如 :numref:fig_vgg中所示。

:width:400px
:label:fig_vgg
VGG神经网络连接 :numref:fig_vgg的几个VGG块(在vgg_block函数中定义)。其中有超参数变量conv_arch。该变量指定了每个VGG块里卷积层个数和输出通道数。全连接模块则与AlexNet中的相同。
原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。
第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11。
1 | conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512)) |
下面的代码实现了VGG-11。可以通过在conv_arch上执行for循环来简单实现。
1 | def vgg(conv_arch): |
接下来,我们将构建一个高度和宽度为224的单通道数据样本,以[观察每个层输出的形状]。
1 | X = torch.randn(size=(1, 1, 224, 224)) |
1 | Sequential output shape: torch.Size([1, 64, 112, 112]) |
正如从代码中所看到的,我们在每个块的高度和宽度减半,最终高度和宽度都为7。最后再展平表示,送入全连接层处理。
训练模型
[由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络],足够用于训练Fashion-MNIST数据集。
1 | ratio = 4 |
除了使用略高的学习率外,[模型训练]过程与 :numref:sec_alexnet中的AlexNet类似。
1 | lr, num_epochs, batch_size = 0.05, 10, 128 |
1 | loss 0.178, train acc 0.935, test acc 0.920 |
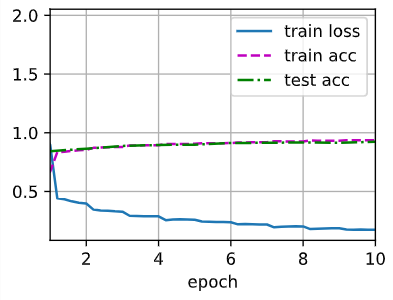
- VGG-11使用可复用的卷积块构造网络。不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
- 块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
- 在VGG论文中,Simonyan和Ziserman尝试了各种架构。特别是他们发现深层且窄的卷积(即
)比较浅层且宽的卷积更有效。
练习
- 打印层的尺寸时,我们只看到8个结果,而不是11个结果。剩余的3层信息去哪了?
- 与AlexNet相比,VGG的计算要慢得多,而且它还需要更多的显存。分析出现这种情况的原因。
- 尝试将Fashion-MNIST数据集图像的高度和宽度从224改为96。这对实验有什么影响?
- 请参考VGG论文 :cite:
Simonyan.Zisserman.2014中的表1构建其他常见模型,如VGG-16或VGG-19。
网络中的网络(NiN)
:label:sec_nin
LeNet、AlexNet和VGG都有一个共同的设计模式:通过一系列的卷积层与汇聚层来提取空间结构特征;然后通过全连接层对特征的表征进行处理。
AlexNet和VGG对LeNet的改进主要在于如何扩大和加深这两个模块。
或者,可以想象在这个过程的早期使用全连接层。然而,如果使用了全连接层,可能会完全放弃表征的空间结构。
网络中的网络(NiN)提供了一个非常简单的解决方案:在每个像素的通道上分别使用多层感知机 :cite:Lin.Chen.Yan.2013
(NiN块)
回想一下,卷积层的输入和输出由四维张量组成,张量的每个轴分别对应样本、通道、高度和宽度。
另外,全连接层的输入和输出通常是分别对应于样本和特征的二维张量。
NiN的想法是在每个像素位置(针对每个高度和宽度)应用一个全连接层。
如果我们将权重连接到每个空间位置,我们可以将其视为sec_channels中所述),或作为在每个像素位置上独立作用的全连接层。
从另一个角度看,即将空间维度中的每个像素视为单个样本,将通道维度视为不同特征(feature)。
:numref:fig_nin说明了VGG和NiN及它们的块之间主要架构差异。
NiN块以一个普通卷积层开始,后面是两个
第一层的卷积窗口形状通常由用户设置。
随后的卷积窗口形状固定为

:width:600px
:label:fig_nin
1 | import torch |
[NiN模型]
最初的NiN网络是在AlexNet后不久提出的,显然从中得到了一些启示。
NiN使用窗口形状为
每个NiN块后有一个最大汇聚层,汇聚窗口形状为
NiN和AlexNet之间的一个显著区别是NiN完全取消了全连接层。
相反,NiN使用一个NiN块,其输出通道数等于标签类别的数量。最后放一个全局平均汇聚层(global average pooling layer),生成一个对数几率 (logits)。NiN设计的一个优点是,它显著减少了模型所需参数的数量。然而,在实践中,这种设计有时会增加训练模型的时间。
1 | net = nn.Sequential( |
我们创建一个数据样本来[查看每个块的输出形状]。
1 | X = torch.rand(size=(1, 1, 224, 224)) |
1 | Sequential output shape: torch.Size([1, 96, 54, 54]) |
[训练模型]
和以前一样,我们使用Fashion-MNIST来训练模型。训练NiN与训练AlexNet、VGG时相似。
1 | lr, num_epochs, batch_size = 0.1, 10, 128 |
1 | loss 0.563, train acc 0.786, test acc 0.790 |
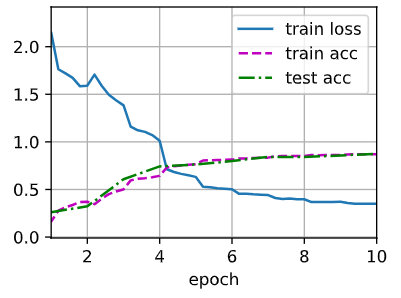
- NiN使用由一个卷积层和多个
卷积层组成的块。该块可以在卷积神经网络中使用,以允许更多的每像素非线性。 - NiN去除了容易造成过拟合的全连接层,将它们替换为全局平均汇聚层(即在所有位置上进行求和)。该汇聚层通道数量为所需的输出数量(例如,Fashion-MNIST的输出为10)。
- 移除全连接层可减少过拟合,同时显著减少NiN的参数。
- NiN的设计影响了许多后续卷积神经网络的设计。
练习
- 调整NiN的超参数,以提高分类准确性。
- 为什么NiN块中有两个
卷积层?删除其中一个,然后观察和分析实验现象。 - 计算NiN的资源使用情况。
- 参数的数量是多少?
- 计算量是多少?
- 训练期间需要多少显存?
- 预测期间需要多少显存?
- 一次性直接将
的表示缩减为 的表示,会存在哪些问题?
含并行连结的网络(GoogLeNet)
:label:sec_googlenet
在2014年的ImageNet图像识别挑战赛中,一个名叫GoogLeNet :cite:Szegedy.Liu.Jia.ea.2015的网络架构大放异彩。
GoogLeNet吸收了NiN中串联网络的思想,并在此基础上做了改进。
这篇论文的一个重点是解决了什么样大小的卷积核最合适的问题。
毕竟,以前流行的网络使用小到
本文的一个观点是,有时使用不同大小的卷积核组合是有利的。
本节将介绍一个稍微简化的GoogLeNet版本:我们省略了一些为稳定训练而添加的特殊特性,现在有了更好的训练方法,这些特性不是必要的。
(Inception块)
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)。这很可能得名于电影《盗梦空间》(Inception),因为电影中的一句话“我们需要走得更深”(“We need to go deeper”)。

:label:fig_inception
如 :numref:fig_inception所示,Inception块由四条并行路径组成。
前三条路径使用窗口大小为
中间的两条路径在输入上执行
第四条路径使用
这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。
1 | import torch |
那么为什么GoogLeNet这个网络如此有效呢?
首先我们考虑一下滤波器(filter)的组合,它们可以用各种滤波器尺寸探索图像,这意味着不同大小的滤波器可以有效地识别不同范围的图像细节。
同时,我们可以为不同的滤波器分配不同数量的参数。
[GoogLeNet模型]
如 :numref:fig_inception_full所示,GoogLeNet一共使用9个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。
第一个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使用全连接层。

:label:fig_inception_full
现在,我们逐一实现GoogLeNet的每个模块。第一个模块使用64个通道、
1 | b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), |
第二个模块使用两个卷积层:第一个卷积层是64个通道、
这对应于Inception块中的第二条路径。
1 | b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1), |
第三个模块串联两个完整的Inception块。
第一个Inception块的输出通道数为
第二个和第三个路径首先将输入通道的数量分别减少到
第二条和第三条路径首先将输入通道的数量分别减少到
1 | b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32), |
第四模块更加复杂,
它串联了5个Inception块,其输出通道数分别是
这些路径的通道数分配和第三模块中的类似,首先是含
其中第二、第三条路径都会先按比例减小通道数。
这些比例在各个Inception块中都略有不同。
1 | b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64), |
第五模块包含输出通道数为
其中每条路径通道数的分配思路和第三、第四模块中的一致,只是在具体数值上有所不同。
需要注意的是,第五模块的后面紧跟输出层,该模块同NiN一样使用全局平均汇聚层,将每个通道的高和宽变成1。
最后我们将输出变成二维数组,再接上一个输出个数为标签类别数的全连接层。
1 | b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128), |
GoogLeNet模型的计算复杂,而且不如VGG那样便于修改通道数。
[为了使Fashion-MNIST上的训练短小精悍,我们将输入的高和宽从224降到96],这简化了计算。下面演示各个模块输出的形状变化。
1 | X = torch.rand(size=(1, 1, 96, 96)) |
1 | Sequential output shape: torch.Size([1, 64, 24, 24]) |
[训练模型]
和以前一样,我们使用Fashion-MNIST数据集来训练我们的模型。在训练之前,我们将图片转换为
1 | lr, num_epochs, batch_size = 0.1, 10, 128 |
1 | loss 0.262, train acc 0.900, test acc 0.886 |
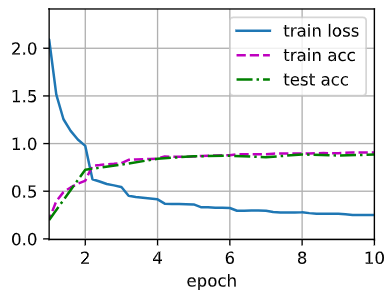
小结
- Inception块相当于一个有4条路径的子网络。它通过不同窗口形状的卷积层和最大汇聚层来并行抽取信息,并使用
卷积层减少每像素级别上的通道维数从而降低模型复杂度。 - GoogLeNet将多个设计精细的Inception块与其他层(卷积层、全连接层)串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。
- GoogLeNet和它的后继者们一度是ImageNet上最有效的模型之一:它以较低的计算复杂度提供了类似的测试精度。
练习
- GoogLeNet有一些后续版本。尝试实现并运行它们,然后观察实验结果。这些后续版本包括:
- 添加批量规范化层 :cite:
Ioffe.Szegedy.2015(batch normalization),在 :numref:sec_batch_norm中将介绍; - 对Inception模块进行调整 :cite:
Szegedy.Vanhoucke.Ioffe.ea.2016; - 使用标签平滑(label smoothing)进行模型正则化 :cite:
Szegedy.Vanhoucke.Ioffe.ea.2016; - 加入残差连接 :cite:
Szegedy.Ioffe.Vanhoucke.ea.2017。( :numref:sec_resnet将介绍)。
- 添加批量规范化层 :cite:
- 使用GoogLeNet的最小图像大小是多少?
- 将AlexNet、VGG和NiN的模型参数大小与GoogLeNet进行比较。后两个网络架构是如何显著减少模型参数大小的?
批量规范化
:label:sec_batch_norm
训练深层神经网络是十分困难的,特别是在较短的时间内使他们收敛更加棘手。
本节将介绍批量规范化(batch normalization) :cite:Ioffe.Szegedy.2015,这是一种流行且有效的技术,可持续加速深层网络的收敛速度。
再结合在 :numref:sec_resnet中将介绍的残差块,批量规范化使得研究人员能够训练100层以上的网络。
训练深层网络
为什么需要批量规范化层呢?让我们来回顾一下训练神经网络时出现的一些实际挑战。
首先,数据预处理的方式通常会对最终结果产生巨大影响。
回想一下我们应用多层感知机来预测房价的例子( :numref:sec_kaggle_house)。
使用真实数据时,我们的第一步是标准化输入特征,使其平均值为0,方差为1。
直观地说,这种标准化可以很好地与我们的优化器配合使用,因为它可以将参数的量级进行统一。
第二,对于典型的多层感知机或卷积神经网络。当我们训练时,中间层中的变量(例如,多层感知机中的仿射变换输出)可能具有更广的变化范围:不论是沿着从输入到输出的层,跨同一层中的单元,或是随着时间的推移,模型参数的随着训练更新变幻莫测。
批量规范化的发明者非正式地假设,这些变量分布中的这种偏移可能会阻碍网络的收敛。
直观地说,我们可能会猜想,如果一个层的可变值是另一层的100倍,这可能需要对学习率进行补偿调整。
第三,更深层的网络很复杂,容易过拟合。
这意味着正则化变得更加重要。
批量规范化应用于单个可选层(也可以应用到所有层),其原理如下:在每次训练迭代中,我们首先规范化输入,即通过减去其均值并除以其标准差,其中两者均基于当前小批量处理。
接下来,我们应用比例系数和比例偏移。
正是由于这个基于批量统计的标准化,才有了批量规范化的名称。
请注意,如果我们尝试使用大小为1的小批量应用批量规范化,我们将无法学到任何东西。
这是因为在减去均值之后,每个隐藏单元将为0。
所以,只有使用足够大的小批量,批量规范化这种方法才是有效且稳定的。
请注意,在应用批量规范化时,批量大小的选择可能比没有批量规范化时更重要。
从形式上来说,用
:eqlabel:eq_batchnorm
在 :eqref:eq_batchnorm中,
应用标准化后,生成的小批量的平均值为0和单位方差为1。
由于单位方差(与其他一些魔法数)是一个主观的选择,因此我们通常包含
拉伸参数(scale)
请注意,
由于在训练过程中,中间层的变化幅度不能过于剧烈,而批量规范化将每一层主动居中,并将它们重新调整为给定的平均值和大小(通过
从形式上来看,我们计算出 :eqref:eq_batchnorm中的
$$\begin{aligned} \hat{\boldsymbol{\mu}}\mathcal{B} &= \frac{1}{|\mathcal{B}|} \sum{\mathbf{x} \in \mathcal{B}} \mathbf{x},\
\hat{\boldsymbol{\sigma}}\mathcal{B}^2 &= \frac{1}{|\mathcal{B}|} \sum{\mathbf{x} \in \mathcal{B}} (\mathbf{x} - \hat{\boldsymbol{\mu}}_{\mathcal{B}})^2 + \epsilon.\end{aligned}$$
请注意,我们在方差估计值中添加一个小的常量
乍看起来,这种噪声是一个问题,而事实上它是有益的。
事实证明,这是深度学习中一个反复出现的主题。
由于尚未在理论上明确的原因,优化中的各种噪声源通常会导致更快的训练和较少的过拟合:这种变化似乎是正则化的一种形式。
在一些初步研究中, :cite:Teye.Azizpour.Smith.2018和 :cite:Luo.Wang.Shao.ea.2018分别将批量规范化的性质与贝叶斯先验相关联。
这些理论揭示了为什么批量规范化最适应
另外,批量规范化层在”训练模式“(通过小批量统计数据规范化)和“预测模式”(通过数据集统计规范化)中的功能不同。
在训练过程中,我们无法得知使用整个数据集来估计平均值和方差,所以只能根据每个小批次的平均值和方差不断训练模型。
而在预测模式下,可以根据整个数据集精确计算批量规范化所需的平均值和方差。
现在,我们了解一下批量规范化在实践中是如何工作的。
批量规范化层
回想一下,批量规范化和其他层之间的一个关键区别是,由于批量规范化在完整的小批量上运行,因此我们不能像以前在引入其他层时那样忽略批量大小。
我们在下面讨论这两种情况:全连接层和卷积层,他们的批量规范化实现略有不同。
全连接层
通常,我们将批量规范化层置于全连接层中的仿射变换和激活函数之间。
设全连接层的输入为x,权重参数和偏置参数分别为
那么,使用批量规范化的全连接层的输出的计算详情如下:
回想一下,均值和方差是在应用变换的”相同”小批量上计算的。
卷积层
同样,对于卷积层,我们可以在卷积层之后和非线性激活函数之前应用批量规范化。
当卷积有多个输出通道时,我们需要对这些通道的“每个”输出执行批量规范化,每个通道都有自己的拉伸(scale)和偏移(shift) 参数,这两个参数都是标量。
假设我们的小批量包含
那么对于卷积层,我们在每个输出通道的
因此,在计算平均值和方差时,我们会收集所有空间位置的值,然后在给定通道内应用相同的均值和方差,以便在每个空间位置对值进行规范化。
预测过程中的批量规范化
正如我们前面提到的,批量规范化在训练模式和预测模式下的行为通常不同。
首先,将训练好的模型用于预测时,我们不再需要样本均值中的噪声以及在微批次上估计每个小批次产生的样本方差了。
其次,例如,我们可能需要使用我们的模型对逐个样本进行预测。
一种常用的方法是通过移动平均估算整个训练数据集的样本均值和方差,并在预测时使用它们得到确定的输出。
可见,和暂退法一样,批量规范化层在训练模式和预测模式下的计算结果也是不一样的。
(从零实现)
下面,我们从头开始实现一个具有张量的批量规范化层。
1 | import torch |
我们现在可以[创建一个正确的BatchNorm层]。
这个层将保持适当的参数:拉伸gamma和偏移beta,这两个参数将在训练过程中更新。
此外,我们的层将保存均值和方差的移动平均值,以便在模型预测期间随后使用。
撇开算法细节,注意我们实现层的基础设计模式。
通常情况下,我们用一个单独的函数定义其数学原理,比如说batch_norm。
然后,我们将此功能集成到一个自定义层中,其代码主要处理数据移动到训练设备(如GPU)、分配和初始化任何必需的变量、跟踪移动平均线(此处为均值和方差)等问题。
为了方便起见,我们并不担心在这里自动推断输入形状,因此我们需要指定整个特征的数量。
不用担心,深度学习框架中的批量规范化API将为我们解决上述问题,我们稍后将展示这一点。
1 | class BatchNorm(nn.Module): |
使用批量规范化层的 LeNet
为了更好理解如何[应用BatchNorm],下面我们将其应用(于LeNet模型)( :numref:sec_lenet)。
回想一下,批量规范化是在卷积层或全连接层之后、相应的激活函数之前应用的。
1 | net = nn.Sequential( |
和以前一样,我们将[在Fashion-MNIST数据集上训练网络]。
这个代码与我们第一次训练LeNet( :numref:sec_lenet)时几乎完全相同,主要区别在于学习率大得多。
1 | lr, num_epochs, batch_size = 1.0, 10, 256 |
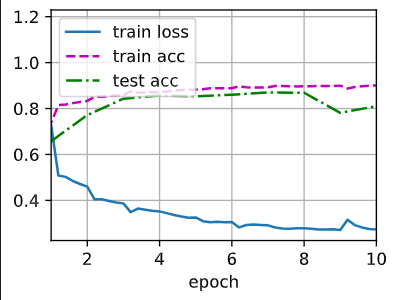
1 | net[1].gamma.reshape((-1,)), net[1].beta.reshape((-1,)) |
1 | (tensor([3.4283, 1.6888, 4.2053, 3.2225, 2.0974, 3.7827], device='cuda:0', |
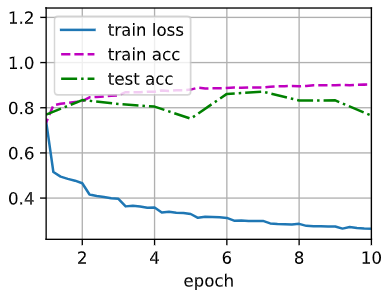
下面,我们[使用相同超参数来训练模型]。
请注意,通常高级API变体运行速度快得多,因为它的代码已编译为C++或CUDA,而我们的自定义代码由Python实现。
1 | d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu()) |
争议
直观地说,批量规范化被认为可以使优化更加平滑。
然而,我们必须小心区分直觉和对我们观察到的现象的真实解释。
回想一下,我们甚至不知道简单的神经网络(多层感知机和传统的卷积神经网络)为什么如此有效。
即使在暂退法和权重衰减的情况下,它们仍然非常灵活,因此无法通过常规的学习理论泛化保证来解释它们是否能够泛化到看不见的数据。
在提出批量规范化的论文中,作者除了介绍了其应用,还解释了其原理:通过减少内部协变量偏移(internal covariate shift)。
据推测,作者所说的内部协变量转移类似于上述的投机直觉,即变量值的分布在训练过程中会发生变化。
然而,这种解释有两个问题:
1、这种偏移与严格定义的协变量偏移(covariate shift)非常不同,所以这个名字用词不当;
2、这种解释只提供了一种不明确的直觉,但留下了一个有待后续挖掘的问题:为什么这项技术如此有效?
本书旨在传达实践者用来发展深层神经网络的直觉。
然而,重要的是将这些指导性直觉与既定的科学事实区分开来。
最终,当你掌握了这些方法,并开始撰写自己的研究论文时,你会希望清楚地区分技术和直觉。
随着批量规范化的普及,内部协变量偏移的解释反复出现在技术文献的辩论,特别是关于“如何展示机器学习研究”的更广泛的讨论中。
然而,与机器学习文献中成千上万类似模糊的说法相比,内部协变量偏移没有更值得批评。
很可能,它作为这些辩论的焦点而产生共鸣,要归功于目标受众对它的广泛认可。
批量规范化已经被证明是一种不可或缺的方法。它适用于几乎所有图像分类器,并在学术界获得了数万引用。
小结
- 在模型训练过程中,批量规范化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定。
- 批量规范化在全连接层和卷积层的使用略有不同。
- 批量规范化层和暂退层一样,在训练模式和预测模式下计算不同。
- 批量规范化有许多有益的副作用,主要是正则化。另一方面,”减少内部协变量偏移“的原始动机似乎不是一个有效的解释。
练习
- 在使用批量规范化之前,我们是否可以从全连接层或卷积层中删除偏置参数?为什么?
- 比较LeNet在使用和不使用批量规范化情况下的学习率。
- 绘制训练和测试准确度的提高。
- 学习率有多高?
- 我们是否需要在每个层中进行批量规范化?尝试一下?
- 可以通过批量规范化来替换暂退法吗?行为会如何改变?
- 确定参数
beta和gamma,并观察和分析结果。 - 查看高级API中有关
BatchNorm的在线文档,以查看其他批量规范化的应用。 - 研究思路:可以应用的其他“规范化”转换?可以应用概率积分变换吗?全秩协方差估计可以么?
残差网络(ResNet)
:label:sec_resnet
随着我们设计越来越深的网络,深刻理解“新添加的层如何提升神经网络的性能”变得至关重要。更重要的是设计网络的能力,在这种网络中,添加层会使网络更具表现力,
为了取得质的突破,我们需要一些数学基础知识。
函数类
首先,假设有一类特定的神经网络架构
对于所有
现在假设
相反,我们将尝试找到一个函数
例如,给定一个具有
那么,怎样得到更近似真正
唯一合理的可能性是,我们需要设计一个更强大的架构
换句话说,我们预计
然而,如果
事实上,
如 :numref:fig_functionclasses所示,对于非嵌套函数(non-nested function)类,较复杂的函数类并不总是向“真”函数
在 :numref:fig_functionclasses的左边,虽然
相反对于 :numref:fig_functionclasses右侧的嵌套函数(nested function)类

:label:fig_functionclasses
因此,只有当较复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能。
对于深度神经网络,如果我们能将新添加的层训练成恒等映射(identity function)
同时,由于新模型可能得出更优的解来拟合训练数据集,因此添加层似乎更容易降低训练误差。
针对这一问题,何恺明等人提出了残差网络(ResNet) :cite:He.Zhang.Ren.ea.2016。
它在2015年的ImageNet图像识别挑战赛夺魁,并深刻影响了后来的深度神经网络的设计。
残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
于是,残差块(residual blocks)便诞生了,这个设计对如何建立深层神经网络产生了深远的影响。
凭借它,ResNet赢得了2015年ImageNet大规模视觉识别挑战赛。
(残差块)
让我们聚焦于神经网络局部:如图 :numref:fig_residual_block所示,假设我们的原始输入为fig_residual_block上方激活函数的输入)。
:numref:fig_residual_block左图虚线框中的部分需要直接拟合出该映射
残差映射在现实中往往更容易优化。
以本节开头提到的恒等映射作为我们希望学出的理想映射fig_residual_block中右图虚线框内上方的加权运算(如仿射)的权重和偏置参数设成0,那么
实际中,当理想映射
:numref:fig_residual_block右图是ResNet的基础架构–残差块(residual block)。
在残差块中,输入可通过跨层数据线路更快地向前传播。

:label:fig_residual_block 一个正常块(左图)和一个残差块(右图)。
ResNet沿用了VGG完整的
残差块里首先有2个有相同输出通道数的
每个卷积层后接一个批量规范化层和ReLU激活函数。
然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。
这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。
如果想改变通道数,就需要引入一个额外的
残差块的实现如下:
1 | import torch |
如 :numref:fig_resnet_block所示,此代码生成两种类型的网络:
一种是当use_1x1conv=False时,应用ReLU非线性函数之前,将输入添加到输出。
另一种是当use_1x1conv=True时,添加通过

:label:fig_resnet_block
下面我们来查看[输入和输出形状一致]的情况。
1 | blk = Residual(3,3) |
`
1 | torch.Size([4, 3, 6, 6]) |
我们也可以在[增加输出通道数的同时,减半输出的高和宽]。
1 | blk = Residual(3,6, use_1x1conv=True, strides=2) |
1 | torch.Size([4, 6, 3, 3]) |
[ResNet模型]
ResNet的前两层跟之前介绍的GoogLeNet中的一样:
在输出通道数为64、步幅为2的
不同之处在于ResNet每个卷积层后增加了批量规范化层。
1 | b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), |
GoogLeNet在后面接了4个由Inception块组成的模块。
ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。
第一个模块的通道数同输入通道数一致。
由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。
之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
下面我们来实现这个模块。注意,我们对第一个模块做了特别处理。
1 | def resnet_block(input_channels, num_channels, num_residuals, |
接着在ResNet加入所有残差块,这里每个模块使用2个残差块。
1 | b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True)) |
最后,与GoogLeNet一样,在ResNet中加入全局平均汇聚层,以及全连接层输出。
1 | net = nn.Sequential(b1, b2, b3, b4, b5, |
每个模块有4个卷积层(不包括恒等映射的
加上第一个
因此,这种模型通常被称为ResNet-18。
通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。
虽然ResNet的主体架构跟GoogLeNet类似,但ResNet架构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用。
:numref:fig_resnet18描述了完整的ResNet-18。

:label:`fig_resnet18`
1 | X = torch.rand(size=(1, 1, 224, 224)) |
1 | Sequential output shape: torch.Size([1, 64, 56, 56]) |
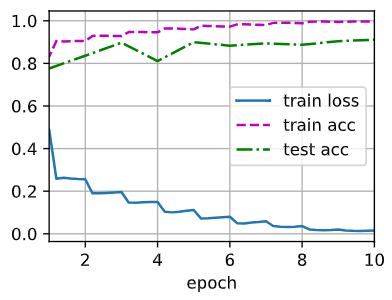
[训练模型]
同之前一样,我们在Fashion-MNIST数据集上训练ResNet。
1 | lr, num_epochs, batch_size = 0.05, 10, 256 |
1 | loss 0.140, train acc 0.949, test acc 0.867 |
- 学习嵌套函数(nested function)是训练神经网络的理想情况。在深层神经网络中,学习另一层作为恒等映射(identity function)较容易(尽管这是一个极端情况)。
- 残差映射可以更容易地学习同一函数,例如将权重层中的参数近似为零。
- 利用残差块(residual blocks)可以训练出一个有效的深层神经网络:输入可以通过层间的残余连接更快地向前传播。
- 残差网络(ResNet)对随后的深层神经网络设计产生了深远影响。
练习
- :numref:
fig_inception中的Inception块与残差块之间的主要区别是什么?在删除了Inception块中的一些路径之后,它们是如何相互关联的? - 参考ResNet论文 :cite:
He.Zhang.Ren.ea.2016中的表1,以实现不同的变体。 - 对于更深层次的网络,ResNet引入了“bottleneck”架构来降低模型复杂性。请试着去实现它。
- 在ResNet的后续版本中,作者将“卷积层、批量规范化层和激活层”架构更改为“批量规范化层、激活层和卷积层”架构。请尝试做这个改进。详见 :cite:
He.Zhang.Ren.ea.2016*1中的图1。 - 为什么即使函数类是嵌套的,我们仍然要限制增加函数的复杂性呢?
稠密连接网络(DenseNet)
ResNet极大地改变了如何参数化深层网络中函数的观点。
稠密连接网络(DenseNet) :cite:Huang.Liu.Van-Der-Maaten.ea.2017在某种程度上是ResNet的逻辑扩展。让我们先从数学上了解一下。
从ResNet到DenseNet
回想一下任意函数的泰勒展开式(Taylor expansion),它把这个函数分解成越来越高阶的项。在
同样,ResNet将函数展开为
也就是说,ResNet将
那么再向前拓展一步,如果我们想将
一种方案便是DenseNet。

:label:fig_densenet_blockResNet(左)与 DenseNet(右)在跨层连接上的主要区别:使用相加和使用连结。
如 :numref:fig_densenet_block所示,ResNet和DenseNet的关键区别在于,DenseNet输出是连接(用图中的
因此,在应用越来越复杂的函数序列后,我们执行从
最后,将这些展开式结合到多层感知机中,再次减少特征的数量。
实现起来非常简单:我们不需要添加术语,而是将它们连接起来。
DenseNet这个名字由变量之间的“稠密连接”而得来,最后一层与之前的所有层紧密相连。
稠密连接如 :numref:fig_densenet所示。

:label:fig_densenet
稠密网络主要由2部分构成:*稠密块(dense block)和*过渡层(transition layer)**。
前者定义如何连接输入和输出,而后者则控制通道数量,使其不会太复杂。
(稠密块体)
DenseNet使用了ResNet改良版的“批量规范化、激活和卷积”架构(参见 :numref:sec_resnet中的练习)。
我们首先实现一下这个架构。
1 | import torch |
一个稠密块由多个卷积块组成,每个卷积块使用相同数量的输出通道。
然而,在前向传播中,我们将每个卷积块的输入和输出在通道维上连结。
1 | class DenseBlock(nn.Module): |
在下面的例子中,我们[定义一个]有2个输出通道数为10的(DenseBlock)。
使用通道数为3的输入时,我们会得到通道数为
卷积块的通道数控制了输出通道数相对于输入通道数的增长,因此也被称为增长率(growth rate)。
1 | blk = DenseBlock(2, 3, 10) |
1 | torch.Size([4, 23, 8, 8]) |
[过渡层]
由于每个稠密块都会带来通道数的增加,使用过多则会过于复杂化模型。
而过渡层可以用来控制模型复杂度。
它通过
1 | def transition_block(input_channels, num_channels): |
对上一个例子中稠密块的输出[使用]通道数为10的[过渡层]。
此时输出的通道数减为10,高和宽均减半。
1 | blk = transition_block(23, 10) |
1 | torch.Size([4, 10, 4, 4]) |
[DenseNet模型]
我们来构造DenseNet模型。DenseNet首先使用同ResNet一样的单卷积层和最大汇聚层。
1 | b1 = nn.Sequential( |
接下来,类似于ResNet使用的4个残差块,DenseNet使用的是4个稠密块。
与ResNet类似,我们可以设置每个稠密块使用多少个卷积层。
这里我们设成4,从而与 :numref:sec_resnet的ResNet-18保持一致。
稠密块里的卷积层通道数(即增长率)设为32,所以每个稠密块将增加128个通道。
在每个模块之间,ResNet通过步幅为2的残差块减小高和宽,DenseNet则使用过渡层来减半高和宽,并减半通道数。
1 | # num_channels为当前的通道数 |
与ResNet类似,最后接上全局汇聚层和全连接层来输出结果。
1 | net = nn.Sequential( |
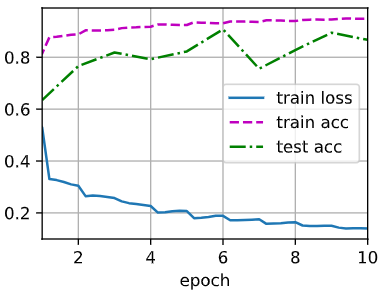
[训练模型]
由于这里使用了比较深的网络,本节里我们将输入高和宽从224降到96来简化计算。
1 | lr, num_epochs, batch_size = 0.1, 10, 256 |
- 在跨层连接上,不同于ResNet中将输入与输出相加,稠密连接网络(DenseNet)在通道维上连结输入与输出。
- DenseNet的主要构建模块是稠密块和过渡层。
- 在构建DenseNet时,我们需要通过添加过渡层来控制网络的维数,从而再次减少通道的数量。
练习
- 为什么我们在过渡层使用平均汇聚层而不是最大汇聚层?
- DenseNet的优点之一是其模型参数比ResNet小。为什么呢?
- DenseNet一个诟病的问题是内存或显存消耗过多。
- 真的是这样吗?可以把输入形状换成
,来看看实际的显存消耗。 - 有另一种方法来减少显存消耗吗?需要改变框架么?
- 真的是这样吗?可以把输入形状换成
- 实现DenseNet论文 :cite:
Huang.Liu.Van-Der-Maaten.ea.2017表1所示的不同DenseNet版本。 - 应用DenseNet的思想设计一个基于多层感知机的模型。将其应用于 :numref:
sec_kaggle_house中的房价预测任务。






